2. Genome
Size of genome? Nuclear / organelle genome
DNA: coding, non-coding, repetitive DNA
Complexity of genes
Transposable elements
Multigenes
Pseudogenes
Regulatory sequences for Transcription?
Density of genes?
3. Genome organization
• Prokaryotes
– Most genome is coding
– Small amount of non-coding is regulatory
sequences
• Eukaryotes
– Most genome is non-coding (98%)
– Regulatory sequences
– Introns
– Repetitive DNA
5. Prokaryotic genome organization:
• Haploid circular genomes (0.5-10 Mbp, 500-
10000 genes)
• Operons: polycistronic transcription units
• Environment-specific genes on plasmids and
other types of mobile genetic elements
• Usually asexual reproduction, great variety of
recombination mechanisms
• Transcription and translation take place in the
same compartment
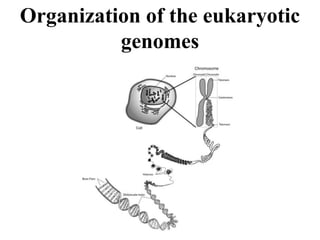
6. Eukaryotic genome
• Example: C. elegans
• 10 chromosomes
• 19,099 genes
• Coding region – 27%
• Average of 5 introns/gene
• Both long and short duplications
7. Eukaryotic genome organization
1. Multiple genomes: nuclear, plastid:
mitochondria, chloroplasts
2. Plastid genomes resemble prokaryotic
genomes
3. Multiple linear chromosomes, total size 5-
10,000 MB, 5000 to 50000 genes
4. Monocistronic transcription units
5. Discontinuous coding regions (introns and
exons)
8. Eukaryotic genome organization
(contd.)
6. Large amounts of non-coding DNA
7. Transcription and translation take place in
different compartments
8. Variety of RNAs: Coding (mRNA, rRNA,
tRNA), Non-coding (snRNA, snoRNA,
microRNAs, etc).
9. Often diploid genomes and obligatory sexual
reproduction
10.Standard mechanism of recombination:
meiosis
9. Hierarchy of gene organization
Gene – single unit of genetic function
Operon – genes transcribed in single transcript
Regulon – genes controlled by same
regulator
Modulon – genes modulated by
same stimilus
Element – plasmid, phage,
chromosome,
Genome
** order of ascending
complexity
10. Finding genes in eukaryotic DNA
Types of genes include
• protein-coding genes
• pseudogenes
• functional RNA genes: tRNA, rRNA and others
--snoRNA small nucleolar RNA
--snRNA small nuclear RNA
--miRNA microRNA
There are several kinds of exons:
-- noncoding
-- initial coding exons
-- internal exons
-- terminal exons
-- some single-exon genes are intronless
12. Human Mitochondrial Genome
Small (16.5 kb) circular DNA
rRNA, tRNA and protein encoding genes (37)
1 gene/0.45 kb
Very few repeats
No introns
93% coding;
Genes are transcribed as multimeric transcripts
Recombination not evident
Maternal inheritance
13. What are the mitochondrial genes?
• 24 of 37genes are RNA coding
– 22 mt tRNA
– 2 mit ribosomal RNA (23S, 16S)
• 13 of 37 genes are protein coding
(synthethized on ribosomes inside mitochondria)
some subunits of respiratory complexes and
oxidative phosphorylation enzymes
14. Two overlapping genes encoded by same
strand of mt DNA (ATPase 8/ ATPase 6)
(unique example)
Two independent AUG located in Frame-shift to each other,
second stop codon is derived from TA + A (from poly-A)
16. Human Nuclear Genome
3200 Mb
23 (XX) or 24 (XY) linear chromosomes
30,000 genes
1 gene/100kb
Introns in the most of the genes
1.5 % of DNA is coding
Genes are transcribed individually
Repetitive DNA sequences (45%)
Recombination at least once for each chrom.
Mendelian inheritance (X + auto), paternal (Y)
18. C value paradox:
why eukaryotic genome sizes vary
The haploid genome size of eukaryotes (called the C value)
varies enormously.
Small genomes include:
•Encephalotiozoon cuniculi (2.9 Mb)
•A variety of fungi (10-40 Mb)
•Takifugu rubripes (pufferfish) (365 Mb)(same number of genes as
other fish or as the human genome, but 1/10th
the size)
•Human 3200 Mb
Large genomes include:
•Pinus resinosa (Canadian red pine)(68 Gb)
•Protopterus aethiopicus (Marbled lungfish)(140 Gb)
•Amoeba dubia (amoeba)(690 Gb)
20. C value paradox:
why eukaryotic genome sizes vary
The range in C values does not correlate well
with the complexity of the organism. This
phenomenon is called the C value paradox.
Why?
21. Britten and Kohne (1968) identified
repetitive DNA classes
Reassociation Kinetics = isolated genomic DNA, Shear,
denature (melted), & measure the rates of DNA reassociation.
23. Tandem repeats
Tandem repeats occur in DNA when a pattern of two or more
nucleotides is repeated and the repetitions are adjacent to
each other
Form different density band on density gradient centrifugation
(from bulk DNA) -satellite
Example:
A-T-T-C-G-A-T-T-C-G-A-T-T-C-G
Tandem repeats:
– Satellite DNA:
– Microsatellite:
– Minisatellite:
24. Satellite DNA
• Unit - 5-300 bp depending on species.
• Repeat - 105
- 106
times.
• Location - Generally heterochromatic.
• Examples - Centromeric DNA, telomeric DNA.
There are at least 10 distinct human types of satellite
DNA.
25. Microsatellite DNA
• Unit - 2-4 bp (most 2).
• Repeat - on the order of 10-100 times.
• Location - Generally euchromatic.
• Examples - Most useful marker for population level
studies..
26. Minisatellite DNA
• Unit - 15-400 bp (average about 20).
• Repeat - Generally 20-50 times (1000-5000 bp
long).
• Location - Generally euchromatic.
• Examples - DNA fingerprints. Tandemly repeated
but often in dispersed clusters. Also called VNTR’s
(variable number tandem repeats).
27. Tandemly Repetitive DNA Can
Cause Diseases:
• Fragile X Syndrome
– “CGG” is repeated hundreds or even thousands of
times creating a “fragile” site on the X
chromosome.
– It leads to mental retardation.
• Huntington's Disease
– “CAG” repeat causes a protein to have long
stretches of the amino acid glutamine.
– Leads to a neurological disorder that results in
28. Interspersed Repetitive DNA
• Interspersed repetitive DNA accounts for 25–40
% of mammalian DNA.
• They are scattered randomly throughout the
genome.
• The units are 100 – 1000 base pairs long.
• Copies are similar but not identical to each other.
• Interspersed repetitive genes are not stably
integrated in the genome; they move from place
to place.
• They can sometimes mess up good genes
29. Interspersed Repetitive DNA
These are:
• Retrotransposons (class I transposable
elements) (copy and paste), copy themselves
to RNA and then back to DNA (using reverse
transcriptase) to integrate into the genome.
• Transposons (Class II TEs) (cut and paste)
uses transposases to make makes a staggered
sticky cut.
30. Interspersed Repetitive DNA
• Retrotransposons are:
long terminal repeat (LTR) Any transposon
flanked by Long Terminal Repeats. (also called
retrovirus-like elements). None are active in
humans, some are mobile in mice.
long interspersed nuclear elements (LINEs)
encodes RT and
short interspersed nuclear elements (SINEs)
uses RT from LINEs. example Alu made up of
350 base pairs long, recognized by the RE AluI
(Non-autonomous)
31. Long interspersed nuclear elements (LINEs )
20% of genome
• LINE1 – active
(Also many truncated inactive sequences)
• Line2 – inactive
• Line 3 – inactive
RNA binding also endonuclease
LINEs prefer AT-rich euchromatic bands
Internal
promoter
In everyone’s genome 60-100 copies of LINE1
are still capable of transposing,
and may occasionally cause the disease by gene disruption
32. Mechanism of LINE repeat jumps
Full length LINE transcript is generated from 5’-
UTR-based promoter
ORF1 and ORF2 translated into proteins that stay
bound to LINE mRNA
ORF1/ORF2/mRNA complex moves back into the
nucleus
5’ 3’
5’ 3’orf1
orf2
5’ 3’orf1
orf2
5’ 3’
3’ 5’
Product of ORF2
cut ds DNA
Freed 3’ serves as a primer for
LINE reverse transcription from 3’ UTR
33. ORF2 and ORF1 function
• ORF1 keeps ORF2 and LINE mRNA bound together and
retracted into nucleus
• ORF2 (endonuclease) cut dsDNA to provide free 3’ end as
a primer to LINE 3’UTR
• ORF2 (reverse transcriptase)
makes cDNA copy of LINE mRNA, which becomes
integrated into chromosomal DNA
(as it bound to it by former 3’ freed end)
TTTT A is ORF1 cleavage site,
that is why integration prefers AT rich regions
34. Short interspersed nuclear elements
(SINE) 13% of genome
• Non-autonomous (no RT)
• 100-400 bp long;
• No open reading frames (no start/stop codon)
• Derived from tRNA (transcribed with
RNA pol III, leaving internal promoter)
• Depend on LINE machinery for its movement
35. AluI - elements
• Derived from signal recognition particle
7SL
• Internal promoter is active, but require
appropriate flanking sequence for
activation
• Integrates in GC rich sequences
• Only active SINE in the human genome
36. Diseases caused by Alu-integration
• Neurofibromatosis (Shwann cell tumors),
• haemophilia,
• breast cancer,
• Apert syndrome (distortions of the head and face
and webbing of the hands and feet),
• cholinesterase deficiency (congenital myasthenic
syndrome)
• complement deficiency (hereditary angioedema)
• α-thalassaemia
• Several types of cancer, including Ewing sarcoma,
breast cancer, acute myelogenous leukaemia
37. Genes
• About 30,000 genes, not a particularly
large number compared to other species.
• Gene density varies along the
chromosomes: genes are mostly in
euchromatin,
• Most genes (90-95% probably) code for
proteins. However, there are a significant
number of RNA genes.
38. Gene families
A gene family is a group of genes that share
important characteristics. These may be
• Structural: have similar sequence of
DNA building blocks (nucleotides). Their
products (such as proteins) have a similar
structure or function.
• Functional: have proteins produced from
these genes work together as a unit or
participate in the same process
39. Gene families (structural)
1. Classical gene families (overall
conservativeness) Histones, alpha and beta-
globines
2. Gene families with large conservative
domains (other parts could be low
conservative) HLH/bZIP box transcription
factors
3. Gene families with short conservative
motifs e.g. DEAD box (Asp-Glu-Ala-Asp), WD (Trp-
Asp) repeat
40. Gene families (functional)
1 Regulatory protein gene families
2 Immune system proteins
3 Motor proteins
4 Signal transducing proteins
5 Transporters
6 Unclassified families
41. Multigene families
Some genes are Transcribed (But Don't Make Proteins)
• The entire family of genes probably evolved from a single
ancestral gene.
– Famous examples: rRNA, globin genes
– Four different pieces of rRNA are used to make up a
ribosome: 18S, 5.8S, 28S, and 5S.
– It turns out that three of these rRNAs (18S, 5.8S, 28S, )
occur in the genome as a gene (on chrom 13, 14, 15, 21,
22) & transcribed together. (one 5S on chrom. 1)
– The entire multigene family is repeated nearly 300
times in clusters on five different chromosomes!
• It makes sense to have many repeats of this multigene family
because each cell needs many ribosomes for protein synthesis
42. Multigene family: rRNA Genes
• RNA polymerase I synthesizes 45S
which matures into 28S, 18S and 5.8S
rRNAs
• RNA polymerase II synthesizes mRNAs
and most snRNA and microRNAs.
• RNA polymerase III synthesizes
tRNAs, rRNA 5S and other small RNAs
found in the nucleus and cytosol.
43. tRNA genes
(497 nuclear genes + 324 putative pseudogenes)
• Humans have fewer tRNA genes that the
worm (584), but more than the fly (284);
• Frog (Xenopus laevis) has thousands of tRNA
genes;
• Number of tRNA genes correlates with size of
the oocytes;
In large oocytes lots of protein needs to be
sythesized simultaneously.
45. Non-coding RNAs
• tRNA & rRNA
• 4.5S & 7S RNA (Signal Recognition Particles)
• snRNA – Pre-mRNA splicing
• snoRNA – rRNA modification
• siRNA – small interfering RNA
• gRNA – guide RNA in RNA editing
• Telomerase RNA – primer for telomeric DNA synthesis
• tmRNA is a hybrid molecule, half tRNA, half mRNA
• Xist: The X chromosome silencing is mediated by Xist – a 16,000 nt long
ncRNA
• shRNA (small heterochromatic RNAs ): expresses only one allele while
other is silenced
• LNA Locked Nucleic Acid
• piRNA Piwi-interacting RNA
46. Protein-coding Genes
• Genes vary greatly in size and organization.
• Intron less: Some genes don’t have any introns.
Most common example is the histone genes.
• Some genes are quite huge: dystrophin (associated
with Duchenne muscular dystrophy) is 2.4 Mbp and
takes 16 hours to transcribe. More than 99% of this
gene is intron (total of 79 introns).
• Highly expressed genes usually have short
introns
• Most exons are short: 200 bp on average. Intron
size varies widely, from tens to millions of base
pairs.
47. Pseudogenes
• Pseudogenes are defective copies of genes. They have lost
their protein-coding ability
–have stop codons in middle of gene
–they lack promoters, or
–truncated
–just fragments of genes.
–accumulation of multiple mutations
• Processed pseudogenes copied from mRNA and
incorporated into the chromosome but lack of protein-
coding ability (no intron/ poly-A tail present/ no promoter)
• Non-processed pseudogenes are the result of tandem
gene duplication or transposable element movement.
When a functional gene get duplicated, one copy isn’t
necessary for life.
50. Why so small amount of genes we,
humans, kings of nature, have?
Human 30,000 genes
Drosophila – 13,000
Nematode – 19,000
Potential of proteome and transcriptome diversity is so great
that it is no need for increase of amount of genes
51. 51
Solution 2 to the N-value paradox:
We are counting the wrong things, we should count otherWe are counting the wrong things, we should count other
genetic elements (e.g.,genetic elements (e.g., smallsmall RNAsRNAs).).
Solution 1 to the N-value paradox:
Many protein-encoding genes produce more than oneMany protein-encoding genes produce more than one
protein product (e.g., byprotein product (e.g., by alternative splicingalternative splicing or byor by RNARNA
editingediting).).
Solution 3 to the N-value paradox:
We should look atWe should look at connectivityconnectivity rather than atrather than at nodesnodes..
These should be exciting and should stimulate
the next generation of genomic investigation.
Solutions ?
53. The ENCODE project
(Encyclopedia of DNA Elements)
Goal of ENCODE: build a list of all sequence-
based functional elements in human DNA. This
includes:
► protein-coding genes
► non-protein-coding genes
► regulatory elements involved in the control of
gene transcription
► DNA sequences that mediate chromosomal
structure and dynamics.
54. 1977 first viral genome
(Sanger et. Al. bacteriophage fX174; 11 genes)
1981 Human mitochondrial genome
16,500 base pairs (encodes 13 proteins, 2 rRNA, 22 tRNA)
Today, over 400 mitochondrial genomes sequenced
1986 Chloroplast genome
156,000 base pairs (most are 120 kb to 200 kb)
1995 Haemophilus influenzae genome sequenced
1996 Saccharomyces cerevisiae (1st Euk. Genome)
and archaeal genome, Methanococcus jannaschii.
Chronology of genome sequencing projects
55. 1997 More bacteria and archaea
Escherichia coli 4.6 megabases, 4200 proteins (38% of unknown function)
1998 Nematode Caenorhabditis elegans (1st
multicellular org.)
97 Mb; 19,000 genes.
1999 first human chromosome: Chrom 22 (49 Mb, 673 genes)
2000 Drosophila melanogaster (13,000 genes);
Plant Arabidopsis thaliana & Human chromosome 21
2001: draft sequence of the human genome
(public consortium and Celera Genomics)
Chronology of genome sequencing projects
57. First microbial genome was completely sequenced in
1995 by The Institute for Genomic Research (TIGR)
Fleishmann, R.D. et al. 1995. Science 269:496-512.
Genome of
Haemophilus
influenzae Rd
single circular
chromosome 1,860,137
bp
Outer circle – coding
sequences with
database matches
40% of genes at the
time had no match in
the databases
58. Some more statistics
• Gene density 1/100 kb (vary widely);
• Averagely 9 exons per gene
• 363 exons in titin (molecular spring for elasticity of muscle) gene
• Many genes are intronsless
• Largest intron is 800 kb (WWOX gene)
• Smallest introns – 10 bp
• Average 5’ UTR 0.2-0.3 kb
• Average 3’ UTR 0.77 kb
• Largest protein: titin: 38,138 aa
59. INTRONLESS GENES
• Interferon genes
• Histone genes
• Many ribonuclease genes
• Heat shock protein genes
• Many G-protein coupled receptors
• Some genes with HMG boxes
• Various neurotransmitters receptors and hormone
receptors