Warum NoSQL? Wann macht der Einsatz von NoSQL Datenbanken Sinn?
•Descargar como PPTX, PDF•
1 recomendación•1,768 vistas

Über einen Einsatz einer NoSQL-Datenbank (Not only SQL = nicht nur SQL) sollte überall dort nachgedacht werden, wo eine SQL-Datenbank an ihre Grenzen stößt oder zur Erfüllung der Aufgabe aufwändige architektonische Anpassungen notwendig wären, wie z. B. die Erstellung eines neuen Datenmodelles. In diesem Vortrag wird auf die spezifischen Unterschiede von NoSQL Datenbanken zu relationalen Datenbanken eingegangen. Darüber hinaus wird vermittelt bei welcher Art von Daten und Anwendungszenarien NoSQL Datenbanken Vorteile bieten. Kostenfreier Download: NoSQL for Dummies Book hier: http://info.marklogic.com/nosql-for-dummies.html. Für Fragen wenden Sie sich bitte an: info@marklogic.com

Recomendados
Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Similar a Warum NoSQL? Wann macht der Einsatz von NoSQL Datenbanken Sinn?
Similar a Warum NoSQL? Wann macht der Einsatz von NoSQL Datenbanken Sinn? (20)
Último
Último (20)
Warum NoSQL? Wann macht der Einsatz von NoSQL Datenbanken Sinn?
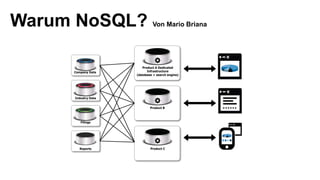
- 1. Warum NoSQL? Von Mario Briana Product A Dedicated Infrastructure (database + search engine) Product B Product C Company Data Industry Data Filings Reports
- 2. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 2 Relationale Datenbanken …
- 3. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 3 Schema beim Schreiben & Lesen Normalisierung um Redundanzen zu vermindern – 1:1, 1:Many, Many:Many Objekt-relationale Unverträglichkeit – Daten Objekte Neue Daten => neues Modell Skalierbarkeit Relationale Datenbanken
- 4. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 4 Profil Kontakt Daten Erfahrung Empfehlungen Media
- 5. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 5 ID MEMBER_NAME AGE ORG_ID 12 Grady Booch 59 442 133 Neeraj Gupta 23 934 348 Jose Cordova 37 115 ID ORG_SHORT_NM ORG_FULL_NM ORG_TYPE ORG_STATE 115 Sun Sun Microsystems corporation 09 442 IBM CE Lab International Business M… corporation 22 934 Stanford Stanford University Educational 09 ID ST_ABBR ST_NAME 09 CA California 22 HI Hawaii 33 TX Texas In welchem Staat wohnt Grady Booch?
- 6. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 6 Heterogene Daten sind eine echte Herausforderung
- 7. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 7 NoSQL Datenbanktypen Key-Value – Amazon Dynamo, Riak Dokumentenorientierte – MarkLogic, CouchDB, MongoDB Graphen – Neo4j, OrientDB Spaltenorientierte – Cassandra, BigTable, SimpleDB
- 8. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 8 NoSQL Datenbanktypen Key-Value – Amazon Dynamo, Riak Dokumentenorientierte – MarkLogic, CouchDB, MongoDB Graphen – Neo4j, OrientDB Spaltenorientierte – Cassandra, BigTable, SimpleDB
- 9. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 9 Dokumentenmodell – hierarchische Baumstruktur Profile Name Contact Info Email Experience Company Position Job Name State Recommendation
- 10. <profile> <name>Grady Booch</name> <contact-info> <email>grady@booch.com</email> <email>grady@ibm.com</email> </contact-info> <experience> <job current=“true”> <company> <name>IBM CE Lab</line1> <state>HI</zip> </company> <position>IBM Fellow</position> <recommendation>Grady is awesome</recommendation> </job> </experience> </profile> In welchem Staat wohnt Grady Booch? Dokumente sind “human readable” (xml)
- 11. { "profile": { "name": "Grady Booch", "contactInfo": { "emails": ["grady@booch.com", "grady@ibm.com"] }, "jobs": [{ "current": true, "company": { "name": "IBM CE Lab", "state": "HI" } "position": "IBM Fellow", "recommendation": "Grady is awesome" }] } } In welchem Staat wohnt Grady Booch? Dokumente sind “human readable” (json)
- 12. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 12 The Beauty of NoSQL Flexibles Datenmodell Einlesen der Daten (Ingest “as is”) Suchen und Abfragen
- 13. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 13 Iterativer Prozess Suchen & AbfragenIngest “as is” Anwendung MarkLogic ist “Schema flexibel”
- 14. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 14 The Only Enterprise NoSQL Database ACID Transaktionen Hochverfügbarkeit und Disaster Recovery Horizontale Skalierbarkeit und Elastzität Sicherheit Skalieberakeit und Elastitzität Semantische Daten Cloud Verfügbarket SEARCHDATABASE APPLICATION SERVICES
- 15. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 15 Situation “vor MarkLogic” PDF
- 16. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 16 Situation “Mit MarkLogic” – Darum NoSQL!
- 17. © COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED.SLIDE: 17 MarkLogic Architecture
- 18. Geospatial Support Full-text Search Flexible Indexes Native JSON Store Native XML Store Real-time Alerting Native RDF Triple Store Bitemporal Tiered Storage Fully Transactional Server-side JavaScript Hadoop and HDFS Cloud Ready (AWS) SQL Support Scalable and Elastic MarkLogic Content Pump REST API Samplestack Ad-hoc Queries Schema Agnostic XA Transactions 24/7 Engineering Support LDAP and Kerberos Security Security Certifications Configuration Management Monitoring and Management Performance at scale Customizable Failover Customizable Backup Atomic Forests Point-in-time Recovery ACID Transactions Index Across Data Types Flexible Replication Semantic Inference Multi-OS Support POWERFUL AGILE TRUSTED MarkLogic / Enterprise NoSQL Database Platform
- 19. WHAT WILL YOU REIMAGINE? MEHR INFORMATIONEN ERHALTEN SIE: MARKLOGIC.COM / INFO@MARKLOGIC.COM
Notas del editor
- Der Begriff NoSQL stammt aus 1998 Not Only SQL Bestrebung Daten ohne Einschränkungen des relationalen Modells zu speichern
- Relationale Datenbanken waren die Säulen der Software Architektur der letzten 25 Jahre. Ihre Bedeutung ist immer noch sehr hoch. Sie werden in allen Industrien eingesetzt und sind wichtige Bestandteile vieler „mission critical“ Lösungen. Transaktionssicherheit schützt vor Datenverlust. Im Clusterverbund wurden relationale Datenbanken zu einer ausfallsicheren Instanz der Enterprise Architektur. Sie waren eine Revolution nach der Mainframe Zeit, welche durch starre, hierarchische Datenbanken gekennzeichnet waren. Mit den relationalen Datenbanken wurde eine gemeinsame Abfragesprache SQL eingeführt und nun war es möglich mehrschichtige Client Server oder Browser basierte Architekturen zu entwickeln.
- Was sind die Hauptmerkmale von relationalen Datenbanken Die Repräsentation der Daten erfolgt über Tabellen und deren Beziehungen zueinander. Der Relationalität. Um Redundanzen zu vermeiden und teuren Festplatten Speicherplatz einzusparen werden die Daten normalisiert. Die hat Auswirkungen auf die Art und Weise wie Daten geschrieben, upgedatet und gelöscht werden. Um Daten schreiben zu können muss ein Schema mit Relationen, referrentieller Intigrität uvm. entwickelt werden. Dies muss vor der eigentlichen Entwicklungsarbeit begonnen werden. Für Software Entwickler und Architekten tritt damit ein Problem auf, welches in Englisch „Impedance Mismatch“ genant wird. Die objekt-relationale Unverträglichket. Dies bedeutet, dass die Objekte, die entwickelt werden nie dem Datenmodell und desseen Relationalität entsprechen. Um mit diesem Problem umzugehen werden Tools eingesetzt oder es kommen Datenbank Experten zum Einsatz, die über die Integrität der Datenbank wachen. Wenn sich die Anforderungen an die zu speichernden Daten durch veränderte Geschäftprozesse, Regularien oder Gesetze ändern muss das Modell geändert werden. Dies ist in vielen Projekten ein großer Kostenfaktor, da es viel Zeit für die Modellierung und dann weitere Entwicklungsarbeit erfordert. Typische Beispiele sind Integrations- oder Datawarehouse Projekte.
- Sehen wir uns mal ein Beispiel auf LinkedIn an. Sie sehen hier die Profilinformationen von Grady Booch einem international renommierten Architekten aus der “Gang of Four”. KLICK Kontaktinformationen KLICK Berufserfahrung KLICK und Empfehlungen anderer LinkedIn Mitglieder sind auch Bestandteil der Daten von Grady Booch. Die Heterogenität der Daten ist sehr gut erkkenbar und es wird deutlich das dies eher einem Dokument bzw. eingebetteten Dokumenten entspricht als Tabellen. KLICK Auch binäre Daten sind heterogener Bestandteil Informationen über Grady Booch. Schauen wir uns im nächsten Slide mal an, wie diese Daten in einem relationalen Modell gespeichert werden: KLICK
- SELECT ST_NAME FROM TABLE JOIN TABLE JOIN TABLE WHERE MEMBER_NAME = “Grady Booch” Um die Frage, “in welchem Staat wohnt Grady Booch” zu beantworten müssen Tabellen über sog. “Joins” in einer Abfrage verbunden werden. Die Daten wurden duch den Normalisierungsprozess aus Ihrem Kontext gerissen und müssen für die Beantwortung der Frage wieder zusammengesetzt werden. Klick
- Ein relationales Modell, wie hier dargestellt ist kein schwieriges Unterfangen, wenn man mit einer Softwareentwicklung und Modellierung beginnt. Änderungen der Anforderungen an die Daten bzw. Verarbeitungsprozesse lassen die Komplexität schnell anwachsen und es ist Realität, dass ein Model Solche (KLICK) Dimensionen annehmen kann. Es ist offensichtlich, dass es schwierig sein wird über einen längeren Zeitraum ein solches Modell anzupassen. Heterogene Daten sind eine echte Herausforderung für relationale Datenbanken. Somit sind wir bei der Frage “Warum NoSQL?” angekommen.
- Aufgrund unterschiedlichster Anforderungen vor allem großer Internetfirmen wie Amazon, Google oder Facebook wurden in den letzen Jahren NoSQL Datenbanken für unterschiedliche Einsetzzwecke entwickelt. Amazon hat beispielsweise festgestellt, dass sie für Ihren weltweiten Warenkatalog und den Warenkorb kommerzielle relationale System nicht verwenden konnten. Google benötigte für deren Geschäftsmodelle ebenso nicht-relationale Lösungen wie auch Facebook mit hunderten von Millionen Mitgliedern und deren unterschiedlichen Daten. In diesem Webcast gehen wir näher auf die Dokumentorientierte Datenbank von MarkLogic ein.
- Aufgrund unterschiedlichster Anforderungen vor allem großer Internetfirmen wie Amazon, Google oder Facebook wurden in den letzen Jahren NoSQL Datenbanken für unterschiedliche Einsetzzwecke entwickelt. Amazon hat beispielsweise festgestellt, dass sie für Ihren weltweiten Warenkatalog und den Warenkorb kommerzielle relationale System nicht verwenden konnten. Google benötigte für deren Geschäftsmodelle ebenso nicht-relationale Lösungen wie auch Facebook mit hunderten von Millionen Mitgliedern und deren unterschiedlichen Daten. In diesem Webcast gehen wir näher auf die Dokumentorientierte Datenbank von MarkLogic ein.
- Wenn Sie sich an das Beispiel von Grady Booch erinnern, werden Sie beim NoSQL dokumentenbasierten Ansatz feststellen, dass die Daten in einer Baumstruktur gespeichert werden.
- Die Daten sind “selbstbeschreibend” und Ihre Kontext ist klar und auch von “normalen Menschen” lesbar. Somit ist es sehr leicht, die Frage “in welchem Staat wohnt Grady Booch” zu beantworten. In diesem Beispiel sehen sie die Daten im XML Format repräsentiert. MarkLogic indiziert sowohl den Inhalt der Daten als auch die Elemente, die sie beschreiben. KLICK
- Die Indizierung macht die Dokumente leicht durchsuchbar. Hier eine Repräsentation der Daten im JSON Format. Der Kontext und die Durchsuchbarkeit reduzieren den Aufwand für Modellierung sehr deutlich. Die Informationen liegen als Dokumente in de-normalisierter Form vor. Somit ist der Aufwand die Daten zu Verfügung zu stellen deutlich geringer.
- The Beauty of NoSQL… löst das Problem heterogene Daten unterschiedlichster Art in die Datenbank “so wie sie sind” aufzunehmen und durchsuchbar zu machen. In MarkLogic werden die Daten während der Transaktion nicht nur gespeichert sondern auch indiziert und somit vor Datenverlust geschützt als auch eine schnelle und effiziente Such ermöglicht.
- Mit MarkLogic ist der Entwicklungsprozess iterativ. Die Daten werden mit geringem Modellierungsaufwand in die Datenbank aufgenommen und nach den Anforderungen der Anwendung indiziert und abfragbar gemacht. Der Anwendungsschicht stehen verschieden Schnittstellen zur Verfügung. Bestandteil des Application Server von MarkLogic sind REST Endpoints für das Erstellen und Manipulieren sowie das Suchen und Auffinden der Dokumente. Die Formate der Ergebnisse und die Metadaten zur Suche können als XML oder JSON geliefert werden Die empfohlene Architektur von MarkLogic ist eine mehrschichtige Architektur mit Middleware. Die durchgehende Verwendung von Javascript vonClient bis Server mit Frameworks wie beispielsweise Angular am Client und die Verwendung von Javascript im Middletier wie beispielsweise Node.js wird durch MarkLogic emöglicht. Javascript ist aber auch eine wichtige Option als Server seitige Abfragesprache. Selbsverständlich sind Schnittstellen für Java als auch .NET weitere ebenso wichtige Schnittstellen. Das NoSQL Modell, die Daten “wie sie sind” aufzunehmen wird of als “Schema agnostic” oder auch <KLICK> als Schema flexibel bezeichnet. Heterogene Daten sind ohne Schema aufnehmbar und indizierbar, dennoch ist es möglich, wenn dies den Anforderungen der Anweunge entspricht auch ein Schema anzuwenden. In jedem Fall profitiert die Anwendung von der Tranksations und Ausfallsicherheit von MarkLogic, dennn <KLICK>
- MarkLogic ist die einzige „Enterprise NOSQL Datenbank“ auf dem Markt. Dies hat vor kurzem auf die Firma Gartner in Ihrem „Magic Quadrant“ für Datenbank Management System festgellt. MarkLogic wurde nach der Kundenbefragung Als einzige NoSQL Hersteller im „Leading“ Quadranten gelistet. MarkLogic ist nicht nur eine Datenbank sondern auch eine Suchmaschine und stellt auch Application Server Funktionen – wie z.b. REST – zur Verfügung. Hochverfügbarkeit und Elastizität sind Fähigkeiten die in verschiedenen Industrien im Einsatz sind. Die reicht von Compliance Anwendungen bei Banken und Versicherungen bis hin zu Medienanwendungen, wie sie bei den Olympischen Spielen 2012 in London mit enormen Datenmengen verfügbar gemacht wurden. MarkLogic ist schon seit 14 Jahren auf dem Markt und ACID Transaktionen waren von Version 1 im Produkt. Die überwiegende Anzahl von Enterprise Funktionen sind seit vielen Jahren im Produkt und bei unseren Kunden im Einsatz. Chris Lindblad – der Gründer von MarkLogic – ist Suchexperte und seine Idee war vom ersten Tag an, nicht nur Dokumente durchsuch- und abfragbar zu machen, sondern auch exakte Ergebnisse ohne Datenverlust zur Verfügung zu stellen, welche die Wertschöpfung aus den gespeicherten Daten auf einer saklierbaren und sicheren Plattform ermöglicht. ACID und MVCC (kein Update in place) -> lock free read – no global write locks CAP theorem – wiki – don‘t go there
- Sehen wir uns einmal eine typische Situation bei einem Kunden an, wenn in einem Integrations Szenario mit relationalen Datenbanken gearbeitet werden muss. <KLICK> Im Unternehmen gibt es verschiedene Quellen mit heterogenen Daten, die integriert werden sollen, um ein Geschäftsproblem zu lösen. <KLICK> Um die verschiedenen Datenquellen mit den unterschiedlichen Formaten verarbeiten zu können müssen sich die technischen Projektbeteiligten auf ein Datenmodell einigen. <KLICK> Die Aufnahme der heterogenen Daten wird durch aufwendiges “Extrahieren, Transformieren und Laden (ETL)” bewerkstelligt. <KLICK> Jede Veränderung des Geschäftsmodells, die eine veränderte Datenhaltung erfodert – verlangt auch dessen Anpassung und die des ETL Prozesses.
- Bank1: real-time 24/7/365 single, unified, and accurate view of derivatives trades, the Bank: Replaced 20 Sybase databases with a single MarkLogic database Achieved a dramatic reduction in maintenance costs: 1 system versus 20, 1 DBA versus 5-10 Is seeing an ability to develop and deploy new software more quickly Bank2: The Bank built an equity research authoring and delivery solution based on MarkLogic Server MarkLogic enabled the Bank to offer clients up-to-date research on global developments ahead of the competition in their preferred delivery method. The firm achieved efficiency beyond its expectations. Development cycles shrunk to 3 to 4 weeks from 6 to12 months. More users are served with less infrastructure requirements. The single platform reduced total cost of ownership (TCO) by at least 50% over legacy technologies. Mit MarkLogic konnten zum Beispiel auf einer Handlesplatform für Derivate einer unserer Investment Bank Kunden die Kosten für Wartung des System deutlich gesenkt werden, da statt 20 verschiedenen Systeme zu betreiben nur noch eine Platform betrieben werden muss. Die MarkLogic Platform ermöglicht der Bank schneller Lösungen zu entwickeln und zur Verfügung zu stellen und somit den sich verändernden Regularien und Geschäftsprozessen anzupassen. Beispielsweise wurden die Entwicklungszyklen von 6-12 Monaten auf 3 bis 4 Wochen verkürzt. Es konnten mehr Nutzer mit weniger Infrastrukturaufwand bedient werden.
- Hier nochmal ein Überblick über die Architektur von MarkLogic Server, der in der Version 8 zur Verfügung steht. Neben den zentralen Services für das Suchen und Indizieren stehen auch Services für Sicherheit, Kontrolle und Monitoring bereit. Neben den bereits gezeigten Datenformaten XML und JSON können sowohl semantische als auch Geodaten gespeichert werden. Für Anwendungen, die Geoinformationen verarbeiten - stehen umfangreiche Funktionen und Indizes zur Verfügung Eine weiteres unterstützes Datenformat sind sogenannte RDF (Resource Description Format) Triples oder auch semantische Daten. Die Speicherung semantischer Informationen erlaubt es zu definieren, ob es sich beispielsweise bei dem Begriff “Bremen” um den Namen der Stadt oder vielleicht eines Schiffs oder den Nachnamen einer Person handelt. Darüberhinaus ist es möglich semantische Schlussfolgerungen zu ziehen. Beispiel: Wenn Herr Meyer in Berlin lebtt und Berlin in Deutschland ist –> lebt Herr Meyer in Deutschland Neben der umfgangreichen Palette an Szenarien für die effiziente Speicherung heterogener Daten ist auch der Kostenfaktor für die Skalierung ein wichtiges Element, welchem die Architektur Rechnung trägt. Es ist möglich die Daten – auf Medien mit differenzierter Kostenstruktur – entsprechend ihres Verwendungszwecks zu speichern. Dies heist, Daten im ständigen Zugriff werden auf schnellen Medien mit kurzem Zugriffsweg gespeichert, während archivierte Daten auf konstengünstigen Medien ausgelagert werden.
- 14 years of development Orange ML8 MarkLogic ist seit dem Jahr 2001 auf dem Markt und viele der Enterprise Funktionen – wie ACID Transaktionen – sind vom ersten Release an im Produkt enthalten. MarkLogic ist eine integrierte Platform für das Speichern, Suchen von heterogenen Daten und ein Applikationsserver mit modernen Schnittstellen. Mit MarkLogic 8 wurden wichtige neue Funktionen hinzugefügt, um den Anforderungen und Wünschen unserer Kunden und Partner gerecht zu werden. Einige dieser Funktionen werden wir in weiteren Webcasts näher vorsellen. Man muss keine zusätzlichen Produkte kaufen, um bestimme Funktionalität zu bekommen.
- Vielen Dank für Ihre Aufmerksamkeit
- MarkLogic ist schon seit 14 Jahren auf dem Markt ACID war von Version 1 im Produkt Die überwiegende Anzahl von Funktionen sind seit vielen Jahren im Produkt und bei unseren Kunden im Einsatz ACID und MVCC (kein Update in place) -> lock free read – no global write locks CAP theorem – wiki – don‘t go there