Short instruction laba1
•
0 recomendaciones•346 vistas

Краткая инструкция к лабе 1 по курсу "Семиотика ИТ" (профиль - семиография).

Recomendados
Más contenido relacionado
Similar a Short instruction laba1
Similar a Short instruction laba1 (20)
Short instruction laba1
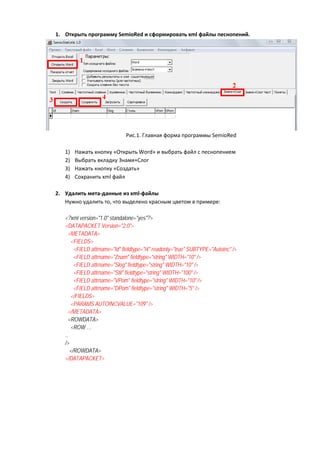
- 1. 1. Открыть программу SemioRed и сформировать xml файлы песнопений. Рис.1. Главная форма программы SemioRed 1) Нажать кнопку «Открыть Word» и выбрать файл с песнопением 2) Выбрать вкладку Знамя+Слог 3) Нажать кнопку «Создать» 4) Сохранить xml файл 2. Удалить мета-данные из xml-файлы Нужно удалить то, что выделено красным цветом в примере: <?xml version="1.0" standalone="yes"?> <DATAPACKET Version="2.0"> <METADATA> <FIELDS> <FIELD attrname="Id" fieldtype="i4" readonly="true" SUBTYPE="Autoinc" /> <FIELD attrname="Znam" fieldtype="string" WIDTH="10" /> <FIELD attrname="Slog" fieldtype="string" WIDTH="10" /> <FIELD attrname="Stil" fieldtype="string" WIDTH="100" /> <FIELD attrname="VPom" fieldtype="string" WIDTH="10" /> <FIELD attrname="DPom" fieldtype="string" WIDTH="5" /> </FIELDS> <PARAMS AUTOINCVALUE="109" /> </METADATA> <ROWDATA> <ROW … .. /> </ROWDATA> </DATAPACKET>
- 2. 3. Открыть программу Semantic_Statistik и построить частотные словники Рис.2. Главная форма программы Semantic_Statistik 1) Иногда xml-файлы содержат ошибки кодировки (недопустимые знаки и т.п.). Поэтому, прежде чем начать работу необходимо проверить исходный файл и пересохранить его ( кнопки 1 и 2 на рис.2) 2) Нажать на кнопку «Создать частотный словник» 3) В итоге будет создан документ в программе Word, содержащий частотную таблицу, пример которой показан ниже. В первом столбце записывается «код » знамени, во втором - знамя, в третьем – частоты. «код » знамени знамя частота 76 a 15 121 L 4 77 a 3 89 d 2 -74 A 2 88 d 1 166 b 1 140 Z 1
- 3. В дальнейшем нам потребуются столбцы, выделенные в примере серым цветом. 4. Открыть Excel – заготовку и найти закон распределения частот знамен Рис.3. Excel лист для поиска закона распределения 1) Заменить частотный словник (Столбцы A и B) 2) Проставить ранги знамен (если у знаменс одинаковой частотой один ранг)
- 4. ⎧ � 𝑦 𝑖 = 𝑁 ∗ 𝐶0 + � 𝑥 𝑖 ∗ 𝐶1 + � 𝑥 2 ∗ 𝐶2 3) Составить матрицу для решения системы уравнений: 𝑖 ⎪ � 𝑥 𝑖 𝑦 𝑖 = � 𝑥 𝑖 ∗ 𝐶0 + � 𝑥 2 ∗ 𝐶1 + � 𝑥 3 ∗ 𝐶2 ⎨ 𝑖 𝑖 ⎪� 𝑥 2 𝑦 = � 𝑥 2 ∗ 𝐶 + � 𝑥 3 ∗ 𝐶 + � 𝑥 4 ∗ 𝐶 ⎩ 𝑖 𝑖 𝑖 0 𝑖 1 𝑖 2 𝑦 𝑖 = ln(𝑁 𝑖 /𝑁), 𝑁 𝑖 − частота 𝑖 − го знамени ; 𝑁 − количество знамен в пеcнопении 𝑥 𝑖 = 𝑙𝑛𝑅 𝑖 𝑅 𝑖 − ранг 𝑖 − го знамени i(k,r)/k = p (r+v) –b 2 ∗ 𝐶2 𝑣= 𝐶1 𝑝 = 𝑒 𝐶0 +𝑏∗ln(1+𝑣) 𝑏 = −𝐶1 (1 + 𝑣) 4) Перейти на «Лист2» и найти коэффициенты 𝐶0 , 𝐶1 и 𝐶2 и параметры v, b и p закона Мандельброта: i(k,r) = pk (r+v) -b, где i(k,r) — частота слова в тексте, k — общее число слов в тексте, r — ранг слова 5) Проделать аналогичные вычисления для поиска параметров закона распределения Ципфа: i(k, r) = pk r-b. См. Лист 3 и 4.