Entropía y código de Huffman del mismo texto en diferentes idiomas.
•Descargar como DOCX, PDF•
0 recomendaciones•2,401 vistas

Como obtener el diccionario de Huffman del mismo texto en diferentes idiomas.

Recomendados
Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Destacado
Destacado (15)
Similar a Entropía y código de Huffman del mismo texto en diferentes idiomas.
Similar a Entropía y código de Huffman del mismo texto en diferentes idiomas. (18)
Último
Último (20)
Entropía y código de Huffman del mismo texto en diferentes idiomas.
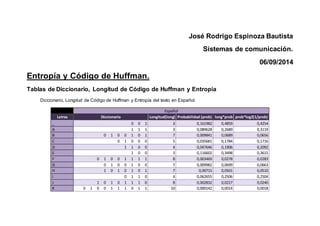
- 1. José Rodrigo Espinoza Bautista Sistemas de comunicación. 06/09/2014 Entropía y Código de Huffman. Tablas de Diccionario, Longitud de Código de Huffman y Entropía Diccionario, Longitud de Código de Huffman y Entropía del texto en Español. Español Letras Diccionario Longitud(long) Probabilidad (prob) long*prob prob*log2(1/prob) _ 0 0 1 3 0,161982 0,4859 0,4254 A 1 1 1 3 0,089628 0,2689 0,3119 B 0 1 0 0 1 0 1 7 0,009841 0,0689 0,0656 C 0 1 0 0 0 5 0,035681 0,1784 0,1716 D 1 1 0 0 4 0,047646 0,1906 0,2092 E 1 0 0 3 0,116602 0,3498 0,3615 F 0 1 0 0 1 1 1 1 8 0,003469 0,0278 0,0283 G 0 1 0 0 1 0 0 7 0,009982 0,0699 0,0663 H 1 0 1 0 1 0 1 7 0,00715 0,0501 0,0510 I 0 1 1 0 4 0,062655 0,2506 0,2504 J 1 0 1 0 1 1 1 0 8 0,002832 0,0227 0,0240 K 0 1 0 0 1 1 1 0 1 1 10 0,000142 0,0014 0,0018
- 2. L 0 0 0 0 1 5 0,037805 0,1890 0,1786 M 1 1 0 1 0 5 0,023434 0,1172 0,1269 N 0 1 1 1 4 0,06131 0,2452 0,2469 Ñ 0 1 0 0 1 1 1 0 1 0 10 0,001558 0,0156 0,0145 O 0 0 0 1 4 0,080142 0,3206 0,2918 P 1 1 0 1 1 5 0,02315 0,1158 0,1258 Q 1 0 1 0 1 0 0 7 0,007292 0,0510 0,0518 R 1 0 1 1 4 0,055504 0,2220 0,2315 S 0 1 0 1 4 0,067257 0,2690 0,2619 T 0 0 0 0 0 5 0,044673 0,2234 0,2003 U 1 0 1 0 0 5 0,03115 0,1558 0,1559 V 0 1 0 0 1 1 0 7 0,007363 0,0515 0,0522 W 0 0 0,0000 0,0000 X 0 1 0 0 1 1 1 0 0 9 0,002124 0,0191 0,0189 Y 1 0 1 0 1 1 0 7 0,00708 0,0496 0,0506 Z 1 0 1 0 1 1 1 1 8 0,002549 0,0204 0,0220 Σ= 1 4,0300 3,9966 Diccionario, Longitud de Código de Huffman y Entropía del texto en Inglés. Inglés Letras Diccionario Longitud(long) Probabilidad (prob) long*prob prob*log2(1/prob) _ 0 0 0 3 0,163228 0,4897 0,4268 A 0 0 1 1 4 0,070965 0,2839 0,2709 B 1 0 1 0 1 1 6 0,01198 0,0719 0,0765 C 1 0 1 0 0 5 0,027787 0,1389 0,1436
- 3. D 1 0 0 0 0 5 0,034526 0,1726 0,1677 E 1 1 0 3 0,09817 0,2945 0,3287 F 0 1 0 0 1 0 6 0,01797 0,1078 0,1042 G 0 1 0 0 1 1 6 0,016805 0,1008 0,0991 H 0 1 0 0 0 5 0,035691 0,1785 0,1716 I 0 1 0 1 4 0,066306 0,2652 0,2596 J 1 0 1 0 1 0 1 1 0 9 0,001664 0,0150 0,0154 K 1 0 1 0 1 0 1 0 0 9 0,002745 0,0247 0,0234 L 1 0 0 0 1 5 0,02787 0,1394 0,1440 M 1 1 1 0 1 5 0,023794 0,1190 0,1283 N 0 1 1 1 4 0,063977 0,2559 0,2538 O 0 1 1 0 4 0,065474 0,2619 0,2575 P 1 1 1 1 1 5 0,019218 0,0961 0,1096 Q 1 0 1 0 1 0 1 1 1 0 10 0,000832 0,0083 0,0085 R 1 0 0 1 4 0,056656 0,2266 0,2346 S 1 0 1 1 4 0,053245 0,2130 0,2253 T 0 0 1 0 4 0,083527 0,3341 0,2992 U 1 1 1 0 0 5 0,025874 0,1294 0,1364 V 1 0 1 0 1 0 0 7 0,007903 0,0553 0,0552 W 1 1 1 1 0 1 6 0,009734 0,0584 0,0650 X 1 0 1 0 1 0 1 0 1 9 0,001913 0,0172 0,0173 Y 1 1 1 1 0 0 6 0,011398 0,0684 0,0736 Z 1 0 1 0 1 0 1 1 1 1 10 0,000749 0,0075 0,0078 Σ= 1 4,1339 4,1034
- 4. Diccionario, Longitud de Código de Huffman y Entropía del texto en Alemán. Alemán Letras Diccionario Longitud(long) Probabilidad (prob) long*prob prob*log2(1/prob) _ 0 1 0 3 0,140836 0,4225 0,3983 A 1 1 0 1 4 0,047206 0,1888 0,2079 B 1 0 0 0 0 0 6 0,016022 0,0961 0,0956 C 0 0 0 0 1 0 6 0,023759 0,1426 0,1282 D 0 0 0 0 0 5 0,044861 0,2243 0,2009 E 0 0 1 3 0,146542 0,4396 0,4060 F 1 0 0 0 0 1 6 0,015553 0,0933 0,0934 G 1 0 0 1 0 5 0,028449 0,1422 0,1461 H 0 0 0 1 1 5 0,033138 0,1657 0,1629 I 0 1 1 0 4 0,069402 0,2776 0,2671 J 0 0 0 1 0 0 1 0 1 1 10 0,001094 0,0109 0,0108 K 1 1 0 0 0 0 0 7 0,00805 0,0564 0,0560 L 1 0 0 1 1 5 0,027667 0,1383 0,1432 M 0 0 0 0 1 1 6 0,020868 0,1252 0,1165 N 1 1 1 3 0,091129 0,2734 0,3149 O 1 1 0 0 1 5 0,023759 0,1188 0,1282 P 0 0 0 1 0 1 1 7 0,009066 0,0635 0,0615 Q 1 1 0 0 0 0 1 1 1 1 0 11 0,000156 0,0017 0,0020 R 0 1 1 1 4 0,067136 0,2685 0,2616 S 1 0 1 1 4 0,052989 0,2120 0,2246 T 1 0 1 0 4 0,054318 0,2173 0,2283 U 1 0 0 0 1 5 0,031262 0,1563 0,1563
- 5. V 1 1 0 0 0 1 6 0,011958 0,0717 0,0764 W 0 0 0 1 0 0 0 7 0,010004 0,0700 0,0665 X 1 1 0 0 0 0 1 1 1 0 10 0,001016 0,0102 0,0101 Y 1 1 0 0 0 0 1 1 0 9 0,001876 0,0169 0,0170 Z 0 0 0 1 0 1 0 7 0,009222 0,0646 0,0623 Á 1 1 0 0 0 0 1 1 1 1 1 11 0,000078 0,0009 0,0011 Ä 1 1 0 0 0 0 1 0 8 0,003908 0,0313 0,0313 Ö 0 0 0 1 0 0 1 0 0 9 0,002657 0,0239 0,0227 Ü 0 0 0 1 0 0 1 1 8 0,004846 0,0388 0,0373 ß 0 0 0 1 0 0 1 0 1 0 10 0,001173 0,0117 0,0114 Σ= 1 4,1750 4,1462 Al realizar la realizar la comparación de la entropía y la longitud promedio del código de Huffman de los tres textos, obtenemos los siguientes resultados: Texto Entropía Longitud Codigo Huffman Español 3,9966 4,0300 Inglés 4,1034 4,1339 Alemán 4,1462 4,1750
- 6. Con lo cual observamos que la relación entre la entropía y el numero promedio de bits necesarios para codificar el texto cumplen con la siguiente relacion. 퐻(푥) ≤ 퐿(푥) ≤ 퐻(푥) + 1 푛 Como se observa en la siguiente tabla: Texto H(x) L(x) H(x)+(1/n) Español 3,9966 4,0300 4,0333 Inglés 4,1034 4,1339 4,1404 Alemán 4,1462 4,1750 4,1774 Descripción del proceso para la obtención del código de Huffman. Para encontrar el código de Huffman se emplearon las funciónes de Matlab llamada huffmandict() y huffmanenco() la función huffmandict() nos permite crear el diccionario con código de Huffman para los símbolos (symbols) y la probabilidades (p) dadas por los textos de la tarea previa, también se utiliza la función huffmanenco() la cual utiliza el diccionario (dict) creado por la función anterior y reemplaza los símbolos (symbols) por la nueva combinación de códigos (comp). La función avglen también se utiliza para el cálculo del promedio de bits necesarios para la codificación del texto. Se emplearon estas funciones de la siguiente manera en Matlab: Para el texto 1 (Español):
- 7. Durante la programación se cambiaron las letras por números para simplificar el programa, además de no presentar ninguna afectación a resultado de este. Como se muestra en las siguientes figuras, se obtiene el texto codificado, el diccionario y el promedio de bits. Este método se realizó para los otros dos idiomas para lo cual solo se cambiaron el número de caracteres y la probabilidad de ellos. Para el texto 2 (Inglés):
- 8. Obteniendo los siguientes resultados: Para el texto 3 (Alemán): Se modifican el número de símbolos a 32 ya que el Alemán tiene más caracteres que el Inglés y el Español.
- 9. Los resultados para este texto son: Resultados obtenidos Una vez concluido el análisis se puede observar que la igualdad:
- 10. 퐻(푥) ≤ 퐿(푥) ≤ 퐻(푥) + 1 푛 se satisface, lo cual nos indica que los cálculos realizados y obtenidos por medio de Matlab son los correctos. También se puede observar que cuando se aplica la codificación de Huffman la información enviada tiende a simplificarse ya que se asignan cadenas de ceros y unos de diferentes longitudes en vez de que todos los caracteres sean identificados por cadenas de la misma cantidad de caracteres. Se observa que nuevamente que la longitud de caracteres en los códigos de Huffman, así como la Entropia depende directamente de la probabilidad de aparición de los símbolos y no de cuantos caracteres existan en el alfabeto. Esto se observa de manera más sencilla en el Idioma Aleman ya que aun y cuando posee una cantidad mayor de caracteres, su promedio de Bits no es muy diferente al del idioma Español e Inglés que cuentan con menor número de símbolos en su alfabeto.