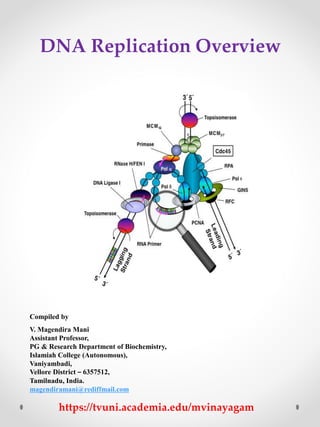
Overview of dna replication (prokaryotic & eukaryotic)
1. DNA Replication Overview
Compiled by
V. Magendira Mani
Assistant Professor,
PG & Research Department of Biochemistry,
Islamiah College (Autonomous),
Vaniyambadi,
Vellore District – 6357512,
Tamilnadu, India.
magendiramani@rediffmail.com
https://tvuni.academia.edu/mvinayagam
2. Structure of DNA
DNA, or deoxyribonucleic acid, is the hereditary
material in humans and almost all other organisms.
Nearly every cell in a person’s body has the same DNA.
Most DNA is located in the cell nucleus (where it is
called nuclear DNA), but a small amount of DNA can
also be found in the mitochondria (where it is
called mitochondrial DNA or mtDNA). DNA is found in
the nucleus of eukaryotes and the cytoplasm or nucleoid
of prokaryotes and functions as the molecule of heredity.
In DNA there are four bases: adenine (abbreviated A),
guanine (G), thymine (T) and cytosine (C). Adenine and
guanine are purines; thymine and cytosine are
pyrimidines.
3. A nucleoside is a pyrimidine or purine base covalently
bonded to a sugar. In DNA, the sugar is deoxyribose and
so this is a deoxynucleoside. There are four types of
deoxynucleoside in DNA; deoxyadenosine,
deoxyguanosine, deoxythymidine and deoxycytidine.
A nucleotide is base + sugar + phosphate covalently
bonded together. In DNA, where the sugar is deoxyribose,
this unit is a deoxynucleotide.
In DNA the nucleotides are covalently joined together by
3’-- 5’ phosphodiester bonds to form a repetitive sugar–
phosphate chain which is the backbone to which the bases
are attached.
4. The DNA sequence is the sequence of A, C, G and T along the
DNA molecule which carries the genetic information.
In a DNA double helix, the two strands of DNA are wound
round each other with the bases on the inside and the sugar–
phosphate backbones on the outside. The two DNA chains are
held together by hydrogen bonds between pairs of bases;
adenine (A) always pairs with thymine (T) and guanine (G)
always pairs with cytosine (C).
Each nucleotide consists of three major parts: (1) a five-carbon
sugar (pentose); (2) a flat, heterocyclic, nitrogen-containing
organic base; and (3) a negatively charged phosphate group,
which gives the polymer its acidic property. The nitrogenous
base in each nucleotide is covalently attached to the sugar by a
glycosidic bond. The phosphate group is also covalently
linked to the sugar.
5. Bases in the nucleotides spontaneously form hydrogen bonds in
a highly specific manner. Adenine normally forms two
hydrogen bonds with thymine in a complementary strand of
the DNA double helix like, Guanine forms three hydrogen
bonds with cytosine.
Human DNA consists of about 3 billion bases, and more than 99
percent of those bases are the same in all people.
Nucleotides are arranged in two long strands that form a spiral
called a double helix. The structure of the double helix is
somewhat like a ladder, with the base pairs forming the ladder’s
rungs and the sugar and phosphate molecules forming the
vertical sidepieces of the ladder.
6. An important property of DNA is that it can replicate,
or make copies of itself. Each strand of DNA in the
double helix can serve as a pattern for duplicating the
sequence of bases. This is critical when cells divide
because each new cell needs to have an exact copy of
the DNA present in the old cell.
Watson and Crick model of DNA
DNA is a double stranded helix, with the two strands
connected by hydrogen bonds. Adenine bases are
always paired with thymine, and cytosine is always
paired with guanine, which is consistent with and
accounts for Chargaff's rule. This is called
complementary base pairing. Watson and Crick
discovered that DNA had two sides, or strands, and
that these strands were twisted together like a twisted
ladder the double helix.
7. Most DNA double helices are right handed, only one type
of DNA, called ZDNA, is left handed.
The G:C and A:T base pairing also maximizes the number
of effective hydrogen bonds that can form between the
bases; there are three hydrogen bonds between each G:C
base pair and two hydrogen bonds between each A:T base
pair. Thus A:T and G:C base pairs form the most stable
conformation both from steric considerations and from the
point of view of maximizing hydrogen bond formation.
The sides of the ladder comprise the sugar phosphate
portions of adjacent nucleotides bonded together. The
phosphate of one nucleotide is covalently bound to the
sugar of the next nucleotide.
9. The DNA double helix is antiparallel, which means that
the 5' end of one strand is paired with the 3' end of its
complementary strand (and vice versa). As shown in
Figure, nucleotides are linked to each other by their
phosphate groups, which bind the 3' end of one sugar to
the 5' end of the next sugar.
10. Along the whole length of the DNA molecule, there are
two depressions—referred to as the “minor groove” and
the “major groove”—that lie between the strands.
In a DNA molecule, the different nucleotides are
covalently joined to form a long polymer chain by
covalent bonding between the phosphates and sugars.
11. For any one nucleotide, the phosphate attached to the
hydroxyl group at the 5’ position of the sugar is in turn
bonded to the hydroxyl group on the 3’ carbon of the
sugar of the next nucleotide. Since each phosphate–
hydroxyl bond is an ester bond, the linkage between the
two deoxynucleotides is a 3’5’ phosphodiester bond.
Thus, in a DNA chain, all of the 3’ and 5’ hydroxyl groups
are involved in phosphodiester bonds except for the first
and the last nucleotide in the chain. The first nucleotide
has a 5’ phosphate not bonded to any other nucleotide
and the last nucleotide has a free 3’ hydroxyl. Thus each
DNA chain has polarity; it has a 5’ end and a 3’ end.
12. Erwin Chargaff was one of a handful of scientists
who expanded on Levene's work by uncovering
additional details of the structure of DNA, thus
further paving the way for Watson and Crick.
13. A, B and Z forms of DNA
The Watson-Crick structure is also referred to as B form
DNA, or B-DNA. The B form is the most stable structure
for a random-sequence DNA molecule under
physiological conditions and is therefore the standard
point of reference in any study of the properties of DNA.
Two structural variants that have been well characterized
in crystal structures are the A and Z forms. These three
DNA conformations are shown in Figure, with a
summary of their properties.
14. The A form is favored in many solutions that are relatively
devoid of water. The DNA is still arranged in a right-
handed double helix, but the helix is wider and the
number of base pairs per helical turn is 11, rather than
10.5 as in B-DNA. The plane of the base pairs in A-DNA is
tilted about 20with respect to the helix axis. These
structural changes deepen the major groove while making
the minor groove shallower. The reagents used to
promote crystallization of DNA tend to dehydrate it, and
thus most short DNA molecules tend to crystallize in the
A form.
15. Z-form DNA is a more radical departure from the B structure; the
most obvious distinction is the left handed helical rotation. There
are 12 base pairs per helical turn, and the structure appears more
slender and elongated. The DNA backbone takes on a zigzag
appearance. Certain nucleotide sequences fold into left handed Z
helices much more readily than others. Prominent examples are
sequences in which pyrimidines alternate with purines, especially
alternating C and G or 5-methyl-C and G residues. To form the
left-handed helix in Z-DNA, the purine residues flip to the syn
conformation, alternating with pyrimidines in the anti-
conformation. The major groove is barely apparent inZ-DNA,
and the minor groove is narrow and deep. Whether A-DNA
occurs in cells is uncertain, but there is evidence for some short
stretches (tracts) of Z-DNA in both prokaryotes and eukaryotes.
These Z-DNA tracts may play a role (as yet undefined) in
regulating the expression of some genes or in genetic
recombination.
16. Chargaff Rules
The nucleotide composition of DNA varies
among species
The amount of adenine (A) is usually similar to
the amount of thymine (T), and the amount of
guanine (G) usually approximates the amount of
cytosine (C).
The total amount of purines (A + G) and the total
amount of pyrimidines (C + T) are usually nearly
equal.
17. DNA “semi-conservative” Replication
DNA replication is the process by which the
genetic material is copied prior to distrubution into
daughter cells
The original DNA strands are used as templates for
the synthesis of new strands
It occurs very quickly, very accurately and at the
appropriate time in the life cycle of the cell
DNA replication relies on the complementarity of
DNA strands
The AT/GC rule or Chargaff’s rule
18. In the semi-conservative model, the two parental strands
separate and each makes a copy of itself. After one round
of replication, the two daughter molecules each comprise
one old and one new strand. Note that after two rounds,
two of the DNA molecules consist only of new material,
while the other two contain one old and one new strand.
The semi-conservative model is the spontaneously
appealing model, because separation of the two strands
provides two templates, each of which carries all the
information of the original molecule. It also turns out to
be the correct one (Meselson & Stahl, 1958).
19. The process can be summarized as follows:
The two DNA strands in the parent DNA
molecule come apart
Each “parent strand” then serves as a template
for the synthesis of a new complementary strand
The two newly-made strands = daughter
strands
The two original ones = parental strands
20. This process is called semi-conservative because it conserves
only half of the original (parent) DNA molecule in the two
daughter DNA molecules. One strand in each daughter
molecule is completely new.
In the late 1950s, three different mechanisms were
proposed for the replication of DNA
Conservative model
• Both parental strands stay together after DNA
replication and one of the daughter molecules
contains all new nucleotides
Semiconservative model
• The double-stranded DNA contains one parental
and one daughter strand following replication
Dispersive model
• Parental and daughter DNA are interspersed in
both strands following replication
21. In 1958, Matthew Meselson and Franklin Stahl
devised a method to investigate these models.
Their experiment can be summarized as follows:
Grow E. coli in the presence of 15N (a heavy isotope
of nitrogen) for many generations
The population of cells now has heavy-labeled DNA
because the DNA bases are rich in nitrogen
Switch E. coli to medium containing only 14N
(a light isotope of nitrogen)
Collect sample of cells after various times
Analyze the density of the DNA by centrifugation
using a CsCl gradient
22. The actual data from the Mesleson-Stahl experiment is
shown below.
After one generation,
DNA is “half-heavy”
After ~ two generations, DNA is of two
types: “light” and “half-heavy”
This is consistent with only the
semi-conservative model
23. The Meselson–Stahl experiment was an experiment by
Matthew Meselson and Franklin Stahl in 1958 which
supported the hypothesis that DNA replication was
semiconservative. Meselson and Stahl decided the best way
to tag the parent DNA would be to change one of the atoms
in the parent DNA molecule. Remember that nitrogen is
found in the nitrogenous bases of each nucleotide. So they
decided to use an isotope of nitrogen to distinguish between
parent and newly-copied DNA. The isotope of nitrogen had
an extra neutron in the nucleus, which made it heavier.
Three hypotheses had been previously proposed for the
method of replication of DNA.
In the semiconservative hypothesis, proposed by Watson
and Crick, the two strands of a DNA molecule separate
during replication. Each strand then acts as a template for
synthesis of a new strand.
24. The conservative hypothesis proposed that the entire
DNA molecule acted as a template for the synthesis of an
entirely new one. In the conservative model, the parental
molecule directs synthesis of an entirely new double-
stranded molecule, such that after one round of
replication, one molecule is conserved as two old strands.
This is repeated in the second round.
The dispersive hypothesis is exemplified by a model
proposed by Max Delbrück, which attempts to solve the
problem of unwinding the two strands of the double
helix by a mechanism that breaks the DNA backbone
every 10 nucleotides or so, untwists the molecule, and
attaches the old strand to the end of the newly
synthesized one. This would synthesize the DNA in short
pieces alternating from one strand to the other.
25. Each of these three models makes a different
prediction about the distribution of the "old" DNA in
molecules formed after replication. In the
conservative hypothesis, after replication, one
molecule is the entirely conserved "old" molecule,
and the other is all newly synthesized DNA. The
semiconservative hypothesis predicts that each
molecule after replication will contain one old and
one new strand. The dispersive model predicts that
each strand of each new molecule will contain a
mixture of old and new DNA.
26. Experimental procedure and results
Matthew Meselson and Franklin Stahl were well
acquainted with these three predictions, and they
reasoned that if there were a way to distinguish old
versus new DNA, it should be possible to test each
prediction. Aware of previous studies that had relied on
isotope labels as a way to differentiate between parental
and progeny molecules, the scientists decided to see
whether the same technique could be used to
differentiate between parental and progeny DNA. If it
could, Meselson and Stahl were hopeful that they would
be able to determine which prediction and replication
model was correct.
27. Meselson & Stahl began their experiment by choosing two
isotopes of nitrogen -the common and lighter 14N, and the
rare and heavier 15N (so-called "heavy" nitrogen) - as their
labels and a technique known as cesium chloride (CsCl)
equilibrium density gradient centrifugation as their
sedimentation method. Meselson and Stahl opted for
nitrogen because it is an essential chemical component of
DNA; therefore, every time a cell divides and its DNA
replicates, it incorporates new N atoms into the DNA of
either one or both of its two daughter cells, depending on
which model was correct. "If several different density
species of DNA are present," they predicted, "each will
form a band at the position where the density of the CsCl
solution is equal to the buoyant density of that species. In
this way, DNA labeled with heavy nitrogen (15N) may be
resolved from unlabeled DNA" (Meselson & Stahl, 1958).
28.
29. The scientists then continued their experiment by
growing a culture of E. coli bacteria in a medium that
had the heavier 15N (in the form of 15N-labeled
ammonium chloride) as its only source of nitrogen. In
fact, they did this for 14 bacterial generations, which
was long enough to create a population of bacterial
cells that contained only the heavier isotope (all the
original 14N-containing cells had died by then). Next,
they changed the medium to one containing only 14N-
labeled ammonium salts as the sole nitrogen source.
So, from that point onward, every new strand of
DNA would be built with 14N rather than 15N.
30. Just prior to the addition of 14N and periodically
thereafter, as the bacterial cells grew and replicated,
Meselson and Stahl sampled DNA for use in
equilibrium density gradient centrifugation to
determine how much 15N (from the original or old
DNA) versus 14N (from the new DNA) was present. For
the centrifugation procedure, they mixed the DNA
samples with a solution of cesium chloride and then
centrifuged the samples for enough time to allow the
heavier 15N and lighter 14N DNA to migrate to different
positions in the centrifuge tube.
31. By way of centrifugation, the scientists found that DNA
composed entirely of 15N -labeled DNA (i.e., DNA
collected just prior to changing the culture from one
containing only 15N to one containing only 14N) formed a
single distinct band, because both of its strands were
made entirely in the "heavy" nitrogen medium. Following
a single round of replication, the DNA again formed a
single distinct band, but the band was located in a
different position along the centrifugation gradient.
Specifically, it was found midway between where all the
15N and the entire 14N DNA would have migrated-in other
words, halfway between "heavy" and "light".
32. Based on these findings, the scientists were
immediately able to exclude the conservative
model of replication as a possibility. After all, if
DNA replicated conservatively, there should have
been two distinct bands after a single round of
replication; half of the new DNA would have
migrated to the same position as it did before the
culture was transferred to the 14N-containing
medium (i.e., to the "heavy" position), and only the
other half would have migrated to the new position
(i.e., to the "light" position). That left the scientists
with only two options: either DNA replicated semi-
conservatively, as Watson and Crick had predicted,
or it replicated dispersively.
33. To differentiate between the two, Meselson and Stahl had to
let the cells divide again and then sample the DNA after a
second round of replication. After that second round of
replication, the scientists found that the DNA separated into
two distinct bands: one in a position where DNA containing
only 14N would be expected to migrate, and the other in a
position where hybrid DNA (containing half 14N and half
15N) would be expected to migrate. The scientists continued
to observe the same two bands after several subsequent
rounds of replication. These results were consistent with the
semiconservative model of replication and the reality that,
when DNA replicated, each new double helix was built with
one old strand and one new strand. If the dispersive model
were the correct model, the scientists would have continued
to observe only a single band after every round of
replication.
34. Rolling circle replication
Rolling circle replication describes a process of
unidirectional nucleic acid replication that can rapidly
synthesize multiple copies of circular molecules
of DNA or RNA, such as plasmids,
the genomes of bacteriophages, and the circular
RNA genome of viroids. Some eukaryotic viruses also
replicate their DNA via a rolling circle mechanism.
35. Rolling circle DNA replication is initiated by an initiator
protein encoded by the plasmid or bacteriophage DNA,
which nicks one strand of the double-stranded, circular
DNA molecule at a site called the double-strand origin,
or DSO. The initiator protein remains bound to the 5'
phosphate end of the nicked strand, and the free 3'
hydroxyl end is released to serve as a primer for DNA
synthesis by DNA polymerase III. Using the un-nicked
strand as a template, replication proceeds around the
circular DNA molecule, displacing the nicked strand as
single-stranded DNA. Displacement of the nicked strand
is carried out by a host-encoded helicase called PcrA (the
abbreviation standing for plasmid copy reduced) in the
presence of the plasmid replication initiation protein.
36. Continued DNA synthesis can produce multiple single-
stranded linear copies of the original DNA in a continuous
head-to-tail series called a concatemer. These linear copies
can be converted to double-stranded circular molecules
through the following process:
First, the initiator protein makes another nick to terminate
synthesis of the first (leading) strand. RNA polymerase and
DNA polymerase III then replicate the single-stranded
origin (SSO) DNA to make another double-stranded circle.
DNA polymerase I removes the primer, replacing it with
DNA, and DNA ligase joins the ends to make another
molecule of double-stranded circular DNA.
37. Rolling circle replication has found wide uses in
academic research and biotechnology, and has been
successfully used for amplification of DNA from very
small amounts of starting material. Some viruses
replicate their DNA in host cells via rolling circle
replication. For instance, human herpesvirus-6 (HHV-6)
(hibv) expresses a set of “early genes” that are believed
to be involved in this process. The long concatemers
that result are subsequently cleaved between the pac-1
and pac-2 regions of HHV-6's genome by ribozymes
when it is packaged into individual virions.
38. John Cairns Experiment
Cairns grew E.Coli bacteria in a medium containing
radioactive thymine, a component of one of the DNA
nucleotides. The radioactivity was in tritium (31H). The
DNA was then carefully extracted from the bacteria and
placed on photographic emulsion for a period of time.
The emulsion was then developed to produce
autoradiograph that was examined under the electron
microscope. Each grain of silver represents a radioactive
decay. Interpretation of this autoradiograph reveals
several points.
39. The first, known at the time, is that the E.Coli DNA is
a circle. The Second point is that DNA is replicated
while maintaining the integrity of the circle i.e., the
circle does not appear to be broken in the process of
DNA replication; an intermediate theta structure is
formed which is due to the formation of replication
eye. Third, replication of the DNA seems to be
occurring at one or two moving Y-junctions in the
circle Replication forks, which further supports the
Semiconservative replication.
41. DNA Replication in Bacteria (E.Coli)
DNA synthesis begins at a site termed the origin of
replication (“Ori -C”)
Each bacterial chromosome has only one ori- C
Synthesis of DNA proceeds bi-directionally around
the bacterial chromosome
The “replication forks” eventually meet at the
opposite side of the bacterial chromosome
This ends replication
Bacterial DNA replication has been studied most
extensively in E. coli, the favorite bacterial “model
organism” of molecular geneticists.
The ORI in E. coli is called “oriC”
Three types of DNA sequences in oriC are functionally
significant
AT-rich region
DnaA boxes
GATC methylation sites
42.
43. DNA replication is initiated by the binding of DnaA
proteins to the DnaA box sequences
• This binding stimulates the cooperative binding of an
additional 20 to 40 DnaA proteins to form a large
complex.
• This causes the DNA to twist and the puts torque on
the nearby AT-rich region to denature and form a
replication bubble
AT base pairs are held together by only 2 H
bonds
CG base pairs are held together by 3 H bonds
Therefore, AT-rich regions of DNA denature
more easily than CG-rich regions of DNA
44. In the next step, DnaB (also called helicase) binds to
each strand of the separated double helix. It’s job is to
move along the DNA, progressively expand the
replication bubble in both directions.
Travels along the DNA
strand in the 5’ to 3’
direction, using energy
from ATP
As the helicases move on each strand in opposite directions,
two replication forks are created. These forks move
progressively farther and farther in each direction as the
bubble widens.
45.
46. DNA helicase separates the two DNA strands by breaking
the hydrogen bonds between them
This generates positive supercoiling ahead of each
replication fork so another enzyme, topoisomerase,
travels ahead of the helicase and alleviates these
supercoils
Single-strand binding proteins (SSBPs) are also needed to
bind to the separated DNA strands and keep them apart
Otherwise, the strands would simply reanneal
After the helicase, gyrase, and SSBPs are in place, short (10 to
12 nucleotides) RNA primers are synthesized by DNA
primase
These short RNA strands start, or prime, DNA synthesis
because DNA polymerase, the enzyme that copies DNA,
cannot start a new strand on its own
The RNA primers are later removed and replaced with DNA
47. Keep the parental
strands apart
Breaks the hydrogen bonds
between the two strands
Alleviates
supercoiling
Synthesizes an
RNA primer
DNA Polymerases
DNA polymerases are the enzymes that catalyze the
attachment of nucleotides to make new DNA
In E. coli there are five proteins with polymerase activity
DNA pol I
• Composed of a single polypeptide
• Removes the RNA primers and replaces them with
DNA during DNA replication
48. DNA pol III
Composed of 10 different subunits
The a subunit synthesizes DNA
The other 9 fulfill other functions
The complex of all 10 is referred to as the
“DNA pol III holoenzyme”
Is responsible for most of the DNA replication
process
DNA pol II, IV and V
Specialized DNA polymerases that replicate
short areas of DNA for the purposes of genome
repair
The numbering of these polymerases was done in the
order they were discovered
Bacterial DNA polymerases may vary in their subunit
composition. However, they have the same type of catalytic
subunit.
49. Structure resembles
a human right hand:
Thumb and fingers
wrapped around the
DNA
Template DNA thread
through the palm;
All DNA polymerases, whether bacterial or eukaryotic,
share 2 very important limitations:
1. They cannot initiate DNA synthesis on their own. They
require that an RNA primer be laid down on the DNA first
by DNA primase.
50. They can only “grow” a new DNA chain in the 5’ to 3’ direction.
It is not fully understood why all DNA polymerases
have these limitations. As will be demonstrated
below, DNA replication would be much simpler if
they did not!
Because DNA polymerase can only synthesize a new
strand 5’ to 3’, the two new daughter strands are
synthesized in different ways:
51. Leading strand
One RNA primer is made at the origin
DNA pol III attaches nucleotides in a 5’ to 3’ direction as
it slides toward the replication fork
Lagging strand
Synthesis is also in the 5’ to 3’ direction
However it occurs away from the replication fork
Many RNA primers are required
DNA pol III uses the RNA primers to synthesize small DNA
fragments (1000 to 2000 nucleotides each)
These are termed Okazaki fragments after their
discoverers
DNA pol I removes the RNA primers and fills the
resulting gap with DNA
After the gap is filled, a covalent bond is still missing so
DNA ligase must create this bond
52. Can be synthesized continuously in the
5’ to 3’ direction
Must be synthesized
discontinuously to
maintain 5’ to 3’
synthesis
Note that if DNA polymerase was able to synthesize a
new strand in either direction (5’ to 3’ or 3’ to 5’),
lagging strand synthesis and Okasaki fragments
would not be needed.
The process can also be visualized in 3-D as follows:
53. The Synthesis Reaction
DNA polymerases catalyze a phosphodiester bond
between the innermost phosphate group of the incoming
deoxynucleoside triphosphate and the
3’-OH of the sugar of the previous deoxynucleotide.
In the process, the last two phosphates of the
incoming nucleotide are released in the form of
pyrophosphate (PPi)
In E. coli, DNA pol III stays on the DNA template long
enough to polymerize up to 50,000 nucleotides at a rate
of ~ 750 nucleotides per second!
54. Proofreading
DNA replication exhibits a high degree of fidelity.
Mistakes during the process are extremely rare
In E. coli, DNA pol III makes only one mistake
per 108 bases
There are several reasons why fidelity is high:
1. Instability of mismatched pairs
Complementary base pairs have much higher
stability than mismatched pairs
This feature only accounts for part of the fidelity
It has an error rate of 1 per 1,000 nucleotides
2. Configuration of the DNA polymerase active site
DNA polymerase is unlikely to catalyze bond
formation between mismatched pairs
This induced-fit phenomenon decreases the error
rate to a range of 1 in 100,000 to 1 million
55. 3. Proofreading function of DNA polymerase
DNA polymerases can identify a mismatched
nucleotide and remove it from the daughter strand
The enzyme uses its 3’ to 5’ exonuclease activity to
remove the incorrect nucleotide
It then changes direction and resumes DNA synthesis
in the 5’ to 3’ direction
Termination of Replication in Bacteria
DNA replication ends when oppositely advancing
forks meet (remember that the chromosome is
circular).
• DNA replication often results in two intertwined
molecules called catenanes
• Catenanes and are separated prior to cell division
Replication Decatenization
57. DNA Replication in Eukaryotes
Eukaryotic DNA replication is not as well understood
as bacterial replication.
• The two processes do have extensive similarities,
• Many of the bacterial enzymes described above have
also been found in eukaryotes
Nevertheless, DNA replication in eukaryotes is more
complex due to:
• Large linear chromosomes
• Multiple origins of replication per chromosome
• Tight packaging of the DNA around proteins
58. Linear eukaryotic chromosomes also have telomeres at
both ends
The term telomere refers to the complex of repetitive
DNA sequences found at the terminal ends of eukaryotic
chromosomes as well as the proteins that recognize this
sequence and bind the DNA there.
Telomeric sequences consist of
• Moderately repetitive tandem arrays
• 3’ overhang that is 12-16 nucleotides long that results
from the loss of the RNA primer at the 5’ end of each
strand that cannot be replaced
59. Therefore if this problem is not solved:
• The linear chromosome becomes progressively
shorter with each round of DNA replication
• Indeed, some cells solve this problem by adding
DNA sequences to the ends of telomeres following
replication
• This requires a specialized mechanism
catalyzed by the enzyme telomerase
• All single-celled eukaryotes have active
telomerase enzyme because if they didn’t
successive generations of the organism would
have shortened telomeres
Eventually, this would result in the loss of
important genes and the death of the
species
60. However, most somatic cells in multicellular
organisms do not express telomerase and the
telomeres shorten every time the cells replicate.
• Most human somatic cells can only replicate
about 30 times before their telomeres are so
shortened that the cell dies
This sets an upper limit on the life span
of the organism
Telomerase is active in the germ line cells,
maintaining telomere length from one generation to
the next.
Telomerase is also often abnormally activated in
cancer cells. This is why tumors don’t eventually
replicate themselves to death. Once a tumor cell has
activated telomerase, it is immortalized.
61. Immortalized somatic cells are extremely dangerous
in multicellular organisms. If a cell suffers a mutation
in a gene controlling the cell cycle, the cell can begin
to replicate much faster than the surrounding cells.
Normally, such cells will die off when their
telomeres get too short
Immortalized cells will continue to cycle and the
tissue will grow
The result can be a cancerous tumor that is life-
threatening to the organism
62. EUKARYOTIC DNA REPLICATION
DNA replication is the process of producing two
identical replicas from one original DNA molecule.
This biological process occurs in all living organisms
and is the basis for biological inheritance. DNA is
made up of two strands and each strand of the original
DNA molecule serves as template for the production
of the complementary strand, a process referred to as
semiconservative replication. The fundamental
mechanism of eukaryotic replication is same as
prokaryotic DNA Replication but some variation also
there.
63. The replications in eukaryotes are more complex. Because
DNA molecule of eukaryote
Eukaryotic genomes are quite complex
Considerably larger than bacterial DNA
Organized into complex nucleoprotein structure
(chromatin)
Essential features of DNA replication are the same in
prokaryotes and eukaryotes, Similarities of prokaryotes and
eukaryotic replication
Replication process is fundamentally similar in both
prokaryotes and eukaryotes. Process that are similar Include
Formation of replication fork
Simi conservative replication
Movement of replication fork bidirectional
Primer synthesis
Okazaki fragment synthesis in lagging strand
Primer removal
Gap bridging between newly synthesized DNA
fragments.
64. Difference between prokaryotic and eukaryotic replication
Overall process of eukaryotic replication is bit more complex.
Important differences are due to
• Larger size of eukaryotic DNA (105-106 Kb) compared to
prokaryotic DNA 15x103 kb in E.Coli
• Distinct package of eukaryotic DNA in the term of chromatin
• Slower rate of fork movement in eukaryotes
For DNA to become available to DNA polymerase, nucleotide
must dissemble. This step slows the Rate of fork movement.
Replication rate:
Prokaryotes: An E.Coli replication fork progresses at
approximately 1000 bp / sec.
Eukaryotes: Replication rate ten times slower than prokaryotes
50 nucleotides / sec.
65. Enzymes and proteins required for eukaryotic DNA
replication
Eukaryotic DNA polymerase:
In eukaryotes there are five different polymerases and they
differ in
Intracellular compartmentation
Kinetic property
Response to inhibitor
DNA pol location function
DNA Pol α nucleus lagging strand
synthesis
DNA Pol β nucleus DNA repair
DNA Pol ϒ mitochondria mitochondrial
replication
DNA Pol δ nucleus leading strand
synthesis
DNA Pol Ɛ nucleus gap filling between
okazaki fragments
66. DNA polymerases location function
DNA Pol alpha nucleus
DNA replication initiation (both leading
and lagging strand)
DNA Pol Delta nucleus lagging strand synthesis
DNA Pol Epsilon nucleus
leading strand synthesis
67. DNA polymerase Alpha
- Located in nucleus
- Catalysis the initiation of replication on both
leading and lagging strand synthesis
- Tetramer – 4 subunits POLA 1 (catalytic) POLA 1
(regulatory) POLA 3 ,4 (Primase)
- larger subunit - 5´-3´ polymerization activity
-Two smaller subunit – primase activity
- one subunit – assist in other three
subunits
- RNA primer 5-15 nucleotides are subsequently
extended by DNA Pol α.
68. DNA polymerase Delta
- Located in nucleus
- Catalyzes the synthesis of lagging strand
- Having four subunits – POLD 1,2,3,4
- larger subunits catalyzes 5´-3´ polymerization
activity
- Smaller subunits catalyzes 3´-5´ exonuclease
activity (proof reading activity)
- High processivity when interacting with PCNA
(Proliferating cell nuclear antigen).
69. PCNA
- Molecular weight 25,000; PCNA is important for both
DNA synthesis and DNA repair
- Multimeric protein
- Found in large amount in nuclei of proliferating
cells.
- Act as “clamp” to keep DNA pol δ from
dissociating off the leading DNA strand. “Clamp”
consist of 3 PCNA molecules each containing two
topologically identical domains that are tightly associated to
form closed ring.
- PCNA helps hold DNA polymerase epsilon (Pol ε)
to DNA.
- DNA pol δ improves fidelity of replication by a
factor of 102 due to its proof reading action. It contributes in
limiting the rates of overall error to 10-9 to 10-12.
- DNA Pol δ is also associated with helicase activity.
70. DNA polymerase Epsilon - Є
located in nucleus
Having four subunits – POLE 1, (Catalytic) 2,3,4
(subunits)
associated with - 5´- 3´ polymerization activity
5’- 3’ exonuclease activity (to
remove RNA primer)
3’- 5’ exonuclease activity (to proof
read)
DNA pol Є catalyzes the repair mechanism and
catalyzes the removal of primer and filing the
primer gap in Okazaki fragments.
Replicating factor A/ Replicating protein A
(RPA/RFA)
RPA/ RFA are similar to single strand binding
protein. They bind to SS DNA and prevent the re-
annealing of parental DNA.
71. Replication factor C (RFC)
RFC also called as clamp loader or match maker.
RFC assist in DNA pol δ to form clamp between
DNA and PCNA.
RFC also plays important role in setting up a link
between DNA pol δ and DNA pol α, so that the
leading strand synthesis and lagging strand synthesis
in eukaryotes can take place simultaneously.
72. Histone Dissociation and Association
Since DNA is present in packaged form as chromatin, DNA
replication is sandwiched between two additional steps in
eukaryotes.
1. Carefully ordered and in complete dissociation of the
chromatin.
2. Re-association of DNA with the histone octomers to form
nucleosome.
Dissociation of histone: methylation at the fifth position of
cytosine residues by a DNA methyl transferase appears to
functioning by loosening up the chromatin structure. This
allows DNA access to proteins and enzymes needed for
DNA replication.
Synthesis of histone: the synthesis of new histone occurs
simultaneously with DNA replication.
73. SEQUENTIAL STEPS IN EUKARYOTIC DNA
REPLICATION
DNA replication is a very complicated process that
involves several enzymes and other proteins. It
occurs in following stages
• Pre-initiation
• Initiation
• Elongation
• Termination
• Telomerase function
PRE-INITIATION
Actually during pre-initiation stage, replicator selection occurs.
Replicator selection is the process of identifying the sequences
that will direct the initiation of replication and occur in G1
phase (prior to S phase). This process leads to the assembly of a
multiprotein complex at each replicator in the genome. Origin
activation only occurs after cells enter S phase and triggers the
Replicator – associated protein complex to initiate DNA
unwinding and DNA polymerase recruitment.
74. Replicator selection is mediated by the formation of pre-
replicative complexes (pre-RCs). The first step in the
formation of the pre-RC is the recognition of the replicator
by the eukaryotic initiator, ORC (Origin recognition
Complex). Once ORC is bound, it recruits two helicase
loading proteins (cell division cycle protein - Cdc6 and
Cdtl). Together, ORC and the loading proteins recruit a
protein that is thought to be the eukaryotic replication
fork helicase (the Mem 2-7 complex). Formation of the
pre-RC does not lead to the immediate unwinding of
origin DNA or the recruitment of DNA polymerases.
Instead the pre-RCs that are formed during Gl are only
activated to initiate replication after cells pass from the Gl
to the S phase of the cell cycle.
75. Figure - The steps in the formation of pre-replicative
complex (pre-RC)
The assembly of the pre-RC is an ordered process that is
initiated by the association of the ORC with the replicator.
Once bound to the replicator ORC recruits at least two
additional proteins Cdc6 and Cdt1 (cell division cycle
proteins). These three proteins function together to recruit
the putative eukaryotic DNA helicase- the MCM 2-7
(multi-chromatin maintenance protein) complex to
complete the formation of the pre-RC
76. INITIATION
ARS (Autonomously Replicating Sequences)
In eukaryotes the DNA replication is initiated at
specific site known as ARS
(Autonomously Replication Sequences) or replicators.
ARS (Origin of chromosome in eukaryotes) contains
- A central core sequence which contains highly
conserved 11 bp sequence (AT rich sequence)
- Flanking sequences.
77. ARS – is 100- 150 long (generally it span about 150 bp)
There are multiple origins in eukaryotes. Eg: yeast
contains 400 ARS. The multiple origins are spaced 30 -300
kb apart. The sequence between two origins of replication
is called replicons. An average human chromosome
contains as many as 100 replicons and replication may
proceed simultaneously at as many as 200 forks.
- The central core sequence contains 11 bp
elements known as “ARS consensus sequence” rich in AT
pair (It is similar to AT rich 13 mers present in E.Coli
Ori C). It is also called as ORE (Origin replication
element)
- The flanking sequences consist of overlapping
sequence that include varients of core sequences
78. ORE (Origin Replicating Element) and ORC (Origin
Recognition Complex)
At the origin there is an association of sequence
specified – ds DNA binding sequence.
ORE (11 bp sequence in core sequence) binds to a set
of proteins (DNA pol α, DNA pol δ, RFC, PCNA,
RFA, SSB and helicase) collectively called as ORC
Origin Recognition Complex
ORC is a multimeric protein. Initiation of replication
in all eukaryotes requires this multimeric subunit
protein (ORC) which binds to several sequences
within the replicator.
79. DUE (DNA Unwinding Element)
ORE located adjacent to approximately 80 bp AT
rich sequence that is easy to unwind. This is called
DUE (DNA Unwinding Element) Binding of ORC to
ORE causes unwinding at DUE.
Events in replication fork:
When ORC (DNA pol α, DNA pol δ, RFC, RFA,
PCNA, SSB helicase into the origin of replication
especially at ORE, the DNA synthesis is initiated.
The replication fork moves bi-directionally and
replication proceeds simultaneously as many as 200
forks.
80. Formation of replication fork:
The replication fork in eukaryotes consists of four
components that form in the following sequence.
DNA helicase and DNA pol δ (due to its associated
helicase activity) unwinds short segment of parental
DNA at 80 bp AT rich sequence called DUE (DNA
unwinding elements) which is located adjacent to ORE.
DNA pol α initiated the synthesis of RNA primer. (DNA
pol α is also having primase activity) The primer is
approximately 10 bp.
DNA pol ε in lagging strand and DNA pol δ in leading
strand initiates the daughter strand synthesis.
SSB and RFA bind to SS DNA and prevent re-annealing
of SS DNA.
81. In addition to the above, two additional factors
play important role in replication of eukaryotes
PCNA (proliferating cell nuclear antigen) act as a
‘’clamp’’ to keep DNA pol δ from dissociating off
the leading strand and thus increasing the
processing of DNA pol ε.
RFC also called as ‘clamp loader’ or ‘match maker’.
RFC assist in - DNA pol δ to form clamp between
DNA and PCNA and
- setting up a link between DNA pol δ and
DNA pol ε so that the leading Strand and lagging
strand synthesis in eukaryotes can take place
simultaneously.
82. Rate of Replication fork Movement
The rate of replication fork movement in eukaryote
(approximately 50 nucleotide /sec) is only one tenth that
observed in E.Coli at this rate, replication of an average
human chromosome proceeding from a single origin
would take more than 500 hours. Instead of that,
replication of human chromosome proceeds bi-
directionally from multiple origins spaced 30-300 kb
apart and completed within an hour.
DNA sequence between two origins of replication is
called replicons. An average chromosome contains
nearly 100 replicons and thus replication proceeds
simultaneously at as many as 200 forks.
83. ELONGATION
During elongation, an enzyme called DNA polymerase
adds DNA nucleotides to the 3' end of the newly
synthesized polynucleotide strand. The template
strand specifies which of the four DNA nucleotides (A,
T, C, or G) is added at each position along the new
chain. Only the nucleotide complementary to the
template nucleotide at that position is added to the
new strand. For example, when DNA polymerase
meets an adenosine nucleotide on the template strand,
it adds a thymidine to the 3' end of the newly
synthesized strand, and then moves to the next
nucleotide on the template strand. This process will
continue until the DNA polymerase reaches the end of
the template strand.
84.
85. All newly synthesized polynucleotide strands must be
initiated by a specialized RNA polymerase called
primase. Primase initiates polynucleotide synthesis and
by creating a short RNA polynucleotide strand
complementary to template DNA strand. This short
stretch of RNA nucleotides is called the primer. Once
RNA primer has been synthesized at the template DNA,
primase exits, and DNA polymerase extends the new
strand with nucleotides complementary to the template
DNA. Eventually, the RNA nucleotides in the primer are
removed and replaced with DNA nucleotides. Once DNA
replication is finished, the daughter molecules are made
entirely of continuous DNA nucleotides, with no RNA
portions.
86. The Leading and Lagging Strands
DNA polymerase can only synthesize new strands in the
5' to 3' direction. Therefore, the two newly synthesized
strands grow in opposite directions because the
template strands at each replication fork are antiparallel.
The "leading strand" is synthesized continuously toward
the replication fork as helicase unwinds the template
double stranded DNA.
The "lagging strand" is synthesized in the direction away
from the replication fork and away from the DNA
helicase unwinds. This lagging strand is synthesized in
pieces because the DNA polymerase can only synthesize
in the 5' to 3' direction, and so it constantly encounters
the previously synthesized new strand. The pieces are
called Okazaki fragments, and each fragment begins
with its own RNA primer.
87. Leading strand synthesis:
- Leading strand synthesis is initiated upon RNA primer,
synthesized by the primase subunit of DNA pol α. The
RNA primer contains 10-15 nucleotides.
- Then DNA pol α adds a stretch of DNA to the primer.
- At this point replication factor C (RFC) carries out a
process called polymerase switching.
- RFC removes DNA pol α and assembles PCNA in the
region of primer strand terminus.
- Then DNA pol epsilon binds to PCNA and carries out
highly processive leading strand synthesis due to its 5’-3’
polymerization activity.
- After the addition of several nucleotides in the daughter
strand, primer is removed. DNA pol Є due to its 5’-3’
exonuclease activity removes the primer and the gap is filled
by the same DNA pol Є due to its 5’-3’ polymerization
activity.
- Then the nick is sealed by DNA ligase.
DNA pol δ improves the fidelity of replication due to its
proof reading activity.
88. Lagging strand synthesis:
Lagging strand synthesis of Okazaki fragment initiated same
way as leading strand synthesis. An Okazaki fragment
contains 150-200 nucleotides.
RNA primer is synthesised by DNA pol α due to its primase
activity.
The primer is then extended by DNA pol delta due to its 5’-3’
polymerization activity (lagging strand synthesis), using
deoxy ribonucleotides (dNTPs).
Priming is a frequent event in lagging strand synthesis with
RNA primers placed every 50 or 80 nucleotides.
All but one of the ribonucleotides in RNA primer is removed
by RNase H1.
Then exonuclease activity of FEN 1/ RTH 1 complex removes
the one remaining nucleotide.
The gap is filled by DNA pol Є by its 5’-3’ polymerase activity.
DNA ligase joins the Okazaki fragment of the growing DNA
strand.
89.
90. Combined activity of DNA pol delta and DNA pol
epsilon:-
Looping of lagging strand allows a combined polymerase
delta and polymerase epsilon asymmetric dimer to
assemble and elongate both leading and lagging strands in
the same overall direction of fork movement.
TERMINATION
When the replication forks meet each other, then
termination occurs. It will result in the formation of two
duplex DNA. Even though replication terminated, 5’ end
of telomeric part of the newly synthesized DNA found to
have shorter DNA strand than the template parent strand.
This shortage corrected by the action of telomerase enzyme
and then only the actual replication completed.
91. TELOMERES
Eukaryotic chromosomes are linear. The ends of
chromosomes have specialized structures known as
‘Telomeres’.
Telomeres are – short (5-8 bp)
- tandem repeated and
- GC rich nucleotide sequence.
- Telomeres form protective cap 7-12 kbp long in
the ends of chromosome. Telomeres are necessary for
chromosome maintenance and stability. They are
responsible for maintaining chromosome integrity by
protecting against DNA degradation and
rearrangement.
92. Problem in the completion of replication of lagging
strand:
- Linear genomes including those of several
viruses as well as the chromosomes of eukaryotic cells
force a special problem completion of replication of the
lagging strand.
- Excision of an RNA primer from the 5’ end of a
linear molecule would leave a gap (primer gap). This
gap cannot be filled by DNA polymerase action, because
of the absence of a primer terminus to extend. If the
DNA could not be replicated, the chromosome would
shorten a bit with each round of replication.
- This problem has been solved by Telomerase.
93. Telomerase:
- Telomerase is ribonucleoprotein. It contains a
RNA component which has repeat of 9 to 30
nucleotides long. This RNA component serves as the
template for the synthesis of telomeric repeats at the
parental DNA ends.
- Telomerase is a RNA dependent DNA
polymerase with a RNA component.
Telomerase uses the
- 3’ end of parental DNA strand as primer,
- RNA component of telomerase as template,
- adds successive telomeric repeats to the parental
DNA strand at its 3’ end due to its 5’-3’ RNA
dependent DNA polymerase activity.
94. Regeneration of telomeres:
Telomeric DNA consists of simple tandemly repeated
sequences like those shown as below:
Telomeric repeats sequence at 5’end
-
Organism Repeat
Human AGGGTT
Higher plant AGGGTTT
Algae AGGGTTTT
protozoan GGGGTTTT
Yeast GGGT
These sequences are repeatedly added to the 3’ termini of
chromosomal DNAs by ‘Telomerase’. Telomerase
uses its RNA component as template and parental DNA as
primer. Then by its RNA dependent DNA polymerase
activity it repeatedly adds telomeric sequences to the 3’
termini of parental DNA.
- Then the telomerase is released.
- Finally the RNA primer, (of telomerase) is bound
near the lagging strand and it is extended by DNA
polymerase. Thus the lagging strand synthesis is completed.
95. In Linear eukaryotic chromosome, once the first primer
on each strand is remove, then it appears that there is
no way to fill in the gaps, since DNA cannot be
extended in the 3′–>5′ direction and there is no 3′ end
upstream available as there would be in a circle DNA.
If this were actually the situation, the DNA strand
would get shorter every time they replicated and genes
would be lost forever.
96. Elizabeth Blackburn and her colleagues have provided
the answer to fill up the gaps with the help of enzyme
telomerase. So, that the genes at the ends, are
conserved. Telomerase is a ribonucleoprotein (RNP)
i.e. it has RNA with repetitive sequence. Repetitive
sequence varies depending upon the species example
Tetrahymena thermophilia RNA has AACCCC
sequence and in Oxytrica it has AAAACCCC.
Telomerase otherwise known as modified Reverse
Transcriptase. In human, the RNA template contains
AAUCCC repeats. This enzyme was also known as
telomere terminal transferase..
.
97. The 3′-end of the lagging strand template basepairs with a
unique region of the telomerase associated RNA.
Hybridization facilitated by the match between the
sequence at the 3′-end of telomere and the sequence at the
3′-end of the RNA. The telomerase catalytic site then adds
deoxy ribonucleotides using RNA molecule as a template,
this reverse transcription proceeds to position 35 of the
RNA template. Telomerase then translocates to the new
3′-end by pairing with RNA template and it continues
reverse transcription. When the G-rich strand sufficiently
long, Primase can make an RNA primer, complementary
to the 3′-end of the telomere’s G-rich strand. DNA
polymerase uses the newly made primer to prime
synthesis of DNA to fill in the remaining gap on the
progeny DNA. The primer is removed and the nick
between fragments sealed by DNA ligase
98. V. Magendira Mani
Assistant Professor,
PG & Research Department of Biochemistry,
Islamiah College (Autonomous),
Vaniyambadi,
Vellore District – 6357512,
Tamilnadu, India.
magendiramani@rediffmail.com ;
https://tvuni.academia.edu/mvinayagam