Building a data warehouse with AWS Redshift, Matillion and Yellowfin
•Descargar como PPT, PDF•
2 recomendaciones•1,978 vistas

screencast of the process to set up a data warehouse with AWS Redshift along with Matillion ETL and Yellowfin for data visualization

Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Similar a Building a data warehouse with AWS Redshift, Matillion and Yellowfin
Similar a Building a data warehouse with AWS Redshift, Matillion and Yellowfin (20)
Más de Lynn Langit
Más de Lynn Langit (20)
Último
Último (20)
Building a data warehouse with AWS Redshift, Matillion and Yellowfin
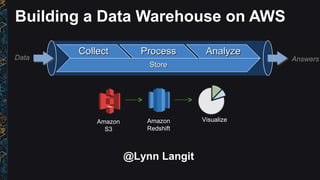
- 1. Building a Data Warehouse on AWS Amazon S3 Amazon Redshift CollectCollect ProcessProcess AnalyzeAnalyze StoreStore Data Answers Visualize @Lynn Langit
- 2. AWS Marketplace Enterprise software store for business users who need simplified procurement •2000+ product listings •to browse, test and buy software •1-click deployment •to launch, in multiple regions around the world •Pay-as-you-go pricing •to use on demand Advanced Analytics Data Enablement Business Intelligence
- 3. Building a Data Warehouse on AWS Move data into Redshift from S3 for analysis Amazon S3 Amazon Redshift AWS Marketplace Partners Matillion Visualize Yellowfin CollectCollect ProcessProcess AnalyzeAnalyze StoreStore Data Answers
- 4. Setup
- 5. Our Scenario and Source Files File Types -- Text - .csv -- Compressed - .gz File Categories Details / Events -- Flights -- Weather Metadata -- Airports -- Carriers “In this scenario we will use Matillion ETL for Redshift to prepare two separate data sources ready for analysis. The sample data is US airport flight information from 1995 -> 2008. Every flight to or from a US airport (and whether it left on time or not) is included. The second data set is weather data, taken from NOAA, including the daily weather readings for each US Airport.”
- 6. Loading data from S3 in to Redshift
- 7. Using Matillion ETL for Redshift • Create Instance (AMI/EC2) of Matillion/AWS Marketplace • Connect Matillion to Redshift
- 9. Table distribution styles Distribution Key All Node 1 Slice 1 Slice 1 Slice 2 Slice 2 Node 2 Slice 3 Slice 3 Slice 4 Slice 4 Node 1 Slice 1 Slice 1 Slice 2 Slice 2 Node 2 Slice 3 Slice 3 Slice 4 Slice 4 key1 key2 key3 key4 All data on every node Same key to same location Node 1 Slice 1 Slice 1 Slice 2 Slice 2 Node 2 Slice 3 Slice 3 Slice 4 Slice 4 Even Round robin distribution
- 10. Sort Keys • Single Column - [ SORTKEY ( date ) ] • Queries that use 1st column (i.e. date) as primary filter • Compound - [ SORTKEY COMPOUND ( date, region, country) ] • Queries that use 1st column as primary filter, then other columns • Interleaved - [ SORTKEY INTERLEAVED ( date, region, country) ] • Queries that use different columns in filter
- 11. Time Series Data – Vacuum Operation Unsorted Region Sorted Region Sorted Sorted Sorted Append in Sort Key Order Sort Unsorted Region Merge
Notas del editor
- Collect logs in an Amazon Kinesis Stream Launch Amazon EMR and Amazon Redshift clusters Use Hive on Amazon EMR to access data in an Amazon Kinesis stream Use Hive on Amazon EMR to transform, partition and output data to Amazon S3 Load data in parallel into Amazon Redshift from Amazon S3 Bonus: use Hive and Amazon DynamoDB to enable Amazon Kinesis “checkpointing”
- Big Data software on AWS Marketplace:http://amzn.to/1va4KQ6
- Public data from -- s3://demo-data-sets-west/airline/data/
- http://docs.aws.amazon.com/general/latest/gr/rande.html http://docs.aws.amazon.com/redshift/latest/dg/r_STV_SLICES.html
- Redshift is a distributed system: A cluster contains a leader node and compute nodes A compute node contains slices (one per core) that contain data Data is distributed among slices in 3 ways: Even – Rows distributed in Round Robin fashion (default) Key – Rows distributed based on a distribution key (hash of a defined column) All - Rows distributed to all slices Queries run on all slices in parallel Optimal query throughput can be achieved when data is evenly spread across slices
- When you append data, it’s appended to the unsorted region in sorted order When you vacuum, the unsorted region is sorted first, then merged into the sorted regions This can be really expensive If you append data only in the order of your sortkeys, you’ll never have to vacuum Mycroft does this automatically