

Recomendados
Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Destacado
Destacado (20)
Similar a Elasticsearch performance tuning
Similar a Elasticsearch performance tuning (20)
Más de ebiznext
Elasticsearch performance tuning
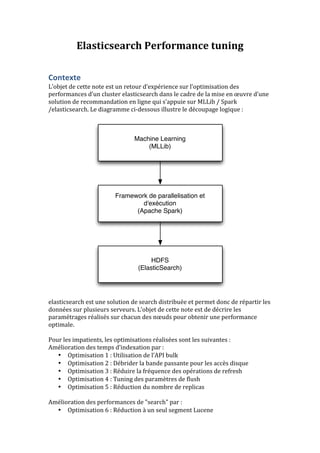
- 1. Elasticsearch Performance tuning Contexte L’objet de cette note est un retour d’expérience sur l’optimisation des performances d’un cluster elasticsearch dans le cadre de la mise en oeuvre d’une solution de recommandation en ligne qui s’appuie sur MLLib / Spark /elasticsearch. Le diagramme ci-‐dessous illustre le découpage logique : Machine Learning (MLLib) Framework de parallelisation et d'exécution (Apache Spark) HDFS (ElasticSearch) elasticsearch est une solution de search distribuée et permet donc de répartir les données sur plusieurs serveurs. L’objet de cette note est de décrire les paramétrages réalisés sur chacun des noeuds pour obtenir une performance optimale. Pour les impatients, les optimisations réalisées sont les suivantes : Amélioration des temps d’indexation par : • Optimisation 1 : Utilisation de l’API bulk • Optimisation 2 : Débrider la bande passante pour les accès disque • Optimisation 3 : Réduire la fréquence des opérations de refresh • Optimisation 4 : Tuning des paramètres de flush • Optimisation 5 : Réduction du nombre de replicas Amélioration des performances de "search" par : • Optimisation 6 : Réduction à un seul segment Lucene
- 2. • Optimisation 7 : Utilisation du cache de filtres • Optimisation 8 : Utilisation sélective du cache de données • Optimisation 9 : Dimensionnement adéquat de la JVM et du cache système • Optimisation 10 : Spécialisation des noeuds elasticsearch D’autres mécanismes d’optimisation sont offerts par Elasticsearch tels que le field data cache pour les agrégations, le routing pour l’orientation des requêtes ou encore l’API warmer qui consiste à précharger les caches et éviter les temps de latence lors des premières sollicitations. Notre objectif n’est pas de tous les énumérer. Les optimisations sont celles que nos avons mis en oeuvre dans un contexte BigData mais qui s’appliquent également à d’autres contextes. Optimisation de l’indexation Optimisation 1 : Optimisation applicative par insertion de masse Dans le cadre de traitement de masse, les opérations sont la plupart du temps des opérations ensemblistes : • Insertion de masse : Les données sont injectées en masse dans la base Elasticsearch pour ensuite être recherchées • Mise à jour / suppression de masse : Suite à un calcul distribué sur Spark , des groupes de données stockés dans Elasticsearch sont potentiellement mises à jour / supprimés. • Les groupes de données sont extraits d’elasticsearch et accédés au travers de RDD Spark. Pour éviter l’invocation séquentielle des opérations d’indexation / mise à jour / suppression, nous avons pris le parti d’utiliser plutôt les opérations ensemblistes et de les invoquer au travers de l’API _bulk d’Elasticsearch. Cela permet à Elasticsearch d’indexer plusieurs documents en une seule fois. Le nombre de documents à inclure dans une requête _bulk est fonction du nombre de documents à indexer et de la taille des documents. Pour notre part, chaque opération d’indexation embarquait environ 5000 documents de 1,5Ko soit 7,5Mo de données indexées par Elasticsearch en une seule opération.
- 3. Noeud Spark Noeud Spark Noeud Spark Cluster Elasticsearch 7,5Mo / opération 7,5Mo / opération 7,5Mo / opération Les opérations d’indexation de masse sont également parallélisées sur Spark. Optimisation 2 : Pas de limite dans l’utilisation de la bande passante pour les accès disque Elasticsearch par défaut limite la bande passante sur les accès disques à 20Mb/s. Dans notre contexte de disques rapides, nous avons également supprimé cette limitation curl -‐XPUT 'localhost:9200/moncluster/_settings' -‐d '{ "transient" : { "indices.store.throttle.type" : "none" } }' Noter la valeur "transient" qui signifie que nous souhaitons ce paramétrage uniquement dans la phase courante. Un arrêt / relance d’Elasticsearch ne conservera pas ces valeurs. Les étapes de l’indexation dans elasticsearch L’indexation d’un document dans Lucene se déroule en quatre phases (bien que ces phases ne soient pas tout à fait séquentielles, je les présente ainsi pour faciliter l’explication) : • Phase 1 (Indexation mémoire) : Le document est indexé dans un segment en mémoire. Le document ainsi indexé est encore invisible aux requêtes de recherche. • Phase 2 (Log sur disque): Enregistrement de la requête d’indexation dans un log de transactions. Comme pour les SGBD classiques, cela permet à Elasticsearch d’être résilient aux pannes et de régénérer les informations d’indexation qui n’ont pas encore été sauvegardées en cas de crash. • Phase 3 (Refresh) : Périodiquement, les informations d’indexation sont rendues accessibles au search. Cette phase, va provoquer l’invalidation des caches.
- 4. • Phase 4 (Flush disque) : Périodiquement, les informations d’indexation sont persistées sur disque. Cette phase va persister sur disque les segments en mémoire et vider le fichier de logs de transactions. Comme on peut le deviner, les phases 3 et 4 sont celles qui ont un impact sur les performances. Optimisation 3 : Réduction du temps d’indexation par réduction de la fréquence de refresh L’opération de « refresh » (phase 3 ci-‐dessus) a pour rôle de rendre disponible les informations récemment indexées pour le search. Cette opération couteuse en phase d’indexation peut être désactivée avant le chargement des données et réactivée une fois l’indexation terminée avec les commandes suivantes : Commande 1 : Désactivation du refresh curl -‐XPUT 'localhost:9200/monindex/_settings' -‐d '{ "index" : { "refresh_interval" : -‐1 } }' Commande 2 : Insertion des données Commande 3 : Réactivation du refresh curl -‐XPUT 'localhost:9200/monindex/_settings' -‐d '{ "index" : { // 1 seconde (valeur par défaut dans ES) "refresh_interval" : 1s } }' Optimisation 4 : Réduction du temps d’indexation par optimisation du flush Dans la phase de flush (phase 4 ci-‐dessus), les segments sont éventuellement regroupés en segments de taille plus importante. La phase 4 se produit dans les conditions suivantes : • Le segment mémoire est plein • Le délai paramétré de flush a été atteint • Le log de transactions est plein
- 5. Document JSON Segment mémoire Transition Log disque Indexation timeout ou segment plein ou transaction log plein déclencher le flush Au moment du flush, les segments sont potentiellement fusionnés. Cette opération est d’autant plus couteuse que la taille du segment est importante. Enfin un nombre trop important de petits segments va ralentir les opérations de search. Optimisation 5 : Réduction du temps d’indexation par réduction du nombre de replicas Une opération d’indexation est terminée lorsque le document est ajout à la partition primaire et à tous les replicas. Le nombre de replicas a donc une incidence directe sur le délai d’indexation. Dans notre cas, les données sont sauvegardées par ailleurs et les données indexées dans le cluster sont "reconstructibles". Nous avons donc tout simplement supprimé les replicas en réduisant le nombre de replicas à 0 dans le fichier de configuration elasticsearch.yml. Optimisation de la recherche Une fois les données indexées, nous avons besoin de les accéder. Dans notre contexte, la base ainsi alimentée devient une base dédiée à a consultation exclusivement. Cela est d’autant plus simple que les optimisations d’indexation sont souvent contradictoires avec les optimisations du search. C’est d ‘ailleurs le cas avec notre choix de ne pas avoir de replicas, qui est bénéfique pour l’indexation mais qui l’est moins pour le search.
- 6. Optimisation 6 : réduction à un seul segment Lucene Nous sommes particulièrement intéressés dans notre exemple par la rapidité du search et le nombre de segments a un impact direct sur les performances. Une fois l’indexation terminée et la base ES destinée exclusivement à être interrogée, nous avons réduit le nombre de segments à 1 par la commande suivante : curl -‐XGET 'localhost:9200/monindex/_optimize?max_num_segments=1&wait_for_merge=fa lse’ Optimisation 7 : Choisir soigneusement les types de filtres Deux types de cache existent dans elasticsearch ; Un cache pour les filtres et un cache pour les données de query. Les requêtes de type "filter" sont les requêtes dont le résultat est une valeur booléenne et les requêtes de type "query" sont destinées à l’extraction de documents. Cache de filtres Les requêtes de type filter sont beaucoup plus performantes car Elasticsearch va mémoriser dans un bitset les documents qui vérifient chacun des filtres d’un groupe de filtres afin de pouvoir les réutiliser indépendamment les uns des autres. Les opérations mettant en oeuvre le "bool filter" sont à privilégier. Les types de filtres les plus performants sont ceux qui mettent en oeuvre les bitset. Il s’agit des types "term" / "exist" / "missing" / "prefix". Les types de filtres "nested" / "has_parent" / "has_child" / "script" ne mettent pas en oeuvre les bitset et ne sont pas non mis en cache par défaut non plus. Optimisation 8 : Mettre en oeuvre le cache de manière sélective Par défaut, les résultats des queries sont mis en cache. Un cache qui se remplit trop vite va provoquer le mécanisme consommateur d’éviction LRU de cache d’elasticsearch. Pour éviter un remplissage un peu trop rapide du cache, nous forçons la propriété "_cache" à la valeur "false" pour les requêtes dont le résultat ne sera pas réutilisé d’un appel à l’autre. Optimisation 9 : Cache de la JVM et cache système Le réflexe le plus courant consiste à dédier le maximum de mémoire vive à la JVM et ne laisser que le strict minimum au système d’exploitation. L’OS s’adapte et réduit du coup la taille du cache disque système, ce qui détériore les performances lors de l’accès aux données. La règle préconisée consiste à octroyer 50% de la mémoire à la JVM et 50% à l’OS. Quant à la taille du tas (heap size) de la JVM, au delà de 32Go, les références sont encodées en 64 bits au lieu d’être encodées en 32 bits, c’est donc autant de mémoire de perdue. Une JVM avec un tas de 48Go ne sera sans doute pas plus performante qu’une JVM paramétrée à 32Go. Nous avons donc observé la règle suivante : Une JVM pour 32Go de mémoire.
- 7. Optimisation 10 : Dédier des noeuds à la collecte des données. Le noeud qui reçoit la requête de search, réalise les opérations suivantes : 1. Parsing de la requête HTTP 2. Soumission de la requête à l’ensemble des noeuds de données 3. Collecte de l’ensemble des résultats 4. Agrégation des données reçues 5. Renvoi à l’émetteur Les étapes 3 et 4 ci-‐dessous sont d’autant plus consommatrices de CPU et de mémoire que le volume de données à renvoyer est important. Nous décidons de soulager les noeuds de données elasticsearch en mettant en frontal des noeuds clients chargés de réaliser les opérations 1, 3, 4 et 5 ci-‐dessus. La mémoire et la CPU des noeuds de données sont ainsi exclusivement dédiés au search. Noeud de données Noeud de données Noeud de données Noeud client HTTP Les attributs node.data et node.master ont la valeur "false" dans le fichier de configuration elasticsearh.yml pour les noeuds client qui n’hébergent pas de données et sont chargés exclusivement de soumettre les requêtes et de collecter puis agréger les résultats.