Descargado 135 veces









































![Modelos estáticos: una variable Modelo SEL, Universidad de Maryland (‘80) Esfuerzo = 1,4 L 0,93 [H-M] Documentación = 30,4 L 0,90 [página] Duración = 4,6 L 0,26 [mes] L = número de líneas de código fuente (en miles)](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-45-320.jpg)
![Modelos estáticos: multivariable Walston-Felix, IBM (‘77) Esfuerzo = 5,2 L 0,91 [H-M] Duración = 4,1 L 0,36 [mes] L = KLOC entregadas A estas ecuaciones se les asocia un método para estimar la productividad, este índice usa 29 variables](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-46-320.jpg)





![COCOMO 81 Esfuerzo se entrega en unidades [H-M], es decir el número de meses que una persona necesitaría para desarrollar el proyecto Tipos: Básico Intermedio Detallado](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-52-320.jpg)

![COCOMO 81 básico orgánico programadores expertos desarrollan software en ambiente familiar E m = 2,4 L k 1,05 [H-M] t d = 2,5 E m 0,38 [mes] L k = miles de líneas fuente entregadas](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-54-320.jpg)
![COCOMO 81 básico semi-desconectado mezcla de gente experta e inexperta E m = 3,0 L k 1,12 [H-M] t d = 2,5 E m 0,35 [mes]](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-55-320.jpg)
![COCOMO 81 básico empotrado hay fuertes restricciones (procesador y hardware) y no han habido proyectos anteriores comparables E m = 3,6 L k 1,20 [H-M] t d = 2,5 E m 0,32 [mes]](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-56-320.jpg)

![COCOMO 81 intermedio E n , esfuerzo nominal Orgánico E n = 3,2 L k 1,05 [H-M] Semi-desconectado E n = 3,0 L k 1,12 [H-M] Empotrado E n = 2,8 L k 1,20 [H-M] 15 multiplicadores de esfuerzo afectan E n entregando E t t d = 2,5 E t 0,32](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-58-320.jpg)
![COCOMO 81 intermedio Ejemplo Un sistema de comunicaciones hecho en microprocesadores en red y como requerimientos de desarrollo, rendimiento e interfaces modo empotrado 10000 líneas de código fuente entregadas 10 KDSI Esfuerzo nominal: E n = 2,8 (10) 1,20 = 44 [H-M] E t = E n * (multiplicadores de esfuerzo)](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-59-320.jpg)





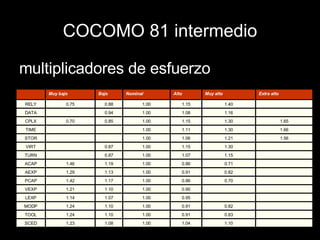
![COCOMO 81 intermedio Ejemplo Esfuerzo nominal: E n = 2,8 (10) 1,20 = 44 [H-M] E t = E n * multiplicadores E t = 44 * 1,35 = 59 [H-M] t d = 2,5 E t 0,32 = 9,21 [M] Multiplicador Rating Situación Costo 1,35 TOTAL . . . . . . . . . . . . 1,30 muy alto Procesamiento de comunicaciones Complejidad producto 0,94 bajo 20.000 bytes Tamaño de la base de datos 1,15 Alto Serias consecuencias financieras o fallas de software Configuración del software requerido](https://image.slidesharecdn.com/clase-6-5920071007/85/Clase-6-5-9-2007-66-320.jpg)


El documento describe varias técnicas para estimar los costos de desarrollo de software, incluyendo modelos algorítmicos, juicio de expertos, estimación por analogía, y la ley de Parkinson. También explica los métodos de estimación bottom-up y top-down, y las métricas como líneas de código, puntos de función y FFP que se pueden usar para estimar el tamaño de un proyecto de software.





















































































