[Webinar] SpiraTest - Setting New Standards in Quality Assurance
Compiler Design Material 2
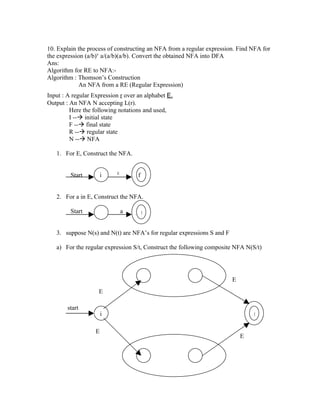
1. 10. Explain the process of constructing an NFA from a regular expression. Find NFA for
the expression (a/b)x a/(a/b)(a/b). Convert the obtained NFA into DFA
Ans:
Algorithm for RE to NFA:-
Algorithm : Thomson’s Construction
An NFA from a RE (Regular Expression)
Input : A regular Expression r over an alphabet E.
Output : An NFA N accepting L(r).
Here the following notations and used,
I -- initial state
F -- final state
R -- regular state
N -- NFA
1. For E, Construct the NFA.
E
Start i f
2. For a in E, Construct the NFA.
Start a f
3. suppose N(s) and N(t) are NFA’s for regular expressions S and F
a) For the regular expression S/t, Construct the following composite NFA N(S/t)
E
E
start
i f
E
E
2. b) For the regular expression St, Construct the Composite NFA N(st)
Diagram
c) For the regular expression S*, construct the Composite NFA N(S*)
Diagram
d) For the Parenthesized regular expression (S) , use N(s) itself as the NFA.
The Construction produces an NFA N® with the following properties.
1. N(r) has at most twice as many states as the number of symbols and operators in r.
2. N(r) has exactly one start state and one accepting state. The accepting state has no
out going transitions.
3. Each state of N(r) has either one out going transition on a symbol in E on at most
two out going E- transitions.
Diagram
11. What is a Shift-reduse Parser? Explain in detail the conflicts that may occur during
Shift-reduce Parsing?
Shift-reduse Parsing is a type of bottom up Parsing that Constraint a parse tree for
an input beginning at the leaves and working towards the root conflicts during shift-
reduce Parsing .
Conflicts during Shift-reduce Parsing
The general Shift-reduce technique.
3. • Perform shift action when there is no handle on the stack.
• Perform reduce action when there is a handle on the top of the stack.
There are two problems that this Parser faces.
1. Shift-reduce conflict:
What action to take in case both shift and reduce actions are valid?
2. Reduce-reduce conflict:
Which rule to use for reduction if reduction is possible by more one rule?
These conflicts come either because of ambiguous grammars or parsing method is not
powerful enough.
Examples:
1. Shift reduce conflict:
Consider the grammar E E + E/E * E/id and input id + id * id
Stack Input Action Stack Input Action
$E+E *id$ reduce by E E+E $E+E *id$ Shift
$E *id$ Shift $E+E* id$ Shift
$E* id$ Shift $E+E*id $ reduce by E id
$E*id $ reduce by E id $E+E*E $ reduce by E E*E
$E*E $ reduce by E E*E $E+E $ reduce by E E+E
2. Reduce-reduce Conflict:
Consider the grammar,
M R+R/R+C/R
R C
And input C+C
Stack Input Action Stack Input Action
$ C+C $ Shift $ C+C $ Shift
$C +C$ reduce by R C $ C+C $ reduce by R C
$R +C$ Shift $R +C $ Shift
$R+ C$ Shift $R +C $ Shift
$R+C $ reduce by R C $R+C $ reduce by M R+C
$R+R $ reduce by M R+R $M $
$M $
12. Explain Procedure calls with a suitable eg.
Procedure Calls:
• The procedure or function is such an important and frequently used programming
construct.
• It is imperative for a compiler to generate good code for procedure calls and
returns.
• The run time routine that handle procedure argument passing, calls and returns are
part of the run time support package.
4. • Let us consider a grammar for a simple Procedure call statement.
S call id(E list)
E E list, E
E list E
The translation for a call includes a calling sequence of actions taken on entry to and
exit from each procedure
Calling sequence:
While calling sequence differ, even for implementations of the same language.
• Allocate space for activation record (AR) on stack.
• Evaluate arguments to procedure and make available at known location.
• Save state of calling Procedure used to resume execution after call.
• Save return address (in known location)
• Generate jump to the beginning of the called Procedure.
Return sequences:
The full, actions will take place.
• If the called Procedure is a f2, save the result in a known place.
• Restore the activation record of the calling Procedure.
• Generate a jump to the return address(of calling Procedure)
Syntax Directed Translation Scheme of procedure call
1. S call id (E list) for each item P or queue do emit(‘Param’ P); emit(‘call’ id place)
The code for S , is th code for E list, Which evaluates the arguments, followed by
a param P statement for each argument, followed by a call Statement
2. E list E list , E append E place to end of queue
3. E list E initialize queue to contain only E place
Here queue is emptied and then gets a single pointer to the symbol table location
for the name that denotes the value of E.
1. Transition diagram for relational operators
Diagram
5. 2. Software tools:
* Structure editor
* Pretty printer
* Static checker
* Interpreters
- that analysis the source program
3. Disadvantage of operator precedence parsing
* It is hard to handle tokens like the minns sign which has two different
precedence (unary or binary)
* Only a small class of grammars can be parsed using this technique.
4. Methods of representing a syntax tree.
* Array representation
* Linked list representation
What are the issues of the lexical analyzer?
Lexical analysis Vs parsing
The reasons for separating lexical analysis from parsing are basically software
engineering concerns.
1. Simplicity of Design
When one detects a well defined sub task, it is often good to separate out the task for
eg a parser embedding the conventions for comments and white space is more complex
than one that assume comments and white space have already been removed by a lexical
analyzer
2. Efficiency
With the task separated, it is easier to apply specialized techniques for eg specialized
buffering techniques for reading input characters and processing tokens can significantly
speed up the performance of a compiler
3. Portability
Input alphabet peculiarities and other device specific anomalies can be restricted ti
the lexical analyzer. The representation of special or non standard symbols such as in
Pascal can be isolated in the lexical analysis.
1. Error recovery actions in a lexical analyzer:
* Panic mode recovery
* deleting an extraneous character
* Inserting a missing character
* Replacing incorrect character by a correct
* Transposing two adjacent characters.
2. What is basic block?
6. - Is a sequence of consecutive statements in which flow of control enters at the
beginning and leaves at the end without any halt or possibility of branching except at the
end.
3. Finite automata: The generalized transition diagram for RE is called finite automata.
Conversion of an NFA into a DFA
• An algorithm for constructing from an NFA into a DFA that recognizes the same
language is called the subset construction, it is useful for simulating an NFA by a
computer program.
Algorithm : Subset construction- constructing a DFA from an NFA.
Input : An NFA N
Output : A DFA D accepting the same language
Method : This algorithm constructs a transition table.
D transition for D. Each DFA state is a set of NFA states and we construct D tran
so that D will simulate “ in parallel” all possible moves N can make on a given input
string.
The following operations keep track of sets of NFA states (S represents an NFA
state and T a set of NFA states)
Operation Description
E- closure(S) Set of NFA states reachable from NFA
state S on E-Transitions alone
E- closure(T) Set of NFA states reachable from some
NFA state S in T on E-Transitions alone
Move (T, a) Set of NFA states to which there is a
transition on input symbol a from some
NFA state S in T
• The initial state of D is the set E-closure (S0), Where S0 is the start state of D we
assume each state of D is initially ‘unmarked’. Then perform the algorithm.
Initially E-closure(S0) is the only state in D states and it is unmarked! While there
is an unmarked state T in D states do begin
begin
mark T
for each input symbol a do
begin
U=E-closure (move (T , a ));
If U is not in D states then
add U as an unmarked state to D states;
D Tran [T , a ]=U
end
7. end [ The Subset Construction]
States and transitions are added to D using the subset construction algorithm.
A state of D is an accepting state if it is a set of NFA states containing at least one
accepting state of N.
A simple algorithm to complete E-closure(T) uses a stack to hold states whose
edges have not been checked for E-labeled transitions such a procedure is.
begin
push all states in T on to stack
initialize E-closure(T) to T
while stack is not empty do
begin
pop T, the top element, off of stack;
for each state w with an edge from T to W labeled E do
if w is not in E-closure (T) do
begin
add U to E-closure (T);
push W onto Stack
end
end
end [Computation of E-closure]
eg: Construct DFA for the following NFA
Diagram
NFA for (a/b) n* abb
Solution: The start state of the equivalent DFA is E-closure(0), which is
A = {0,1,2,4,7}
The input symbol alphabet is {a,b}
The subset construction algorithm tells us to mark A and then to compute E-closure
(move (A, a)).
We first compute move (A, a), the set of states of N having transitions on a from
members of A.
Among the states 0,1,2,4 and 7 only 2 and 7 have such transitions to 3 and 8.
So E-closure (move ({0, 1, 2, 4, 7}, a))
=E-closure ({3, 8})
={1,2,3,4,6,7,8}=>call this set as B
9. Dtran [E, b]=c
Since A is the start state and state E is the only accepting state (E contains, the find
state of NFA 10)
States I/P symbol
a b
A B C
B B D
C B C
D B E
*E B C
Transition Diagram (DFA)
Diagram
13. Explain in detail about the error recovery strategies in parsing.
Error-recovery Strategies:
A Parser uses the full, strategies to recover from a synthetic error.
* Panic mode
* Phrase level
* Error Productions
* Global connections.
1. Panic mode recovery
On discovering an error, the parser discards input symbols one at a time until one
of a designated set of synchronizing token is formed without checking for additional
errors.
Eg: for synchronizing tokens are delimiters such as; or end
2. Phrase level recovery
* On discovering an error, a Parser may perform local connection on the
remaining input.
* ie, it may replace a prefix of the remaining input by some string that allows the
parser to continue.
Eg: for local corrections are
- replace a comma by a semicolon
- delete a extra semicolon
- insert a missing semicolon
10. 3. Error Productions
* Parser can be constructed with the extended grammar so that we can generate
appropriate error diagnostic, to indicate the erroneous construct that has been recognized
in the input.
4. Global connections
* There are algorithms for choosing a minimal sequence of changes to obtain
global least cost connections.
* Given an incorrect input string x and grammar G,
* These algorithms will find a parse free for a related string y.
* Such that the number of insertions, deletiuons and changes of tokens required to
transform x into y is as small as possible
14. Regular Expressions:
* Each regular expression denotes a language. A language denoted by regular
expressions is called regular set.
* We use RE to describe tokens of a programming language.
* Token is either a single string or a collection of strings of a certain type.
* An identifier is defined to be a letter followed by zero or more letters & digits.
* In RE notation, it can be write as
identifier=letter (letter/digit)*
* ‘1’(Vertical bar) means ‘or’ ie, Union
‘(‘ ‘)’ used to group sub expressions
‘*’(closure operation) means zero or more instances.
Eg: Keyword = BEGIN|END|IF|THEN|ELSE
Constant = digit+
Relop = <|<=|=< >|>|>=
Identifier = letter(letter|digit)*
* Where letter stands for A|B|C|D………Z
Where digit stands for 0|2|3|…………..9
Suppose r and s REs denoting the language L® & L(s) then,
1. (r)|(s) is a RE denoting L(r)U/L(s)
2. (r)(s) is a RE denoting L(r) L(s)
3. (r)* is a RE denoting (L(r))*
4. (r) is a RE denoting L(r)
* The following table gives the algebric properties of RE,
Axion Description
r/s = s/r 1 is cumulative
r/(s/t)=(r/s)/t 1 is associative
r(s/t)=rs/rt
& concatenation distributes over
(s/t)r=sr/tr
11. er=r
re=r e is the identity element for concatenation
r* =(r/e)* relation between * and e
r** = r** r* is independent
15. Deterministic Finite Automata :( DFA)
* Finite automation is deterministic if,
1. It has no transitions on input E
2. For each state S and input symbol a, there is at most one edge labeled a leaving
S.
* DFAS are easier to simulate by a program than NFAs
* DFA can be exponentially larger than NFA[n states in a NFA controlled
require as many as 2n states in a DFA]
* A DFA can take only one path through the state grapg.
* Completely determined by input.
* It has one transition per input per state & has no E-moves.
* If we use a transition table to represent the transition function of DFA,
then each entry in the transition table is a single state.
* DFA accepting the same language (a/b)*abb
Diagram
* For DFA & NFA we can find accepting the same language.
* The states of the DFA represent subsets of the set of all states of the NFA. This
algorithm is often called the subset construction.
12. * NFA can be implemented using transition table, row for each state
column each input and E
state input symbol
a b
0 {0,1} {0}
1 - {2}
2 - {3}
* Advantage of TT:
it provides fast access to the transitions of a given state on a given character.
* Disadvantage:
It can take up lot of SPACE when input is large most transitions are to the empty
set.
* A path can be represented by sequence of state transitions called moves.
0 a 0 a 1 b 2 b 3
[accepting the input string aabb]
* NFA can have multiple transitions for one I/P ina given state & have E-moves
* NFA can choose whether to make E-moves and which of multiple trasition for a single
I/P to take.
* Actually NFAs do not have free will. If would be more accurate to say an execution of
an NFA marks ‘all’ choice from a set of states to a set of states.
* Acceptance of NFAs
An NFA can be ‘ in multiple states’
1
0 1
0
* Rule: NFA accepts if at least one of its current states is a final state.