Mongo learning series
•
3 recomendaciones•1,900 vistas

Mongo DB Course Notes a series of 6
![Week 1: Introduction
What is MongoDB?
MongoDB is a non relational data store for JSON (Java Script Object Notation) documents. MongoDB is
document oriented.
Example JSON:
{“name”:”Prashanth”}
{“a”:1, “b”:2, “c”:3}
JSON document sample with hierarchy:
{“a”:6,
“b”:7,
Fruit: [“apple”,”pear”,”mango”]}
JSON documents are stored with in MongoDB, what differentiates between relational and MongoDB is
the way the document is structured and stored in a way you would use in an application in contrast to
tables
MongoDB is schema less. (Dynamic Schema)
You can save {“a”:1, “b”:2} and {“a”:1, “b”:2, “c”:3} in the same collection
MongoDB relative to relational
MongoDB does not support joins
MongoDB does not support transactions across multiple documents
You can access items in a collection atomicly. Since data is hierarchical, something which requires
multiple updates with in a relational system can be handled with in a single atomic transaction within a
single document.
Overview of building an app with MongoDB
MongoD process is the database server
Mongo process is the Mongo shell
Python was the language used in this class to build the app (Note there are other courses which uses
other languages)
Bottle framework – A lightweight WSGI (Web Server Gateway Interface) micro web framework for
python was used to host the application
http://bottlepy.org/docs/dev/index.html](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Destacado
Destacado (16)
Similar a Mongo learning series
Similar a Mongo learning series (20)
Más de Prashanth Panduranga
Más de Prashanth Panduranga (20)
Último
Último (20)
Mongo learning series
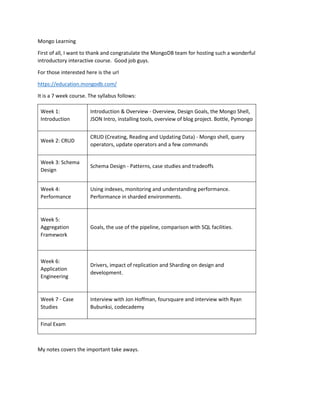
- 1. Mongo Learning First of all, I want to thank and congratulate the MongoDB team for hosting such a wonderful introductory interactive course. Good job guys. For those interested here is the url https://education.mongodb.com/ It is a 7 week course. The syllabus follows: Week 1: Introduction Introduction & Overview - Overview, Design Goals, the Mongo Shell, JSON Intro, installing tools, overview of blog project. Bottle, Pymongo Week 2: CRUD CRUD (Creating, Reading and Updating Data) - Mongo shell, query operators, update operators and a few commands Week 3: Schema Design Schema Design - Patterns, case studies and tradeoffs Week 4: Performance Using indexes, monitoring and understanding performance. Performance in sharded environments. Week 5: Aggregation Framework Goals, the use of the pipeline, comparison with SQL facilities. Week 6: Application Engineering Drivers, impact of replication and Sharding on design and development. Week 7 - Case Studies Interview with Jon Hoffman, foursquare and interview with Ryan Bubunksi, codecademy Final Exam My notes covers the important take aways.
- 2. Week 1: Introduction What is MongoDB? MongoDB is a non relational data store for JSON (Java Script Object Notation) documents. MongoDB is document oriented. Example JSON: {“name”:”Prashanth”} {“a”:1, “b”:2, “c”:3} JSON document sample with hierarchy: {“a”:6, “b”:7, Fruit: [“apple”,”pear”,”mango”]} JSON documents are stored with in MongoDB, what differentiates between relational and MongoDB is the way the document is structured and stored in a way you would use in an application in contrast to tables MongoDB is schema less. (Dynamic Schema) You can save {“a”:1, “b”:2} and {“a”:1, “b”:2, “c”:3} in the same collection MongoDB relative to relational MongoDB does not support joins MongoDB does not support transactions across multiple documents You can access items in a collection atomicly. Since data is hierarchical, something which requires multiple updates with in a relational system can be handled with in a single atomic transaction within a single document. Overview of building an app with MongoDB MongoD process is the database server Mongo process is the Mongo shell Python was the language used in this class to build the app (Note there are other courses which uses other languages) Bottle framework – A lightweight WSGI (Web Server Gateway Interface) micro web framework for python was used to host the application http://bottlepy.org/docs/dev/index.html
- 3. https://www.python.org/ Quick Introduction to Mongo Shell use test test is the name of a db you can use the command show dbs to list all the dbs you can use the command show collections to list all the collections within a db when you do a find the json document is printed on the shell based on the query parameters passed. You can make the document look pretty by using the pretty command db.things.find().pretty() pretty display as below Introduction to JSON chapters covers a little more on JSON format Installing MongoDB, Installing Bottle and Python, and Installing PyMongo covers the installation instructions for Mac and Windows PyMongo is the Mongo driver The documentation for the API for the MongoDB drivers is available at http://api.mongodb.org/
- 4. Hello World, Mongo style import pymongo from pymongo import MongoClient # connect to database connection = MongoClient('localhost', 27017) db = connection.test # handle to names collection names = db.names item = names.find_one() print item['name'] An example of doing the same from the Javascript in the shell is shown in the fig below An insight in to the save method
- 5. If there isn’t an object Id it creates one, if there is one then it updates the document Hello World on a Web Server Hello.py import bottle import pymongo # this is the handler for the default path of the web server @bottle.route('/') def index(): # connect to mongoDB connection = pymongo.MongoClient('localhost', 27017) # attach to test database db = connection.test # get handle for names collection
- 6. name = db.names # find a single document item = name.find_one() return '<b>Hello %s!</b>' % item['name'] bottle.run(host='localhost', port=8082) Mongo is Schemaless In MongoDB, since the data is not stored in tables there is no need for operations such as alter table as and when the need to store more related data changes. In real world there might be scenarios where the data attributes is different for different items in the entities. For example company data. [Company A] might have an office in a different country and hence need to store a whole lot of additional details, while all other companies in the data base might not have offices in multiple countries. In the JSON documents this can be added only to [Company A], as long as there is a way to retrieve that information from the document, these attributes need not be entered in to other documents with empty data The week is then followed by deep dive in to JSON Arrays, Dictionaries, Sub Documents, and JSON Spec www.json.org Introduction to class project : Building a Blog site Blog comparison with respect to relational
- 7. While in comparison all of the above entities will be in one single JSON document Introduction to Schema Design To Embed or not to Embed: Looking at the posts collection in the JSON document, lets say we have tags and comments array. We can decide to keep them in separate documents, however the rule of thumb if the data is typically accessed together then we should put them together In MongoDB Documents cannot be more than 16MB If the document size will end up being more than 16MB then split the data in to multiple documents The chapters that follow includes chapters on Python, which I am not covering in detail in the blog because I want to concentrate on Mongo mostly Python Introduction Lists Slice Operator Inclusion Dicts Dicts and Lists together
- 8. For loops While loops Function Calls Exception handling Bottle Framework URL Handlers Views Handling form Content PyMongo Exception Processing import sys import pymongo connection = pymongo.MongoClient("mongodb://localhost") db = connection.test users = db.users doc = {'firstname':'Andrew', 'lastname':'Erlichson'} print doc print "about to insert the document" try: users.insert(doc) except: print "insert failed:", sys.exc_info()[0] doc = {'firstname':'Andrew', 'lastname':'Erlichson'} print doc print "inserting again" try: users.insert(doc) except: print "second insert failed:", sys.exc_info()[0] print doc
- 9. Week 2 : CRUD CRUD Operations Mongo SQL Create Insert Insert Read Find Select Update Update Update Delete Remove Delete MongoDB does not use a separate query language Secrets of the Mongo Shell Mongo Shell is an interactive java script interpreter The Mongo shell is designed to be similar to the bash shell. The key strokes are modeled after the emacs editor. Up arrow brings the previous command Ctrl A goes to first of the line, can also use the home key Ctrl e or Use the end key to the end of the line Can also move around through the arrow keys or bash customary ctrl f, ctrl b Type in help provides a list of topics to view BSON Introduced BSON stands for Binary JSON, is a serialization format designed to represent a super set of what can be transcribed in JSON format MongoDB uses a binary representation to store the data in the database http://bsonspec.org/ Insert Docs Db is a variable with a handle on the database Collections as properties of the database doc= {“name”:”smith”, “age”:30,”profession”:”hacker”} db.people.insert(doc) – inserts the doc in to the database db.people.find() – gets back all the documents in the people collection “_id” – an object ID, when an document is inserted in to the database, every document needs a unique indentifier, _id is used for the same
- 10. _id is the primary key field, It is required to be present and the value in it is required to be unique, it is immutable. To change the value the document will have to be removed and added back with a different value, which would not be an atomic operation _id : ObjectId (“50843730cb4cf4564b4671ce”) Object Id is generated taken in to account the current time, identifier of the machine which is constructing the object , process Id of the process that is constructing the object id, a counter that is global to the process db.people.insert({“name”:”smith”, “age”:30,”profession”:”hacker”}) Introduction to findOne() findOne methods get one document out of random from the document collection findOne first argument is a match criteria, analogous to the where clause Second argument is to specify what fields to get from the database If “_Id”:false is not explicitly stated then by default _id is always displayed Introduction to find First argument is where clause db.scores.find({type:”essay”}) db.scores.find({student:19}) db.scores.find({type:”essay”,student:19}) – means that both the conditions have to match. Second argument identifies the fields to get from the database Querying using $gt, $lt Db.scores.find({score: { $gt: 95}}) – will find score greater than 95
- 11. Db.scores.find({score: { $gt: 95,$lte: 98 }}) – will find score greater than 95 and less than or equal to 98 Inequalities on strings The inequality operations $gt, $lt can also be applied to strings db.people.find({name:{$lt:”D”}}) find the records which are lexicographically lesser than “D” are sorted according to the total order of UTF 8 code units, lexicographically sorting of the bytes UTF 8 representation MongoDB compares and sorts in an asciibetically correct fashion All comparison operations in MongoDB are strongly typed and dynamically typed too In the above figure, there is a document which has a number 42 for a name, please note that the query does not return that document in the result set Using regex, exists, type db.people.find({profession:{$exists:true} } ) will find the documents which has the field profession
- 12. db.people.find({profession:{$exists:false} } ) – return all documents in which the profession does not exist db.people.find({name:{$type:2} } ) – type is represented as a number as specified in the specs – string being 2, this query will result in all documents which has name values of type string patterns in string Mongo supports PCRE (Perl Compatabile Regular Expression)library db.people.find({name:{$regex:”a”} } ) – return the list of documents which has letter “a” in the name db.people.find({name:{$regex:”e$”} } ) – return the list of documents which ends with letter “e” in the name db.people.find({name:{$regex:”^A”} } ) – return the list of documents which starts with letter “A” in the name Using $or Grouping multiple documents together with a logical connective Union of some documents Find documents which names ended with an e or had a age db.people.find({$or:[{name:{$regex:”e$”}},{age:{$exists:true}} ] } ) $or is a prefix operator Using $and Logical conjunction Find only the documents which sorts after c and contains the letter “a” in it db.people.find({ $and: [ { name:{$gt: “C”}}, {name:{$regex: “a” }} ] })
- 13. not used heavily because, there are simpler ways to query the same - db.people.find ({ name:{ $gt: “C”, $regex: “a” }} ) will have the same result Querying inside arrays Query all documents that has the favorite as pretzels Example: db.accounts.find({favorites: “pretzels” }) The querying is polymorphic, in the above example if the document had a field called favorites, which wasn’t an array it would check the value of the same for pretzels, and if the favorties happened top be an array as is in the above figure it looks at the elements of the array to find the value pretzels in the array Using $in and $all Query for more than one value in an array, say pretzels and beer in the above example db.accounts.find({favorites: { $all: [“pretzels”,”beer”] }) $in operator db.accounts.find({name: { $in: [“Howard, “John””] } }) Dot Notation Querying nested documents
- 14. The find query searches for the document byte by byte and performs an exact match search. When searching for subdocuments if you want to query as db.users.find({“email”: {“work”:richard@10gen.com,”personal”:kreuter@example.com}) you will find the document, however if the sub document is reversed db.users.find({“email”:”personal”:kreuter@example.com, {“work”:richard@10gen.com}) the result set will not find any document Also, subsets of the sud document will not be abel to find a result db.users.find({“email”:”personal”:kreuter@example.com) will not find any document db.users.find({“email. work”:richard@10gen.com}) Querying Cursors When you are using an interactive shell such as Mongo and you are executing a command such as db.people.find() in the background a cursor is being constructed and returned in the shell. Shell is configured to print out cursor by iterating through all of the elements that are retrieved from the cursor and printing out those elements cur = db.people.find(); null; null; Cursor object has a variety of methods hasNext methods returns true if there is another document to visit on this cursor next() method returns the next document while (cur.hasNext()) printjson(cur.next()); -- prints out all the documents in the cursor cur.limit(5) – imposes a limit of 5 records to iterate through cur.sort( { name : -1 } ) – returns the sorted records in a lexicographically sorted in reverse for the name field The sort and limit are NOT processed in memory, rather it is processed in the database engine. cur.sort( { name : -1 } ).skip(2) – skips 2 records and return the rest
- 15. Counting results db.scores.count ( { type : ”exam” } ) – gives the count of the result set Wholesale updating of a document db.people.update ( { name:”smith” } , { “name” : ”Thompson” , “salary”: 50000 } ) – the first arguments acts as a where clause and the second argument the value to be replaced Update is however a replacement method where in if you wanted to add one value, you will have to know all the other values and then add the new value. using the $set command db.people.update ( { name:”smith” } , { $set : { “age”: 50 } } ) The above command will look to see if there is already a field called age, if so update the value to 50 else, it will create a field called age and store the value 50 against it. If we wanted to increment a value then we can use a operator called $inc db.people.update ( { name:”smith” } , { $inc : { “age”: 1 } } ) Which in the above command will increment the age of smith by 1, $inc also sets the value if the field does not exist. For example if in the above sample smith did not have an age field in the document, the age will be set to the increment value, in this case 1 Using the $unset command To remove a particular field from the document, you could use the update field have all the fields in the update command except the field that need to be removed, but is obviously very cumbersome. db.people.update ( { name:”smith” } , { $unset : { “age”: 1 } } ) The above command will remove the age field from the document with the name smith Using $push, $pull, $pop, $pushAll, $pullAll, $addToSet These operations are used to modify the arrays in a document Lets use the following document as an example: { “_id”: 0, “a”: [ 1 , 2 , 3 , 4 ] } db.arrays.update ( { _id : 0 } , { $set : {“a.2”: 5 } } ) will modify the third element in the array to 5 { “_id”: 0, “a”: [ 1 , 2 , 5 , 4 ] }
- 16. To add an item in to the arry db.arrays.update ( { _id : 0 } , { $push : {a: 6 } } ) will add 6 to the array { “_id”: 0, “a”: [ 1 , 2 , 5 , 4 , 6] } db.arrays.update ( { _id : 0 } , { $pop : {a: 1 } } ) will remove the right most element of the array { “_id”: 0, “a”: [ 1 , 2 , 5 , 4 ] } db.arrays.update ( { _id : 0 } , { $pop : {a: -1 } } ) specifying negative 1 will remove the left most element of the array { “_id”: 0, “a”: [ 2 , 5 , 4 ] } db.arrays.update ( { _id : 0 } , { $pushAll : {a: [7,8,9] } } ) adds all of the numbers to the specified array { “_id”: 0, “a”: [ 2 , 5 , 4 ,7,8,9 ] } db.arrays.update ( { _id : 0 } , { $pull : {a: 5 } } ) will remove the specified value from the array { “_id”: 0, “a”: [ 2 , 4 , 7 , 8 , 9 ] } db.arrays.update ( { _id : 0 } , { $pullAll : {a: [2, 4, 8 ] } } ) will remove all the specified values from the array { “_id”: 0, “a”: [7 , 9 ] } db.arrays.update ( { _id : 0 } , { $addToSet : {a: 5 } } ) will add values to the array by checking if it already exists in the array, if it does then it does nothing. Use addToSet if you want to ensure that duplicates aren’t stored in the array { “_id”: 0, “a”: [ 5 , 7 , 9 ] } Upserts db.people.update({name:”George”}, {$set :{age: 40} } , {upsert: true} )
- 17. This command checks to see if there exists a record matching the criteria and updates that record and if that matching criteria doesn’t exist it creates a new document with the given criteria Multi-Update db.people.update({}, {$set :{title: “Dr”} } , {multi: true} ) The update can be effectively applied to multiple documents that match a particular criteria. If the update has to be applied to all the documents , then the first argument can be {}. The above statement will be applied to every document in the collection. Please note that the statement multi:true is very important. If that is not provided then only the first document matching the criteria will be updated Default behavior in contrast with SQL is to update only one document matching the criteria, unless the second argument multi to true is set. Inside of mongodb there is a single thread for each operation that is executed. The multi update operation will happen sequentially in a single thread. However, every write operation that effects more than one document is carefully coded in a cooperative multi-tasking fashion to occasionally yield control to allow other operations to affect the same data set. Lets say we had 10 documents in the collection, above multi update operation could update 3 documents, pause and let other operations, update another 5 documents pause and then complete all the updates. It is a mutex lock. The concurrency consequences of this is that write operation even if they effect multiple documents are NOT isolated transactions. MongoDB guarantees individual document update is always atomic with respect to any concurrent reads or writes Removing Data Deleting documents from the collection. db.people.remove( {name:”Alice”} ) The first argument is analogous to the where/find clause to find the document to remove, if nothing is provided, the command removes all the documents in the collection. The above command removes the document with the name Alice db.people.remove( {name: {$gt: “M” } } ) Documents with names like William or Thompson whose name falls in the given category are deleted db.people.remove( ) removes all documents db.people.drop () removes all the documents. Drop is much faster. Remove requires a one by one update of an internal state for each document that was part of the collection. Drop includes freeing up much larger data
- 18. structure inside of the databases data file. However, collections can have some meta data in them for instance indexes, which gets discarded when the collection gets dropped, but remains when the documents are removed. Remove command are not atomic isolated transaction with respect to other readers or writers. getLastError _id is a primary key, immutable and unique. db.people.insert( {name:”Alice”} ), if this command is run twice via the shell, on the second run the shell will give an duplicate key error message given that the name Alice doesn’t exist in the database the first time around. getLastError return the outcome of the last write operation that that sent on the connection that is currently being used. db.runCommand ( {getLastError : 1 } ) getLastError is available in the shell and in the drivers. getLastError although called error writes the status of the previously run command, even if it was successful. 1 in the above diagram returned an error after running an insert with the same _id twice. 2 in the above diagram ran a successful insert and hence, n=0 3 in the above diagram ran an update successfully with a the details of the update in the getLastError command, please note the n=2, which means that because multi = true was given the update was done on 2 documents. This command is also particularly useful in the upsert scenario
- 19. In the above diagram, you can see that the update was not performed on existing document, rather created a new document. In a nut shell the command clarifies whether the last performed operation succeeded or failed. The chapters that follow includes chapters on PyMongo, using Pymongo to find, find_one, cursors, field selection, $gt, $lt, regex, Dot Notation, Sort, Skip, Limit, Inserting, Updating, Upserts, find_and_modify
- 20. Week 3 : MongoDB Schema design Although we could keep the data in Third normal form, MongoDB recommends to store data close to the application in an Application driven schema. Key principles : 1. Rich documents 2. Pre/Join Embed data 3. No Merge Joins 4. No Constraints 5. Atomic operations 6. No declared Schema Relational Normalization: Goals of relational normalization 1. Free the database of modification anomalies 2. Minimize redesign when extending 3. Avoid bias toward any particular access pattern MongoDB does not consider the 3rd goal in its design.
- 21. Alternate schema for blog If you are doing it the same way as relational, then you are doing it incorrectly Living without constraints MongoDB does not provide a way to check the foreign key constraints. It is up to the programners to ensure that if the data is stored in multiple documents the link between the two are well maintained.
- 22. Embedding usually helps with the same. Living without transactions MongoDB does not support transactions. However, MongoDB has Atomic operations. When you work on a single document that work will be completed before anyone sees the document. They will see all the changes that you make or none of them. Since the data is prejoined that updated is made on one document instead of initiating a transaction and updates across multiple tables in relational 3 considerations 1. Restructure data to be contained within a document update 2. Implement in application code vs on the database layer 3. Tolerance to inconsistency One to One relations One to one relations are relations where each item corresponds to exactly one other item Example: Employee: Resume Building: Floor plan Patient: Medical History Taking the employee resume example. You could have an employee document and a resume document, which you link by adding employee ID in the resume document, or the other way round and have the resume ID in the employee document. Or alternatively have one employee document and embed the resume in to the document/have a resume document and embed the employee details Key considerations are: 1. Frequency of access Let’s say for example, the employee details are constantly accessed, but very rarely access their resume, let’s say if it is a very large collection and are concerned about locality and working set size, you may decide to keep them in separate collections because you don’t want to pull the resume in to memory every single time you pull the employee record 2. Size of the items Which of the items grow. For example, the employee details might not change as much, however the resume is changing. If there are items especially around multimedia which has the potential to grow over 16MB, then you will have to store them separately. 3. Atomicity of Data If you want to make sure that the data is consistent between the employee data and resume data, and you want to update the employee data and the resume data all at the same time, then you will have to embed the data to maintain the atomicity
- 23. One to Many relationships Are relations where many entities map to one entity. Example: City: Person Let’s say NYC which has 8 million people. If we have a city collection, with attributes like name of the city, area and people in an array, that wont work. Because there are way too many people If we flip that around, and have a people collection and embed the city attributes as part of each people document, that wont work either because there will be lot of people in a given city and the city data will become redundant. The City data has been duplicated The best way to do it is to use linking It makes sense to have 2 collections in this case. One to Few Example: Posts: Comments Allthough the relation is one to many the number of comments might just be a few and it would be ok Many to Many Example: Books:Authors Students: Teachers It might end of being few to few
- 24. Makes most sense to keep them as separate collections, unless there are performance issues. Not recommended to embed the data, there will be risk of duplicating data Multi Key Indexes When you index something that’s an array, you get a multi key index Students collection {_id: 0, “name”: “ Prashanth Panduranga”, “teachers” : [1,4,7] } Where teachers is an array of the teachers db.students.ensureIndex ( {‘teachers’:1 } ) The above query returns all students which have teachers 1 and 3 and the explain plan indicates that the query used the index Benefits of embedding data Improved read performance Nature of computer systems: Spinning disks have high latency, which means take a long time to get to the first byte. Once they get to the first byte, each additional byte comes quickly. High bandwidth One round trip to the DB Trees
- 25. One of the classic problem in the world of schema design is How to represent trees, example product catalog in an ecommerce site such as amazon Products – products collection Category : 7 Product_name : “Snow blower” Category – category collection _id: 7 Category_name: “Outdoors” One way to model it is it by keeping the parent id Parent: 6 But this doesn’t make it easy to find the parents of this category, you will have to iteratively query find the parent of each all the way to the top Alternatively You can list all the children Children: [1,2,5,6] Which is also fairly limiting if you are intending to locate the entire sub tree, above certain piece of the tree Alternate: Ancestor: [3,7,9,6] List all the ancestors in order, with this we can find all the parent categories of the category easily When to Denormalize One of the reasons Data is normalized is to avoid modification anomalies As long as we don’t duplicate data we don’t open ourselves to modification anomalies 1:1 embed – perfectly safe to embed the data, because you are not opening up to modification anomalies, you are not duplicating data, rather what would be in separate tables you are folding it in to one document 1:Many – as long as you are embedding many to the one, it would still avoid duplicating data. Many: Many – link to avoid duplication
- 26. Handling Blobs GRIDFS If you want to store large files, you are limited by 16 MB. Mongo DB has a special facility called GRIDFS, which will break up a large file in to smaller chunks and store those chunks in a collection and will also store meta data about these chunks in a secondary collection. Running the python file, saves the video file in to the collection and adds the meta data
- 27. Week 4: Performance Indexes Database performance is driven by indexes for MongoDB as any other database Databases stores the data in large files on disk, which represents the collection. There is no particular order for the documents on the disk, it could be anywhere. When you query for a particular document, what the database will have to do by default is scan through the entire collection to find the data. This is called a table scan in a relational DB and a collection scan in Mongo DB and it is death to performance. It will be extremely slow. Instead the data is indexed to perform better. How does indexing work: If something is ordered/sorted then it is quick to find the data. MongoDB keeps the key ordered. MongoDB does not keep the keys linearly ordered, but uses BTree. When looking for the items, look for the key in the index which has a pointer to the document and thus retrieve the document. In MongoDB indexes are ordered list of keys Example: (name, Hair_Color, DOB) Inorder to utilize an index, you have give it a left most set of items As in provide: name or name and hair color
- 28. than just DOB Every time a data needs to be inserted in to the database the index also needs to be updated. Updating takes time. Reads are faster, however the writes takes longer when you have an index. Lets say we have an index on (a,b,c) If a query is done on b, index cannot be used If a query is done on a, index can be used If a query is done on c, index cannot be used If a query is done on a,b: index can be used, it uses 2 parts of the index If a query is done on a,c: index can be used, it uses just the a part and ignores the c part Creating Indexes db.students.ensureIndex({student_id:1}) db.students.ensureIndex({student_id:1,class:-1}) – Compound index Negative indicates descending. Ascending vs descending doesn’t not make a big difference when you are searching, however makes a huge difference when you are sorting. If the database use the index for the sort then it needs to be in the right order. You can also makes it 3 part index. Discovering Indexes db.system.indexes.find() – will give all the indexes in the database. db.students.getIndexes()– will give all the indexes in the given collections. db.students.dropIndex( {Student_id:1}) - will delete/drop the index MultiKey Indexes In MongoDB you can hold a key which is an array tags: [“cycling”,”tennis”,”football”] ensureIndex ({tags:1}) When you index an key which is an Array, A MultiKey Index is created. Rather than create one index point for a document, while creating an index if MongoDB sees an array, it will create an index point for every item in the array. MongoDB also lets to create a compound index with arrays.
- 29. Mongo restricts having 2 keys to be arrays and being indexed at the same time. Compound index on 2 arrays is restricted. Indexes are not restricted to the top level alone. Index can be created on sub areas of the document as well For example. db.people.ensureIndex({‘addresses.tag’:1})
- 30. db.people.ensureIndex({‘addresses.phones’:1}) Index creation Option, Unique Unique index enforces a constraint that each key can only appear once in the index db.stuff.ensureIndex ( {‘thing’:1}, {unique:true} ) Removing duplicates when creating unique indexes db.stuff.ensureIndex ( {‘thing’:1}, {unique:true, dropDups:true} ) Adding dropDups will delete all duplicates. There is no control on the document to be deleted, hence it is important to exercise caution before using this command Index creation Option, Sparse When and index is created on a collection and more than one document in the collection is missing a key {a:1, b:1, c:1} {a:2, b:2} {a:3, b:3} If an index is created on c First document has c in it and hence ok, for the second document mongo considers c to be null and the third document also does not has c and hence null. Since c is null and unique is specified this cannot be allowed In scenarios where duplicates cannot be dropped, there is a unique problem
- 31. Querying documents in the collection with sparse index will not change the result set However, sorting on collections with sparse index results in result set which ignores the document with out the index sparse keys Indexes can be created foreground or on the back ground. Default : foreground. When the index is created in the foreground it blocks all writers Foreground indexes are faster While running indexes with background:true option, it will be slow but does not block writers In production systems when there are other writers to the database and doesn’t use replica sets, creating indexes as background tasks is mandatory so that the other writers are not blocked. Using Explain Important query metrics such as , Index usage pattern, execution speed, number of scanned documents etc. can be identified by using the explain command Explain details: { "cursor" : "<Cursor Type and Index>", "isMultiKey" : <Boolean – if the index is of a multikey type>, "n" : <num of documents returned>,
- 32. "nscannedObjects" : <number of scanned documents , the number of scanned documents depends on the index>, "nscanned" : <number of index entires or scanned documents>, "nscannedObjectsAllPlans" : <num>, "nscannedAllPlans" : <num>, "scanAndOrder" : <boolean>, "indexOnly" : <Boolean – whether or not the database query can be satisfied by the index itself>, "nYields" : <num>, "nChunkSkips" : <num>, "millis" : <num>, "indexBounds" : { <index bounds that the query uses to look up the index> }, "allPlans" : [ { "cursor" : "<Cursor Type and Index>", "n" : <num>, "nscannedObjects" : <num>, "nscanned" : <num>, "indexBounds" : { <index bounds> } }, ... ], "oldPlan" : { "cursor" : "<Cursor Type and Index>", "indexBounds" : { <index bounds> } } "server" : "<host:port>", "filterSet" : <boolean> }
- 33. Choosing an Index How does MongoDB choose an Index Lets say, the collection has an index on a, b and c We will call that query plan 1 for a, 2 for b, and 3 for c When we run the query for the first time, Mongo runs all the three query plans 1, 2 and 3 in parallel. Lets say, query plan 2 was the fastest and completed processing, mongo will return the answer to the query and memorize that it should use that index for similar queries. Every 100 odd queries it will forget what it knows and rerun the experiment to know which one performs better. How Large is your index Index should be in memory. If index is not in memory and is on disk and if we are using all of it, it will impact the performance severely. .totalIndexSize() command gives the size of the index
- 34. Index Cardinality Cardinality is a measure of the number of elements of a set How many index points for each different type of index that MongoDB supports In a regular index, every single key you put in an index there will be an index point, and in addition if there is no key there will be an index point under the null entry, so you get 1:1 relative to the documents In Sparse index, when a document is missing the key being indexed it is not in the index. Because it is a null, and nulls are not kept in the index for Sparse index. So here, Index cardinality will be potentially less than or equal to the number of documents In Multikey Index, an index on array value there will be multiple index points for each document. And hence, the cardinality will be more than the number of documents. Index Selectivity Being selective on indexes are very important, which is no difference to RDBMS Lets see an example of Logging with operation codes (OpCodes) such as Save, Open, Run, Put, Get If can have an index on lets say (timestamp, OpCodes) or the reverse (Opcodes, timestamp) If you know the particular time when you are interested to see what happened then (timestamp, OpCodes) makes the most sense, while the reverse could have had millions of records on a certain operation. Hinting an Index Generally, MongoDB uses its own algorithm to choose an index, however if you wanted to tell MongoDB to use an particular index you can do so by using the hint command
- 35. Hint({a:1,b:1}) If you want MongoDB to not use an index and use a cursor that goes through all the documents in the collection, then you can use the natural Hint({$natural:1}) Hinting in Pymongo example Efficiency of Index Use Searching on regexes which are like /abcd/ with out stemming, comparison operators such as $gt, $ne etc are very inefficient even with indexes In which cases based on the knowledge of the collection you can hint for the appropriate index to use rather than the default index used by Mongo
- 36. Geo Spatial indexes Allows you to find things based on location 2D and 3D 2D: cartisian plan (x and y coordinates) You want to know what closest stores to the person. In order search based on location, you will need to store ‘location’: [x,y] Index the locations ensureIndex({‘location’:’2d’,type:1}) while querying then you can use find({location:{$near:[x,y]}}).limit(20) Database will return the documents in order of increasing distance. Geospatial Sperical Geo Spatial indexes considers the curvature of the earth. In the database the order for the x and y coordinates are longitude and latitude Db.runCommand( { geoNear: ‘stores’, near:[50,50], spherical:true, maxDistance :1}) The stores is the collection It is queried with the run command instead of the find command
- 37. Logging slow queries MongoDB automatically logs queries which are slow, > 100 ms. Profiling Profile writes entries/documents to system .profile which are slow (specified time) There are three levels for the profiler 0, 1 and 2 0 default means off 1 log slow running queries 2 log all queries – more for debugging rather than performance db.system.profile.find().pretty() db.getProfilingLevel() db.getProfilingStatus() db.setProfilingLevel(1,4) 1 sets it to log slow running queries and 4 sets it to 4 milliseconds Write the query to look in the system profile collection for all queries that took longer than one second, ordered by timestamp descending. db.system.profile.find({millis:{$gt:1000}}).sort({ts:-1})
- 38. Mongostat Mongostat named after iostat from the unix world, similar to perfmon in windows Mongotop Named after the Unix Top command. It indicates or provides a high level view of where Mongo is spending its time.
- 39. Sharding Sharding is the technique splitting up a large collection amongst multiple servers Mongos lets you shard The way Mongo shards is that you choose a shard key, lets say student_id is the shard key. As a developer you need to know that, for inserts you will also need to send the shard key, the entire shard key if it is a multi parted shard key in order for the insert to complete. For an update or a remove or a find, if MongoS is not given a shard key then it will have to broadcast the request to all the shards. If you know the shard key, passing the shard key will increase the performance of the queries MongoS is usually co-located with the application and you can have more than one MongoS How to get all the keys of a document var message = db.messages.findOne(); for (var key in message) { print(key); }
- 40. Week 5: Aggregation Framework The aggregation pipeline is a framework for performing aggregation tasks, modeled on the concept of data processing pipelines. Using this framework, MongoDB passes the documents of a single collection through a pipeline Let’s say there is a table Name Category Manufacturer Price iPad Tablet Apple 499 S4 Cell Phone Samsung 350 If I wanted to find out how many products from each manufacturer from each manufacturer, the way it is done in SQL is through a query : Select manufacturer, count(*) from products group by manufacturer We need to use Mongo aggregation framework to use similar to “group by“ use agg db.products.aggregate([ {$group: { _id:”$manufacturer”,num_products:{$sum:1} }}]) Aggregation pipeline Aggregation uses a pipeline in MongoDB. The concept of pipes is similar to unix. At the top is the collections. The documents are piped through the processing pipeline and they go through series of stages and will eventually get a result set. Each of the stage can happen multiple times.
- 41. Unwind denormalizes the data. For an array the command unwind will create a separate document for each key in the array with all other data being repeated in the document, thus creating redundant data. In the above diagram 1:1 maps to same number of records N:1 maps to only a subset of records returned 1:N represents a larger set of records returns due to unwind operation Simple aggregation example expanded If the above aggregation query, is run against a product collection, it goes through each record looks for the manufacturer, if doesn’t exist, creates a record and adds the num_products value.
- 42. At the end of the iteration, a list of all the unique manufacturers and their respective number of products will be produced as a result set Compound grouping For compound grouping where traditionally we use queries such as Select manufacturer, category, count(*) from products group by manufacturer, category The below example groups by manufacturer and category Using a document for _id _id doesn’t always have to be a number or a string, the important aspect is that is has to be unique. It can also be a document.
- 43. Aggregate Expressions The following are the different aggregation expressions 1. $sum – count and sum up the key 2. $avg - average 3. $min – minimum value of the key 4. $max – maximum value 5. $push – build arrays 6. $addToSet – add to set only adds uniquely 7. $first – after sorting the document produces the first document 8. $last – after sorting the document produces the last document Using $sum Using $avg
- 44. Using addToSet Using $push Difference between push and addToSet is that push doesn’t check for duplicates and it just adds the same. . addToSet adds by checking for duplicates Using Max and min
- 45. Double Grouping You can run more than one aggregation statement Example: Using $project
- 46. Project example use agg db.products.aggregate([ {$project: { _id:0, 'maker': {$toLower:"$manufacturer"}, 'details': {'category': "$category", 'price' : {"$multiply":["$price",10]} }, 'item':'$name' } } ]) use agg db.zips.aggregate([{$project:{_id:0, city:{$toLower:"$city"}, pop:1, state:1, zip:"$_id"}}]) Using $match use agg db.zips.aggregate([ {$match: { state:"NY" } }, {$group: {
- 47. _id: "$city", population: {$sum:"$pop"}, zip_codes: {$addToSet: "$_id"} } }, {$project: { _id: 0, city: "$_id", population: 1, zip_codes:1 } } ]) use agg db.zips.aggregate([ {$match: { state:"NY" } }, {$group: { _id: "$city", population: {$sum:"$pop"}, zip_codes: {$addToSet: "$_id"} } } ]) Using $sort Sort happens in memory and hence can hog memory If the sort is before grouping and after match, it can use index If the sort is after grouping it cannot use index use agg db.zips.aggregate([ {$match: { state:"NY" } }, {$group: { _id: "$city", population: {$sum:"$pop"},
- 48. } }, {$project: { _id: 0, city: "$_id", population: 1, } }, {$sort: { population:-1 } } ]) $limit and $skip use agg db.zips.aggregate([ {$match: { state:"NY" } }, {$group: { _id: "$city", population: {$sum:"$pop"}, } }, {$project: { _id: 0, city: "$_id", population: 1, } }, {$sort: { population:-1 } }, {$skip: 10}, {$limit: 5} ])
- 49. Using $unwind db.posts.aggregate([ /* unwind by tags */ {"$unwind":"$tags"}, /* now group by tags, counting each tag */ {"$group": {"_id":"$tags", "count":{$sum:1} } }, /* sort by popularity */ {"$sort":{"count":-1}}, /* show me the top 10 */ {"$limit": 10}, /* change the name of _id to be tag */ {"$project": {_id:0, 'tag':'$_id', 'count' : 1 } } ]) db.posts.aggregate([{"$unwind":"$comments"},{$group:{"_id":{"author":"$comments.author"},count:{" $sum":1} }}, {$sort:
- 50. { count:-1 } } {$limit: 1} ]) Some examples: Avg score homework 5.3 db.grades.aggregate([ {$unwind:'$scores'},{$match:{'scores.type':{$in:['exam','homework']}}},{$group:{_id: {"studentId":'$student_id',"classId":"$class_id"},Avgscore:{$avg:'$scores.score'}}},{$group: {_id:"$_id.classId","Avgclassscore":{"$avg":"$Avgscore"}}}, {$sort: { Avgclassscore:-1 } } ]) SQL to Aggregation Mapping http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
- 51. Limitations to aggregation framework 1. The result set is limited to 16MB of memory 2. You cannot use more than 10% of memory on a machine 3. Sharding: Aggregation does work on a sharded environment, but after the first $group or $sort phase, the aggregation has to be brought back to the MongoS
- 52. Alternates of aggregation framework 1. MapReduce 2. Hadoop
- 53. Week 6: Application Engineering Mongo Application Engineering 1. Durability of Writes 2. Availability / Fault Tolerance 3. Scaling WriteConcern Traditionally when we insert/update records that operation is performed as a fire and forget, Mongo Shell however wants to know if the operation is successful and hence calls getLastError every single time. There are couple of arguments for (getLastError) with which the operations can be perfomed W: 1 - - wait for a write acknowledgement. Still not durable, if the changes were made in memory returns true. Not necessarily after it is written to disk. If the system fails before writing to disk the data will be lost. J:1 -- journal. Return only acknowledgement on disk write and is guaranteed. The operation can be replayed if lost. Api.mongodb.org
- 54. Network Errors Although w=1, j =1 is set there are other factors which might not save the state complete. Lets say you did an insert, that insert was done using a connection which had j=1, w=1. The driver issues a get last error. The write did get complete, but unfortunately before it completed, the network connection got reset. In that case, you will not know if the write completed or not. Because you did not get an acknowledgement that it completed. Replication: ReplicaSets: Replica sets are the set of mongo nodes. All nodes act together and mirror each other. One primary and multiple secondary. Data written to primary is asynchronously replicated. The decision of which is primary is dynamic. The application and its drivers always connects to the primary. If the primary goes down, then the secondary performs a election on which one needs to be a primary and there should be a strict majority. The minimum number of nodes to form a replica set is 3. Types of Replica Sets: 1. Regular 2. Arbiter (Voting) 3. Delayed / Regular (Disaster recovery node – It cannot be a primary node) 4. Hidden (Often used for Analytics, cannot be a primary node) MongoDB does not offer eventual consistency by default. It offers write consistency. As in the primary configuration for the MongoDB is to write and the read from the primary. If we change the read from secondary there might be some discrepancies. Failover usually about 3 seconds
- 55. rs.slaveOk() rs.isMaster() seedlist rs.stepDown() w:’majority’ rs.status() rs.conf() rs.help() Read Preference: the default read is from the primary, but when you have lot of nodes and if you want to configure to read from secondary as well you set the read preference. The read preferences are set on the drivers (Pymongo has 4, there are others in other drivers) List of Read preferences allowed: 1. Primary 2. Secondary 3. Primary Preferred 4. Secondary preferred 5. Nearest 6. Tagged
- 56. Sharding There can be more than one mongos The shard can be arranged as rangebased The data is identified by the shard key
- 57. Shard help Sh.help() Implications of sharding on development 1. Every document includes the Shard key 2. Shard key is immutable, which means that it cannot be changed so need to be careful 3. Index that starts with the Shard Key 4. When you do an update Shard key has to be specified or set multi to true a. When multi it is going to send the updates to all of the nodes 5. No shard key means send to all nodes => scatter gather 6. No unique key unless part of the shard key Choosing a shard key 1. Sufficient cardinality 2. Hot spotting : monotonically increasing Import mongoimport --db dbName --collection collectionName --file fileName.json doc=db.thinks.findOne(); for (key in doc) print(key);
- 58. Week 7: Case Studies Jon Hoffman from Foursquare Scala, MongoDB 5 million check-ins a day Over 2.5 billion AWS is used as a Application Server The Database is hosted on own racks, SSD based Migrated from AWS due to some performance issues, which were in the past. AWS has fixed those with the SSD offering Ryan Bubinski from Codecademy Ruby for server side Javascript for client side and some server side API in Ruby App layer in Ruby and Javascript All client side is javascript Mongoid ODM (Object document mapper) Rails for application layer Rack api nginx 10Gen MMS Cookiebased session storage Redis session store (inmemory session store – key value based) Millions of submisssions The submissions vary from 100 of kilo bytes to MBs 1st gen O(I million) order of magnitude of 1 million Hosted service 2nd Gen O(10 million) Ec2 Quad extra large memory instances
- 59. EBS 4X large memory Provisioned IOPS Replica sets Single primary 2 secondary Writes to primary Reads from secondary To handle horizontal scale on the read load and use one machine to handle the write load Sharded temporarily: 2 shards with replica sets 3rd gen O(100+ millions) S3 backed answer storage Used S3 as a key value store writeConcern For all writes which involves a confirmation or user acknowledgement use safe mode For logging and other event based writes disable safe mode Rsync for replication Heroku Application layer and API layer handles both reads and writes are hosted on Heroku Heroku are AWS backed Both Codeacademy and Heroku (AWS) are hosted in the same availability zone