Enhanced Metadata - Digital Book World 2011

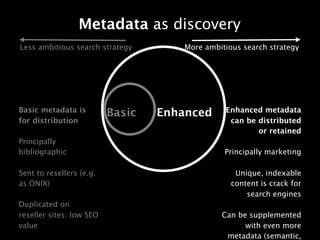
Q1. Metadata as discovery / Enhanced Metadata "Discovery" = search, by and large, with some recommendation stuff (social and other recommendations) thrown in. Looking at metadata and how publishers can use it to influence "discovery", there are two approaches. Both approaches are valid but which to choose depends on the ambitions of the publisher for developing a consumer-facing strategy, i.e. where they want to exploit digital channels to build direct relationships with readers, and possibly sell to them as well, but certainly to help influence their purchasing. (We happen to think that such a strategy is vital in 2011). The first is the less ambitious search (and direct to consumer) strategy. This is on the left hand side of the slide. In this approach, metadata is created by the publisher, usually at a pretty skeletal bibliographic level (ISBN, price, pub date, availability, description, jacket, author name and that's about it), and sent into the supply chain via ONIX, or retailer proprietary formats. All retailers get the same content. Those retailers place the content on their sites. The identical content gets indexed by search engines, who decide which page should come top on a search for the content included in that page, which usually goes to the biggest retailer, e.g. Amazon, who also attract a lot of inbound links, and supplement the metadata with their own content (reviews, tags, extracts etc) all of which contribute to a high page rank. Whilst a publisher probably has a system to get this content on their own site, it is not realistic to think that they will "win" any google searches as their sites do not have the residual page rank of the resellers. And for all sorts of reasons, they are unlikely to be able to price promote, so cannot convert any visitors they do attract. So the publisher's website exists in a kind of cul de sac. The second approach is for the ambitious publishers who wish to build a relationship with readers, and takes advantage of enhanced metadata to attract those readers and to win search queries. As in the first approach, basic metadata is distributed to the retailers. But, enhanced metadata is created on the publisher's own site. The metadata is in the form of "marketing" - extracts, reviews, longer author biographies, interviews, bonus material, videos, and audio. Content that is unique to the site, indexable to search engines (who *love* unique content) and rewarding to visitors. This content can be further supplemented algorithmically (e.g. through semantic web, linked open data) to produce an even richer site. Combined with a strong customer and sales proposition to reward visitors who come to the site, this approach can attract new visitors through discovery. And, users can then be directed to a number of third parties to make the sale. Q2. The importance of Identifiers and the Fate of the ISBN Basically: the ISBN has lots of good things going for it, principally that it exists, is adhered to and has been adopted by the industry. In the UK the shift to 13 digits was OK, people are familiar with it. But of course, as the industry changes massively, the limits of the ISBN show, and it begins to burst at the seams, with all sorts of people lobbying for changes (and their vested interests often showing). For example, a lot of resistance comes from the fact that (I think) Nielsen book data suggested creating separate ISBNs not just for ebooks, but for each format of ebook and each flavour of ebook DRM. Before you go into the cost of managing, inputting and administering (and accounting) for those in back office systems, you need to bear in mind that Nielsen administers ISBNs, and charges for each individual number.... The limits are very clear when you are trying to do things at a "Work" level. ISBNs only cater for editions, not works, which makes the creation of semantic data very difficult. There are endeavours to aggregate editions into works, some of

Recomendados
Más contenido relacionado
Último
Último (20)
Destacado
Destacado (20)
Enhanced Metadata - Digital Book World 2011
- 1. Metadata as discovery Less ambitious search strategy More ambitious search strategy Basic metadata is Enhanced metadata Basic Enhanced for distribution can be distributed or retained Principally bibliographic Principally marketing Sent to resellers (e.g. Unique, indexable as ONIX) content is crack for search engines Duplicated on reseller sites: low SEO Can be supplemented value with even more metadata (semantic,
- 2. The fate of ISBN