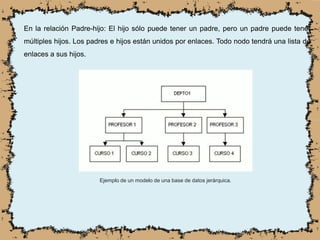
Un sistema gestor de base de datos (SGBD) permite almacenar, modificar y extraer información de bases de datos, ofreciendo herramientas para garantizar la integridad de los datos y controlar el acceso. Existen diferentes tipos de estructuras de bases de datos, como jerárquicas, en red, relacionales, multidimensionales y orientadas a objetos, cada una con sus propias características y aplicaciones. Los SGBD son fundamentales en el manejo de datos empresariales, optimizando el acceso y la recuperación de información de manera eficiente.