Notes for SEO Analyst, SEO, SEM, Web Analyst, Webmaster, Online Marketing Guy, Internet Marketing Guys
•
5 recomendaciones•5,876 vistas

This document summarizes 17 factors that search engines use to determine the value of a link when evaluating websites for ranking. It begins by explaining the importance of external links over internal links. It then lists factors like anchor text, PageRank, the page or domain authority of the linking page, and TrustRank - whether the linking page is considered a good or spammy site. The document provides details on each factor and how they influence search engine rankings.

Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Similar a Notes for SEO Analyst, SEO, SEM, Web Analyst, Webmaster, Online Marketing Guy, Internet Marketing Guys
Similar a Notes for SEO Analyst, SEO, SEM, Web Analyst, Webmaster, Online Marketing Guy, Internet Marketing Guys (20)
Último
Último (20)
Notes for SEO Analyst, SEO, SEM, Web Analyst, Webmaster, Online Marketing Guy, Internet Marketing Guys
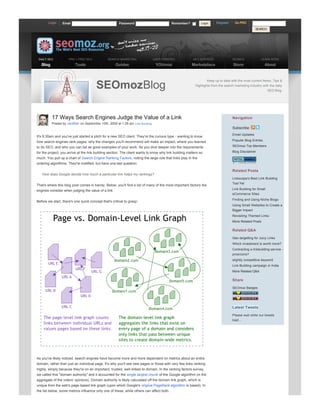
- 1. Login Email Password Remember? g Login c d e f Register Go PRO SEARCH DAILY SEO PRO + FREE SEO SEARCH MARKETING USER POWERED SEO SERVICES SEOMOZ LEARN MORE Blog Tools Guides YOUmoz Marketplace Store About Keep up to date with the most current News, Tips & SEOmozBlog Highlights from the search marketing industry with the daily SEO Blog. 17 Ways Search Engines Judge the Value of a Link Navigation Posted by randfish on September 10th, 2009 at 1:28 am Link Building Subscribe Email Updates It's 9:30am and you've just started a pitch for a new SEO client. They're the curious type wanting to know how search engines rank pages, why the changes you'll recommend will make an impact, where you learned Popular Blog Entries to do SEO, and who you can list as good examples of your work. As you dive deeper into the requirements SEOmoz Top Members for the project, you arrive at the link building section. The client wants to know why link building matters so Blog Disclaimer much. You pull up a chart of Search Engine Ranking Factors, noting the large role that links play in the ordering algorithms. They're mollified, but have one last question: Related Posts How does Google decide how much a particular link helps my rankings? Linkscape's Best Link Building Tool Yet That's where this blog post comes in handy. Below, you'll find a list of many of the most important factors the engines consider when judging the value of a link. Link Building for Small eCommerce Sites Finding and Using Niche Blogs Before we start, there's one quick concept that's critical to grasp: Using Small Websites to Create a Bigger Impact Revisiting Themed Links More Related Posts Related Q&A Geotargetting for Juicy Links Which investment is worth more? Contracting a linkbuilding service pros/cons? slightly competitive keyword Link Building campaign in India More Related Q&A Share SEOmoz Badges Latest Tweets Please wait while our tweets load... As you've likely noticed, search engines have become more and more dependent on metrics about an entire domain, rather than just an individual page. It's why you'll see new pages or those with very few links ranking highly, simply because they're on an important, trusted, well linkedto domain. In the ranking factors survey, we called this "domain authority" and it accounted for the single largest chunk of the Google algorithm (in the aggregate of the voters' opinions). Domain authority is likely calculated off the domain link graph, which is unique from the web's pagebased link graph (upon which Google's original PageRank algorithm is based). In the list below, some metrics influence only one of these, while others can affect both. #1 Internal vs. External
- 3. An obvious one for those in the SEO business, anchor text is one of the biggest factors in the rankings equation overall, so it's no surprise it features prominently in the attributes of a link that engines consider. In our experiments (and from lots of experience), it appears that "exact match" anchor text is more beneficial than simply inclusion of the target keywords in an anchor text phrase. On a personal note, it's my opinion that the engines won't always bias in this fashion; it seems to me that, particularly for generic (nonbranded) keyword phrases, this is the cause of a lot of manipulation and abuse in the SERPs. #3 PageRank Whether they call it StaticRank (Microsoft's metric), WebRank (Yahoo!'s), PageRank (Google's) or mozRank (Linkscape's), some form of an iterative, Markovchain based link analysis algorithm is a part of all the engines' ranking systems. PageRank et al. uses the analogy that links are votes and that those pages which have more votes have more influence with the votes they cast. The nuances of PageRank are well covered in The Professional's Guide to PageRank Optimization, but, at a minimum, understanding of the general concepts is critical to being an effective SEO: 1. Every URL is assigned a tiny, innate quantity of PageRank 2. If there are "n" links on a page, each link passes that page's PageRank divided by "n" (and thus, the more links, the lower the amount of PageRank each one flows) 3. An iterative calculation that flows juice through the web's entire link graph dozens of times is used to reach the calculations for each URL's ranking score 4. Representations like those shown in Google's toolbar PageRank or SEOmoz's mozRank on a 0 10 scale are logarithmic (thus, a PageRank/mozRank 4 has 810X the link importance than a PR/mR 3) PageRank can be calculated on the pagelevel link graph, assigning PageRank scores to individual URLs, but it can also apply to the domainlevel link graph, which is how metrics like Domain mozRank (DmR) are derived. By counting only links between domains (and, to make a crude analogy, squishing together all of the pages on a site into a single list of all the unique domains that site points to), Domain mozRank (and the search engine equivalents) can be used to determine the importance of an entire site (which is likely to be at least a piece of how overall domain authority is generated). #4 TrustRank The basics of TrustRank are described in this paper from Stanford Combatting Webspam with TrustRank. The basic tenet of TrustRank is that the web's "good" and "trustworthy" pages tend to be closely linked
- 5. These can include (but are certainly not limited to): l A large number of shared, reciprocated links l Domain registration data l Shared hosting IP address or IP address Cblocks l Public acquisition/relationship information l Publicized marketing agreements that can be machineread and interpreted If the engines determine that a preexisting relationship of some kind could inhibit the "editorial" quality of a link passing between two sites, they may choose to discount or even ignore these. Anecdotal evidence that links shared between "networks" of websites pass little value (particularly the classic SEO strategy of "sitewide" links) is one point many in the organic search field point to on this topic. #8 Location on the Page Microsoft was the first engine to reveal public data about their plans to do "block level" analysis (in an MS Research piece on VIPS VIsionbased Page Segmentation). Since then, many SEOs have reported observing the impact of analysis like this from Google & Yahoo! as well. It appears to us at SEOmoz, for example, that internal links in the footer of web pages may not provide the same beneficial results that those same links will when placed into top/header navigation. Others have reported that one way the engines appear to be fighting pervasive link advertising is by diminishing the value that external links carry from the sidebar or footer of web pages. SEOs tend to agree on one point that links from the "content" of a piece is most valuable, both from the value the link passes for rankings and, fortuitously, for clickthrough traffic as well. #9 Topical Relevance There are numerous ways the engines can run topical analysis to determine whether two pages (or sites) cover similar subject matter. Years ago, Google Labs featured an automatic classification tool that could predict, based on a URL, the category and subcategory for virtually any type of content (from medical to real estate, marketing, sports and dozens more). It's possible that engines may use these automated topical classification systems to identify "neighbourhoods" around particular topics and count links more or less based on the behaviour they see as accretive to their quality of ranking results. I personally don't worry too much about topical relevance if you can get a link from a topic agnostic site (like NYTimes.com) or a very specific blog on a completely unrelated subject (maybe because they happen to like something you published), I'm bullish that these "nontopicspecific" endorsements are likely to still pass positive value. I think it's somewhat more likely that the engines might evaluate potential spam or manipulative links based on these analyses. A site that's never previously linked to pharmaceutical, gambling or adult topic regions may appear as an outlier on the link graph in potential spam scenarios. #10 Content & Context Assessment
- 6. or adult topic regions may appear as an outlier on the link graph in potential spam scenarios. #10 Content & Context Assessment Though topical relevance can provide useful information for engines about linking relationships, it's possible that the content and context of a link may be even more useful in determining the value it should pass from the source to the target. In content/context analysis, the engines attempt to discern, in a machine parseable way, why a link exists on a page. When links are meant editorially, certain patterns arise. They tend to be embedded in the content, link to relevant sources, use accepted norms for HTML structure, word usage, phrasing, language, etc. Through detailed patternmatching and, potentially, machine learning on large data sets, the engines may be able to form distinctions about what constitutes a "legitimate" and "editorially given" link that's intended as an endorsement vs. those that may be placed surreptitiously (through hacking), those that are the result of content licensing (but carry little other weight), those that are payforplacement, etc. #11 Geographic Location The geography of a link is highly dependent on the perceived location of its host, but the engines, particularly Google, have been getting increasingly sophisticated about employing data points to pinpoint the location relevance of a root domain, subdomain or subfolder. These can include: l The host IP address location l The countrycode TLD extension (.de, .co.uk, etc) l The language of the content l Registration with local search systems and/or regional directories l Association with a physical address l The geographic location of links to that site/section Earning links from a page/site targeted to a particular region may help that page (or your entire site) to perform better in that region's searches. Likewise, if your link profile is strongly biased to a particular region, it may be difficult to appear prominently in another, even if other locationidentifying data is present (such as hosting IP address, domain extension, etc). #12 Use of Rel="Nofollow" Although in the SEO world it feels like a lifetime ago since nofollow appeared, it's actually only been around since January of 2005, when Google announced it was adopting support for the new HTML tag. Very simply, rel="nofollow", when attached to a link, tells the engines not to ascribe any of the editorial endorsements or "votes" that would boost a page/site's query independent ranking metrics. Today, Linkscape's index notes that approximately 3% of all links on the web are nofollowed, and that of these, more than half are sites using nofollow on internal, rather than external pointing links.
- 7. "votes" that would boost a page/site's query independent ranking metrics. Today, Linkscape's index notes that approximately 3% of all links on the web are nofollowed, and that of these, more than half are sites using nofollow on internal, rather than external pointing links. Some question exists in the SEO field as to whether, and how strictly, each individual engine follows this protocol. It's often been purported, for example, that Google may still pass some citation quality through Wikipedia's external links, despite the use of nofollow. #13 Link Type Links can come in a variety of formats. The big three are: 1. Straight HTML Text Links 2. Image Links 3. Javascript Links Google recently announced that they're not only crawling this third group, but passing link endorsement metrics through them (which has many upset about the reversal in policy about using Javascript as a way to delineate paid/advertising links). For years now, they've also treated the text in an image's alt attribute in a similar fashion to how anchor text is handled in standard text links. However, not all links are treated equally. In both anecdotal examples and testing, it appears that straight, HTML links with standard anchor text pass the most value, followed by image links with keywordrich alt text and finally, Javascript links (which still aren't universally followed or considered as an endorsement, at least in our experience). Link builders, content licensers, badge and widget creators and those who enable embeddable content should all, in my opinion, assume the worst about the engines' ability to handle and pass value from nonstandard links and aim to get HTML text links with good anchor text as an optimal methodology. #14 Other Link Targets on the Source Page When a page links out externally, both the quantity and targets of the other links that exist on that page may be taken into account by the engines when determining how much link juice should pass. As we've already mentioned above (in item #3), the "PageRank"like algorithms from all the engines (and SEOmoz's mozRank) divide the amount of juice passed by any given page by the number of links on that page. In addition to this metric, the engines may also consider the quantity of external domains a page points to as a way to judge the quality and value of those endorsements. If, for example, a page links to only a few external resources on a particular topic, spread out amongst the content, that may be perceived differently than a long list of links pointing to many different external sites. One is not necessarily better or worse than the other, but it's possible the engines may pass greater endorsement through one model than another (and could use a system like this to devalue the links sent from what they perceive to be low value add directories).
- 8. points to as a way to judge the quality and value of those endorsements. If, for example, a page links to only a few external resources on a particular topic, spread out amongst the content, that may be perceived differently than a long list of links pointing to many different external sites. One is not necessarily better or worse than the other, but it's possible the engines may pass greater endorsement through one model than another (and could use a system like this to devalue the links sent from what they perceive to be low value add directories). The engines are also very likely to be looking at who else a linking page endorses. Having a link from a page that also links to low quality pages that may be considered spam is almost certainly less valuable than receiving links from pages that endorse and link out to high quality, reputable domains and URLs. #15 Domain, Page & LinkSpecific Penalties As nearly everyone in the SEO business is aware (though those in the tech media may still be a bit behind), search engines apply penalties to sites and pages ranging from the loss of the ability to pass link juice/endorsement all the way up to a full ban from their indices. If a page or site has lost its ability to pass link endorsements, acquiring links from it provides no algorithmic value for search rankings. Be aware that the engines sometimes show penalties publicly (inability to rank for obvious title/URL matches, lowered PageRank scores, etc.) but continue to keep these penalties inconsistent so systemic manipulators can't acquire solid data points about who can gets "hit" vs. not. #16 Content/Embed Patterns As content licensing & distribution, widgets, badges and distributed, embeddable linksincontent become more prevalent across the web, the engines have begun looking for ways to avoid becoming inundated by these tactics. I don't believe that the engines don't want to count the vast majority of links that employ these systems, but they're also wary about overcounting or overrepresenting sites that simply do a good job getting distribution of a single badge/widget/embed/licensingdeal. To that end, here at SEOmoz, we think it's likely that content pattern detection and link pattern detection plays a role in how the engines evaluate link diversity and quality. If the search engines see, for example, the same piece of content with the same link across thousands of sites, that may not signal the same level of endorsement that a diversity of unique link types and surrounding content would provide. The "editorial" nature of a highly similar snippet compared to those of clearly unique, selfgenerated links may be debatable, but from the engines' perspectives, being able to identify and potentially filter links using these attributes is a smart way to futureproof against manipulation. #17 Temporal / Historical Data Timing and data about the appearance of links is the final point on this checklist. As the engines crawl the web and see patterns about how new sites, new pages and old stalwarts earn links, they can use this data to help fight spam, identify authority and relevance and even deliver greater freshness for pages that are rising quickly in link acquisition. How the engines use these patterns of link attraction is up for debate and speculation, but the data is almost certainly being consumed, processed and exploited to help ranking algorithms do a better job of surfacing the best possible results (and reducing the abilities of spam especially large link purchases or exploits to have an impact on the rankings). While the list above includes many data points, it's almost certainly not comprehensive. Please feel free to suggest others that belong here in the comments below. Do you like this post? 48 Yes No 54 thumbs up and 3 thumbs down User Comments Add Comment Hide Comments Michael Sparer September 10th, 2009 at 1:59 am I'd really like to know how long #11 (Geographic location) based on the server's IP address will be important for search rankings. As more and more webapplications move into "the cloud" and thus getting IPs from ranges of big cloud providers such as amazon, which are mainly hosted in the US or UK, I don't think that GYM will put much weight on it in the future.
- 9. Michael Sparer September 10th, 2009 at 1:59 am I'd really like to know how long #11 (Geographic location) based on the server's IP address will be important for search rankings. As more and more webapplications move into "the cloud" and thus getting IPs from ranges of big cloud providers such as amazon, which are mainly hosted in the US or UK, I don't think that GYM will put much weight on it in the future. Furthermore the trend seems to go into mirroring the content to various locations spread around the globe (such as amazon's cloud front does) which then serve the content based on the vicinity of the client's IPs, resulting in faster response times and a faster web experience for users ... and that's one of google's current incentives isn't it (e.g. PageSpeed)? By the way I posted a question to Matt Cutts on the google moderator page about exactly that IP address / cloud problem ... but didn't get an answer yet. If you're interested, maybe it'll help if you vote it up : ) 3 up, 0 down Reply Permalink mnnorge September 10th, 2009 at 2:10 am Very interesting topic Rand Fishkin. This blog post will be sent to all our SEOs and memorized. 1 up, 0 down Reply Permalink Mikkel deMib Svendsen September 10th, 2009 at 2:36 am Just a small correction to #12 ... rel=NOFOLLOW is not really a new HTMLtag but rather a new attribute value. rel= is not new only the NOFOLLOW value :) 4 up, 0 down Reply Permalink twentysix Search September 10th, 2009 at 3:09 am Absolutely. I know how annoying it is to constantly correct / be corrected on precise terminology, but I think it's equally important that in an industry which is so segmented between SEOs, developers, socials, marketers, designers etc, that we're as absolutely clear and consistant with our use of terminology as possible in order to minimise the already extensive amounts of confusion that exist in communicating cross department/expertise... Edited by twentysix Search on September 10th, 2009 at 3:10 am 1 up, 0 down Reply Permalink umseo September 10th, 2009 at 2:54 am Great article. It covers pretty much all aspects of links in SEO. 1 up, 0 down Reply Permalink davidodonnell September 10th, 2009 at 3:17 am Great resource for training link builders. Props to whatever/whoever you use for creating graphics. Illustrating the point really helps when explaining link value concepts. Edited by davidodonnell on September 10th, 2009 at 3:19 am 2 up, 0 down Reply Permalink
- 10. really helps when explaining link value concepts. Edited by davidodonnell on September 10th, 2009 at 3:19 am 2 up, 0 down Reply Permalink philou2803 September 10th, 2009 at 3:44 am That's a great long post Rand. Well done for this one. I agree with you about the anchior text policy. Search engines could change the way they look at it. I think Exact Match anchor text does not look natural. 1 up, 0 down Reply Permalink Springboard SEO September 10th, 2009 at 3:46 am Sweet write up Rand! (How original, I know...) Thorough resource pages like this one are so handy in catching some of the obviousyeteasy toforget optimization factors. I wrote a page on measuring quality backlinks last month, in which I added Mozrank and Trustrank to the list of important factors determining link quality. Seems I forgot to mention 'geographic location', 'link types', and 'other link targets', though :o Thanks! Edited by Springboard SEO on September 10th, 2009 at 4:30 am 1 up, 1 down Reply Permalink adders September 10th, 2009 at 3:54 am If someone had asked me how many different ways there was for a search engine to look at a link I'm pretty sure I would have given a number way lower than 17! Although I guess it all depends how you break it down. Really useful break down though :) thumbs ^ 1 up, 0 down Reply Permalink Neyne September 10th, 2009 at 4:47 am Hey Rand, Great roundup. Just to add a bit more to the point you made at the end of the #12 point, it is not true that Google will not pass any link metrics through a nofollowed link. In an experiment I performed with two links pointing to the same target from the same page, the first link passed anchor text even when nofollowed. I wrote more about it here: http://www.seoscientist.com/firstlinkcounted rebunked.html Cheers Branko Edited by Neyne on September 10th, 2009 at 4:57 am 2 up, 1 down Reply Permalink
- 11. Edited by Neyne on September 10th, 2009 at 4:57 am 2 up, 1 down Reply Permalink James Lowery September 10th, 2009 at 6:52 am rel="nofollow" links show up in the back link information in GWT, and Googlebot does appear to follow this type of link to discover new information. To my mind, nofollow is a bit of a misnomer, perhaps rel="nocount" or rel="novalue" would have been more accurate names. 1 up, 0 down Reply Permalink Robert Enriquez September 10th, 2009 at 4:59 am Exatch match is the way to go most of the times. Google loves exact match domains, and they also love exact match anchor text. 1 up, 0 down Reply Permalink Springboard SEO September 10th, 2009 at 5:23 am I find exact match domaining to be less effective that it was, say 3 years ago. In fact, I had an exact match domain for my main SEO site until June, at which point I moved to a more brandable "half match" domain. I'm doing better on local rankings since removing half of the exact match equation. Even if exact matches did provide the same edge rank wise as they did a few years ago, I'd still opt for an extra layer of brandability over a couple of spots on the SERPs. 1 up, 0 down Reply Permalink Robert Enriquez September 10th, 2009 at 6:08 am I have used and still use exact match for highly competitive commercial terms. They still rank on page 1 with little work on and off page. They're also a 2nd part of getting another domain on page 1 of Google. Great 2nd strategy that helps out in a lot of ways. 1 up, 0 down Reply Permalink SEODoctor September 10th, 2009 at 5:26 am Isn't #4 & #5 the same thing? Domain Authority and Trust. This ones gonna need a few re reads to get the most out of it. 1 up, 0 down Reply Permalink goodnewscowboy
- 12. Reply Permalink goodnewscowboy September 10th, 2009 at 5:36 am Hey Rand. Another crystal clear post that's getting printed out. Honestly, between products like Linkscape and articles like this, you should be registering the name LINKmoz.org. The information that's available here at SEOmoz has been getting better and better, and I find myself marking many of the other RSS feeds I used to read regularly as read without actually reading them. I'm finding more and more substance from SEOmoz, and more and more fluff elsewhere. I'm really gonna have to break down one of these days and reclaim my pro membership... 1 up, 0 down Reply Permalink gohewitt September 10th, 2009 at 5:52 am Absolutely one of the greatest SEO posts Ive ever read! Thank you for this outstanding information, I feel like I just learned about 5 new things that I had never thought of before! You guys are like the kings of SEO! 1 up, 0 down Reply Permalink BarryB September 10th, 2009 at 6:18 am Great information. We have been working with exact match as well while changing it up once in a while to "look" natural butwondering if we are diluting the overall link profile of the page. 1 up, 0 down Reply Permalink The Perfect Wedding September 10th, 2009 at 6:29 am Guys I have one question that keeps stricking me every time I talk with people about PR referred to in #3 Does a pagina lose PR if they link out to other sources? Cause if something flows, something is going out/away. Or is the page keeping it's strength? and only the specific links have a dampeningfactor? 2 up, 0 down Reply Permalink nicchenet September 10th, 2009 at 6:43 am There's a lot of buzz about whether or not it is a bad idea to post external links on your website, Wedding. My feeling is that linking to certain external sites with authoritative qualities [i.e. a .gov website or a .edu that is topically relevant to my website] may actually give MY site a boost in PR, mozTrust, etc. Of course, I go back and forth on this issue, but for the most part, I no longer see a need to nofollow all external links there's value in building a relationship with authoritative sites in my niche. 1 up, 0 down Reply Permalink Steph Woods
- 13. 1 up, 0 down Reply Permalink Steph Woods September 10th, 2009 at 12:04 pm I agree with nichenet. Linking out to other authoratative (and relevant) sites reflects positively on your own site. I also believe that external linking shows the search engines that you are attempting to provide readers with valuable and relevant information. At the end of the day, that is what search engines are attempting to do: provide users with the most relevant search results based on a searcher's query. 1 up, 0 down Reply Permalink Highbeam Research September 10th, 2009 at 9:31 am The way I understand it is every page, once metrics are assigned, has a % of its real page rank that is can spend in whatever way it wants. So if a site wants to link out to trusted sites in their industry and use this page rank in that way then it can. Or if they choose to spend that juice internally to other relevant pages then they can do that as well. There are benefits to both. The only thing I would be careful of is linking to competitors with good anchor text as you don ’t want to help them gain relevancy for competitive keywords. 1 up, 0 down Reply Permalink jennita September 10th, 2009 at 8:30 pm As SEO's I believe we often overthink everything. If it makes sense to link to another source (one that you trust isn't spam) then link to it. 1 up, 0 down Reply Permalink rui.jiang September 10th, 2009 at 7:10 am wow, I just had a feeling that something big will come up today. Great post, rand, it's really really comprehensive and pretty much covered everything about link value 1 up, 0 down Reply Permalink seo wizz September 10th, 2009 at 7:16 am Ever since Matt Cutts comment on 'editorial' type links I have been carrying out various tests trying to establish the exact effect of naturally given links built into content, for example a blog post. The results so far have been very positive with some pages moving up 2 pages on Google by simply applying some anchor targeted links in the content of a blog post. A fairly new link building tactic is offering sites unique content for an anchored link back to your site, this might be a great idea if Google are going to give so much weight to editorial links. Great article, covers all the bases and a little more. 2 up, 0 down Reply Permalink
- 14. Great article, covers all the bases and a little more. 2 up, 0 down Reply Permalink Dr. Pete September 10th, 2009 at 7:46 am I hate to leave a fan boy comment, but this is really a great resource. It's clear, both from clients and the Q&A here on the site, that many people still have a very narrow view of link building, usually focusing on quantity over quality (or, at best, one very small aspect of quality). The algos are becoming more complex every day, and a one trickpony approach to SEO just doesn't cut it anymore. 1 up, 0 down Reply Permalink rorycarlyle September 10th, 2009 at 7:55 am My internet induced ADD didn't allow me to focus properly on this post it's long. I'll need a few rereads to make this all stick. I've got most of this down, but 17 is an impressive amount of link factors. Thanks, Rand. 1 up, 0 down Reply Permalink James Svoboda September 10th, 2009 at 8:07 am Even though this list is extremely through, there seems to be no mention of the RankRank ® metric that was at first a cornerstone of the Webfluence linking formula and is rumored to have recently made it's way into the Googoritm; ) On a more serious note there are a few other coding issues and server directives that can affect link juice or “link visibility”: l robots.txt instructions l .htaccess, 301, 302 & 404 l Meta Index & Follow tags l Canonical tags and Duplicate content l Framed & Iframe pages l Links embedded in Flash and Silverlight l Word, Excel and PDF docs that contain links Also, really great post! Edited by James Svoboda on September 10th, 2009 at 8:09 am 4 up, 0 down Reply Permalink garypool September 10th, 2009 at 8:10 am Thanks Rand, More tools for my client explanation arsenal. Keep 'em comming. 1 up, 0 down Reply Permalink vizioninteractive
- 15. Reply Permalink vizioninteractive September 10th, 2009 at 8:17 am Great overview post, Rand. I believe you've touched on just about everything there is to say about links. Personally, I am definitely seeing good results when link building and targeting many different domains rather than links from the same sites. Diversity is a good thing. Not sure if you technically mentioned it above, but links in the middle of a sentence seem to be given more weight...rather than some anchor text link in a sidebar. Definitely worthy to note. I also have seen evidence that links from pages that have a lot of traffic tend to help, as well, even if they're nofollow links. 1 up, 0 down Reply Permalink carfeu September 10th, 2009 at 9:27 am Great post. I would be curious to know if a link to a page was incorrect but still worked (using for instance upper rather than lowercase) if the engines would frown upon it somewhat? Oh... and with HTML5 links in content will be valued far more, because by then the spider can understand much better what the main content is and what is not. Edited by carfeu on September 10th, 2009 at 9:28 am 3 up, 0 down Reply Permalink neopunisher September 10th, 2009 at 9:35 am totally awesome article and lots of useful information. thanks for the post 1 up, 0 down Reply Permalink ASL Internet September 10th, 2009 at 10:46 am Another Great post, Very informative! 1 up, 0 down Reply Permalink Michael Martinez September 10th, 2009 at 10:48 am "Search engines likely use scores about the "authority" of a domain in counting links, and thus, despite the fuzzy language, it's worth mentioning as a data point. " On what do you base this conclusion? What publicly verifiable information are you able to share about "domain authority", "domain pagerank", and other domainrelated concepts you advocate? Your ranking factors survey is not an authoritative document in these matters. What else do you have to share on the topic? 1 up, 0 down Reply Permalink firegolem September 10th, 2009 at 11:07 am
- 16. 1 up, 0 down Reply Permalink firegolem September 10th, 2009 at 11:07 am With what do you refute his claims? A) you can ask Rand to further back up his claims B) you could disprove his claims In my opinion hes done a lot of good work here already. If you would like to contribute, you could try to actively disprove his claims and everyone can learn something new. 4 up, 1 down Reply Permalink Michael Martinez September 10th, 2009 at 11:22 am "With what do you refute his claims?" I'm not refuting anything. I'm asking for specific information. 1 up, 4 down Reply Permalink firegolem September 10th, 2009 at 2:57 pm "Your ranking factors survey is not an authoritative document" Reads like refuting to me... 3 up, 1 down Reply Permalink Michael Martinez September 10th, 2009 at 3:22 pm " 'Your ranking factors survey is not an authoritative document' Reads like refuting to me..." Not to me. I asked Rand for specific information, but wanted to make it clear that an opinion poll is not an appropriate source of information. 1 up, 3 down Reply Permalink Nick Gerner September 10th, 2009 at 2:11 pm Michael, Good question. Obviously search engineers aren't disclosing the specifics of the algorithm (Sarah could chime in about legal issues around trade secrets). But I have two good arguments that the notion of domain authority makes sense and we can use it in SEO: 1) Experience tells (many of) us that it works. Our industry survey is pretty broad and there's high consensus that this is a factor that many SEOs are using. Our own quantitative studies puts measures of domain authority way up there regardless of page specific factors. 2) The state of the art research (including from Yahoo! Research and Microsoft Research) focuses on domain level metrics. The arguments cited in the papers come in two flavors. First it's much easier to create measures of authority globally to domains and then apply them to constituent pages (which are much more numerous and change more quickly than global calculations can keep up with). And second, statistically speaking pages within the same domain share many of the same properties (spamminess, quality, truthfulness, value to searchers, etc.)
- 17. specific factors. 2) The state of the art research (including from Yahoo! Research and Microsoft Research) focuses on domain level metrics. The arguments cited in the papers come in two flavors. First it's much easier to create measures of authority globally to domains and then apply them to constituent pages (which are much more numerous and change more quickly than global calculations can keep up with). And second, statistically speaking pages within the same domain share many of the same properties (spamminess, quality, truthfulness, value to searchers, etc.) Consider a selection of Web Spam research focusing on domain level factors: l Fetterly, et al. Spam, Damn Spam, and Statistics l Gyongyi, et al. Combating Web Spam with TrustRank l Castillo, et al. A Reference Collection for Web Spam l Abernethy, et al. Web Spam Identification Through Content and Hyperlinks Whew! I have a bunch more citations if you like. Feel free to PM me :) Edited by Nick Gerner on September 10th, 2009 at 2:14 pm 6 up, 0 down Reply Permalink Michael Martinez September 10th, 2009 at 4:04 pm Nick: " .... I have two good arguments that the notion of domain authority makes sense and we can use it in SEO" First of all, Nick, while I appreciate the response, making "use of it (domain authority) in SEO" has nothing to do with the assertion that "search engines likely use scores about the 'authority' of a domain in counting links, and thus, despite the fuzzy language, it's worth mentioning as a data point." What was once a supposition has almost become a statement of fact. If we're going to talk about this concept as an established fact, I want to know who established the fact, when, and where. The papers you refer to are old hat everyone has read them. None of them have anything to do with the question. Your industry survey doesn't represent what the search engines are doing it represents what people think is important to Google's ranking algorithm (and I participated in the first version of that survey, so I'm quite familiar with how it comes together). " 2) The state of the art research (including from Yahoo! Research and Microsoft Research) focuses on domain level metrics...." Yes, and I can point you to patent application reviews on Bill Slawski's site that deal with these topics. None of that has anything to do with my question. We know that Yahoo! and Microsoft have expressed an interest in domain level evaluations Yahoo! has even publicly stated that the first link from a "site" counts more than the rest in their algorithm (without explaining how they determine which is the first link). Search engines have long had the means to identify reciprocal links between "hosts", but the classic definition of a "host" is not limited or constricted to include only domains. The papers you listed don't even speak about domains (not in this context) they are concerned with "hosts", which what the literature tends to focus on, as the majority of sites are not equivalent to domains. The SEO community has built up a huge myth around the idea of "domain authority", leaching the name from the old Hilltop and LocalRank papers with no real understanding of what those papers were addressing (Hilltop was developed for Google News in 2002 but many people in the SEO community wrongly assert it was rolled out in the 2003 October update despite numerous denials from Google employees that they use the Hilltop logic in Main Web Search). Last year John Conde cogently debunked a lot of this "domain authority" mythology and no one has yet adequately responded to him. We all recognize that some domains are more trusted than others but trust does not equal the ubiquitous "authority" that the SEO community talks about without really defining the concept clearly. What's domain authority? Rand has never offered a technical definition he just sprinkles the term liberally throughout his posts and presentations. Someone recently asked me what the best way to determine how a page passes link juice may be. I had to ask back, "What is link juice?" I'm familiar enough with the term as Rand loves to use it, but no one has ever bothered to explain what it is. Is Link Juice = PageRank? Is it Anchor Text? Is it Trust? Is it a combination of 2 or
- 18. What's domain authority? Rand has never offered a technical definition he just sprinkles the term liberally throughout his posts and presentations. Someone recently asked me what the best way to determine how a page passes link juice may be. I had to ask back, "What is link juice?" I'm familiar enough with the term as Rand loves to use it, but no one has ever bothered to explain what it is. Is Link Juice = PageRank? Is it Anchor Text? Is it Trust? Is it a combination of 2 or 3? I don't want to PM you for citations I've probably read all the papers and patents you can refer me to, and I'd even be willing to wager I've read some you haven't. No one has offered a formal definition for "domain authority" and there has been absolutely no indication from Google that they even use it. What is it? Can you offer a concise definition that makes sense at all levels? Last year I wrote: ... if we assume for the sake of discussion that Google does have some sort of domainlevel PageRank, they don ’t have to use it for weighting links or adjusting relevance scores in search results. That is, a domainlevel PageRank like mechanism could be used to establish trust thresholds, to identify neighborhoods, to create filtering processes that help Google figure out where Web spam is, where new fountains of legitimate content have sprung up, etc. That is, by mapping relationships between domains, Google can analyze the Web without actually using that analysis to directly impact its linking valuations or search results. You guys have invested a lot of time, money, and resources into building a tool that seeks to emulate a concept for which there is no established frame of reference. We don't know if it exists within Google's algorithm. We don't know how it would be used if it does exist within Google's algorithm. We won't know how to measure it if it does exist within Google's algorithm. What is the justification for all this talk about "domain authority" and "domainlevel PageRank"? Experience hasn't taught you or anyone else in the SEO community (including me) anything about these concepts. None of us has any experience with these concepts. SEOmoz just like Yahoo! and Microsoft can do whatever it wants with its search engine. So within LinkScape you have calculated these values but you haven't shown that anyone else is using them. Google really cannot use a "Domain authority" to weight its search rankings any differently from the way PageRank weights search rankings. Google has made it clear that "each site gets only so much PageRank" and that PageRank has to be spread throughout the site as far as it can go to get as many pages to rank in search results as possible. If that's the purpose of PageRank, then what is the purpose of DomainRank? What value does it provide in combatting Web spam? Yahoo.com is home to one of the largest collections of Web spam and yet we all talk about Yahoo! as though it's a highly trusted site. Wikipedia is a terrible source of information its "facts" change constantly and its authors/editors are so discredited that even one of Wikipedia's founders has tried to come up with a better alternative (using vetted sources as contributors). And yet we see Wikipedia all over the search results. Instead of crediting Wikipedia's internal linking structure and extensive on page repetition of keywords (as well as use of keywords in titles and URLs), many people in the SEO community simply conclude that "Wikipedia is an authority domain " and that means it cannot be beaten in the search results. That's not acceptable. Where is the science behind these ideas? Where is the publicly verifiable confirmation from ANY major search engine that this is a key factor in its algorithm? I'm all for canvassing the SEO community to see what people think is important but I draw the line at using opinion polls as authoritative documents about the inner workings of search engine algorithms. There is absolutely no credibility in that kind of position please don't retreat into that document for lack of useful information. Rand would do us all a favor to write a document explaining what he thinks "domain authority" really is, how it works, and why it is needed by any search engine. So far as I can determine, no one has really done that. I'd like to know what everyone thinks they mean by "domain authority". I'm pretty sure no two people can agree on what it should mean. Rand can help move the conversation forward by putting forth a clear, concise explanation. From there we can begin looking for empirical evidence (or just hound search engine employees into talking about the validity of the concept). Edited by Michael Martinez on September 10th, 2009 at 4:07 pm
- 19. I'd like to know what everyone thinks they mean by "domain authority". I'm pretty sure no two people can agree on what it should mean. Rand can help move the conversation forward by putting forth a clear, concise explanation. From there we can begin looking for empirical evidence (or just hound search engine employees into talking about the validity of the concept). Edited by Michael Martinez on September 10th, 2009 at 4:07 pm 1 up, 2 down Reply Permalink Nick Gerner September 10th, 2009 at 4:17 pm You're clearly thinking a lot about this. I urge you to move this discussion to a post of it's own. Maybe this is a great YouMoz post, or a discussion you can continue in its own right. I'd love to read more about your thoughts on the subject :) 7 up, 0 down Reply Permalink Michael Martinez September 10th, 2009 at 5:46 pm Nick: "You're clearly thinking a lot about this. I urge you to move this discussion to a post of it's own. Maybe this is a great YouMoz post, or a discussion you can continue in its own right." Michael : I appreciate what you're saying, but what I'm asking for is a very clear (and hopefully precise) explanation from Rand and the SEOmoz team (or any other person to whom you guys would specifically defer) what "domain authority" is supposed to mean. I want to read YOUR thoughts (and Rand's) on this topic. 1 up, 0 down Reply Permalink jennita September 10th, 2009 at 8:25 pm "...explanation from Rand and the SEOmoz team..." FYI... Nick *IS* on the SEOmoz team. 2 up, 0 down Reply Permalink firegolem September 10th, 2009 at 5:32 pm http://www.youtube.com/watch?v=qXgni6U6qk8&feature=related Michael Be interesting to get your take on Matt Cutts saying newsweek and time have authority (in the context of domains) here. 3 up, 0 down Reply Permalink Michael Martinez September 10th, 2009 at 5:49 pm firegolem : "Be interesting to get your take on Matt Cutts saying
- 20. Reply Permalink Michael Martinez September 10th, 2009 at 5:49 pm firegolem : "Be interesting to get your take on Matt Cutts saying newsweek and time have authority (in the context of domains) here. " Michael : I LONG for the day when Matt Cutts or any appropriate Googler explains in meticulous detail what they mean by "trustworthy and reputable sites" at the algorithmic level. I'll make a deal with you. When that happens, if I see it first, I'll contact you as long as you contact me if you see it first. 1 up, 0 down Reply Permalink goodnewscowboy September 10th, 2009 at 6:17 pm Funny. As I was reading through the post earlier today, I noticed how some things were worded and I found myself wondering if you would weigh in in in your inimitable style Michael. You didn't disappoint :) For starters, unless you are a fly on the wall at the Googleplex, you aren't going to get your answers. I know that. I'm sure you know that. So why, oh why do you keep beating the same drum? Rand filled the post with disqualifiers such as "likely", "some feel", "potentially" and "possibly". What that means to me is: use this at your discretion, and test it out yourself. I'm grateful that he brought these items out of the "speculative" closet so I can be aware of them and it gives me a leg up in the SEO process. Why not take what you want and leave what you don't want, instead of demanding more? 2 up, 1 down Reply Permalink BrettBorders September 10th, 2009 at 1:17 pm Great post, Rand! a solid summary of link value factors that I tend to agree with, based on my own experience. 1 up, 0 down Reply Permalink slygrrr September 10th, 2009 at 1:59 pm Rand, as always, great stuff. I seriously doubt that without actually getting Search Engine Employees to give actual proof of concept inside information there is going to be a better way to explain this to a client. What is astonishing (to me at least) is that this is only one area of the determined merit of a website for search results purposes. Although extremely important, it's only one part of the puzzle. Thanks for the awesome work. 1 up, 0 down Reply Permalink Add Comment A Developer's Adventure Into the World of SEO This Week in Search for 9/10/09
- 21. Add Comment A Developer's Adventure Into the World of SEO This Week in Search for 9/10/09 SEOmoz Partners Services Community Company Categories Web Analytics SEO Consulting SEO Blog About SEO Basics Events & Conferencing SEO Guides YOUmoz Contact Link Building Blogging & the Blogosphere SEO Tools SEO Marketplace Store Search Marketing Issues General Marketing Topics PRO Content Affiliate Program Search Spam & Black Hat Web Design & Development Paid Search Marketing Web 2.0 Platforms & Tech Internet Advertising Online Demographics Copyright © 19962009 SEOmoz. All Rights Reserved. Social Media Marketing Internet Law Privacy Statement | Terms of Use | Contact Vertical Search Business Development