Este documento presenta una introducción a Python y Google Colab. Incluye información sobre la historia y beneficios de Python, así como una explicación de cómo funciona Google Colab para ejecutar código Python en la nube. Luego, proporciona una introducción a conceptos básicos de Python como objetos, librerías y comandos, y explica cómo usar librerías populares como NumPy y Pandas para el análisis de datos.












![COMANDOS BÁSICOS EN PYTHON
Asignación a objetos con caracteres
palabra = "Python“
palabra[0]
palabra[3]
palabra[-1]
palabra[2:]
len(palabra)
Listas
numeros = [1,2,3,4]
datos = [4,"Una cadena",-15,3.14,"Otra cadena"]
letras = ['a','b','c','d','e','f']
pares = [0,2,4,5,8,10]](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-16-2048.jpg)
![COMANDOS BÁSICOS EN PYTHON
Operaciones con listas
datos[2:]
datos[-2:]
pares.append(12)
letras[:3] = ['A','B','C']
Letras
letras[:3] = []
Listas de listas
numeros = [1,2,3,4]
datos = [4,"Una cadena",-15,3.14,"Otra cadena"]
letras = ['a','b','c','d','e','f']
pares = [0,2,4,5,8,10]](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-17-2048.jpg)
![COMANDOS BÁSICOS EN PYTHON
Operaciones con lista de listas
a = [1,2,3]
b = [4,5,6]
c = [7,8,9]
r = [a,b,c]
r[0]
r[-1]
r[2][2]](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-18-2048.jpg)

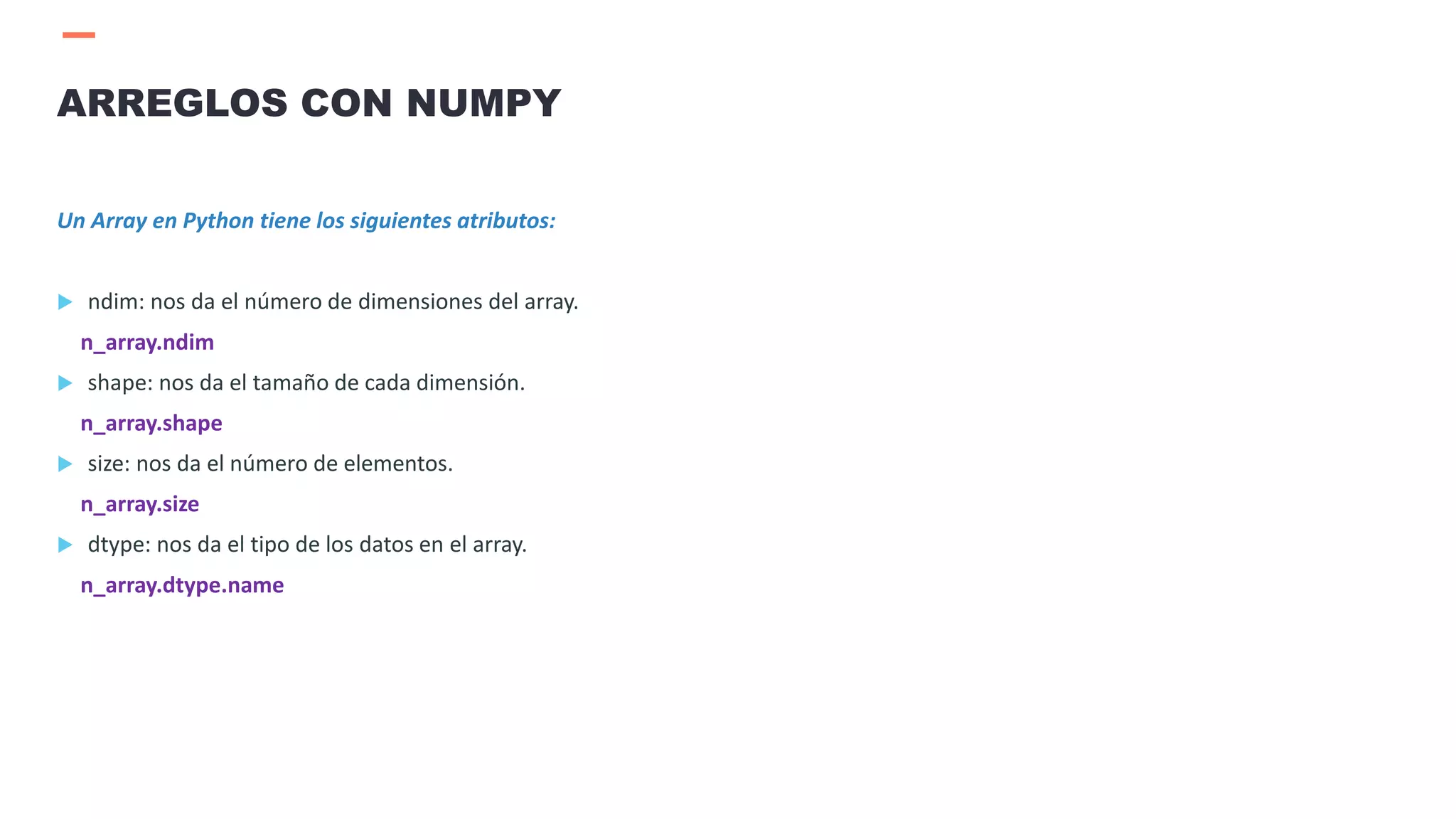
![ Array es una matriz unidimensional.
En Python la estructura de datos por defecto son las listas. Sin embargo, las listas no soportan operaciones
matemáticas avanzadas, no está optimizado para hacerlo.
NumPy = Paquete de Python creado por Travis Oliphant con propósitos científicos.
Array en NumPy consume menos memoria y por ende es más rápido que una lista de Python.
Para la creación de un Array en Python
1.Necesitamos importar la librería:
import numpy as np
2.Creamos el array en Python:
n_array = np.array([[0, 1, 2, 3],[4, 5, 6, 7],[8, 9, 10, 11]])
ARREGLOS CON NUMPY](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-21-2048.jpg)
![ Restas de arrays.
a = np.array( [11, 12, 13, 14])
b = np.array( [ 1, 2, 3, 4])
c = a - b
c
Potencia de arrays.
b**2
Funciones sobre los arrays.
np.cos(b)
Multiplicación de matrices
A1 = np.array([[1, 1],[0, 1]]) / A2 = np.array([[2, 0],[3, 4]])
A1*A2
np.dot(A1,A2)
OPERACIONES MATEMÁTICAS CON NUMPY](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-23-2048.jpg)
![Si deseamos seleccionar un elemento en particular de un array:
Seleccionamos la fila 1 y la columna 2.
n_array[0,1]
Seleccionamos la fila 1 y las 3 primeras columnas.
n_array[ 0 , 0:3 ]
Seleccionamos la fila 1 y todas las columnas.
n_array[ 0 , : ]
Seleccionamos todas las filas y la columna 2.
n_array[ : , 1 ]
OPERACIONES CON NUMPY](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-24-2048.jpg)



![Las series son un array de una dimensión, pueden almacenar cualquier tipo de
datos como valores discretos, continuos, cadenas y objetos Python.
Importar la librería Pandas desde Python.
import pandas as pd
Creación de una serie a partir de 5 números aleatorios.
pd.Series(np.random.randn(5))
pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
SERIES](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-28-2048.jpg)
![Es una estructura de datos de 2 dimensiones de distinto tipos de datos, un data frame puede venir de las siguientes
estructuras de datos:
NumPy Array, Listas, Diccionarios, Series, 2D NumPy Array.
Data Frames que provienen de diccionarios de series.
d = {'c1': pd.Series(['A', 'B', 'C']),'c2': pd.Series([1, 2., 3., 4.])}
df = pd.DataFrame(d)
Data Frames que provienen de diccionarios de listas.
d = {'c1': ['A', 'B', 'C', 'D'],'c2': [1, 2.0, 3.0, 4.0]}
df = pd.DataFrame(d)
DATA FRAMES](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-29-2048.jpg)

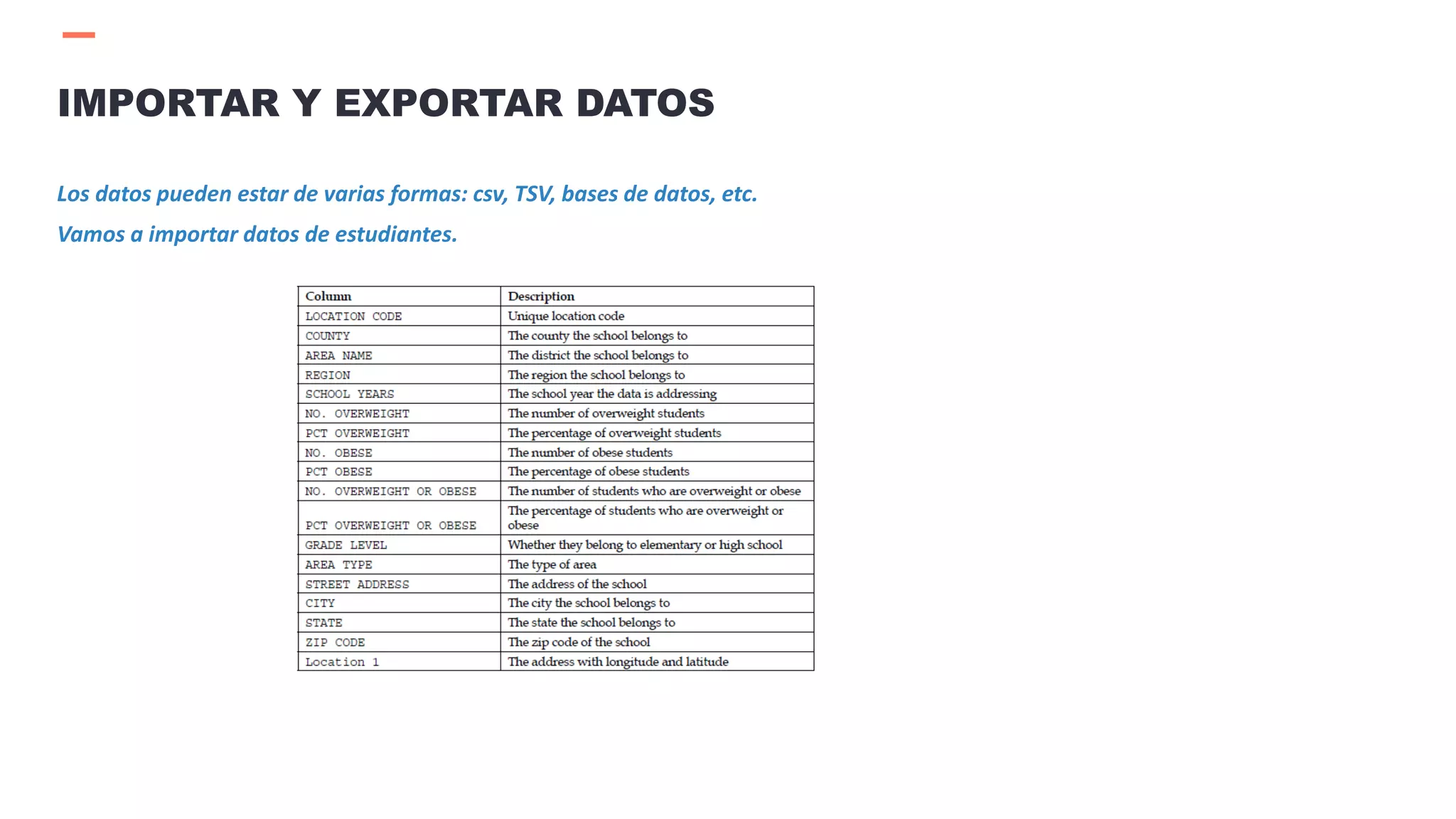
![ Importar datos en formato csv.
d = pd.read_csv('Data/students.csv')
Leer los primeros registros.
d.head()
Leer registros específicos de una variable
d[0:5][variable]
Exportar datos de un data frame a un csv
d = {'c1': pd.Series(['A', 'B', 'C']),'c2': pd.Series([1, 2., 3., 4.])}
df = pd.DataFrame(d)
df.to_csv('sample_data.csv')
IMPORTAR Y EXPORTAR DATOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-32-2048.jpg)
![ Importar datos en formato xls.
d = pd.read_excel('Data/students.xls')
Leer los primeros registros.
d.head()
Leer registros específicos de una variable
d[0:5][‘variable’]
Exportar datos de un data frame a un xls
df.to_excel('sample_data.xls')
IMPORTAR Y EXPORTAR DATOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-33-2048.jpg)


![ Identificar a los valores perdidos.
d[‘variable’].isnull()
Identificar a los valores no perdidos.
d[‘variable’].notnull()
Cuantificar a los valores perdidos.
d[‘variable’].isnull().value_counts()
Cuantificar a los valores no perdidos.
d[‘variable’].notnull().value_counts()
Eliminar a los valores perdidos.
d = d[‘variable’].dropna()
Eliminar a cualquier registro que tenga por lo menos un campo con valor perdido.
d = d.dropna(how='any')
VALORES PERDIDOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-36-2048.jpg)
![ Crear un data frame en base a números aleatorios.
df = pd.DataFrame(np.random.randn(5, 3), index=['a0', 'a10','a20', 'a30', 'a40'],
columns=['X', 'Y', 'Z'])
Crear índices adicionales al data frame.
df2 = df.reindex(['a0', 'a1', 'a10', 'a11', 'a20', 'a21','a30', 'a31', 'a40', 'a41'])
Completar los valores perdidos con ceros.
df2.fillna(0)
Completar los valores perdidos con el método “forward propagation”. Se va completar con
el valor previo al nulo.
df2.fillna(method='pad')
Completar los valores perdidos con el promedio de la variable.
df2.fillna(df2.mean())
VALORES PERDIDOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-37-2048.jpg)
![ Importar un archivo csv y leer los 5 primeros casos.
df = pd.read_csv('data/students.csv')
df['AREA NAME'][0:5]
Filtrar casos específicos.
df[df['GRADE LEVEL'] == 'ELEMENTARY']
Convertir a mayúsculas.
df['AREA NAME'][0:5].str.upper()
Convertir a minúsculas.
df['AREA NAME'][0:5].str.lower()
Cuantificar la cantidad de caracteres de cada elemento.
df['AREA NAME'][0:5].str.len()
Cortar en base a espacios en blanco.
df['AREA NAME'][0:5].str.split(' ')
Reemplazar
df['AREA NAME'][0:5].str.replace('DISTRICT$', 'DIST')
OPERACIONES CON CADENAS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-38-2048.jpg)

![ Seleccionamos los 5 primeros registros de 2 campos.
d[['AREA NAME', 'COUNTY']][0:5]
Partir los datos en dos grupos. Concatenarlos por posición.
p1 = d[['AREA NAME', 'COUNTY']][0:2]
p2 = d[['AREA NAME', 'COUNTY']][2:5]
pd.concat([p1,p2])
Concatenar datos en base a una llave.
concatenated = pd.concat([p1,p2], keys = ['p1','p2'])
Seleccionar la data agregada en base a una llave.
concatenated.ix['p1']
CONCATENAR DATOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-40-2048.jpg)
![ Seleccionamos un subconjunto de elementos y promediamos.
data = d[d['GRADE LEVEL'] == 'ELEMENTARY']
data['NO. OBESE'].mean()
La suma total.
data['NO. OBESE'].sum()
Valor máximo.
data['NO. OBESE'].max()
Valor mínimo.
data['NO. OBESE'].min()
Desviación Estándar.
data['NO. OBESE'].std()
Conteo.
data = df[(d['GRADE LEVEL'] == 'ELEMENTARY') &(d['COUNTY'] == 'DELAWARE')]
data['COUNTY'].count()
AGREGAR DATOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-41-2048.jpg)
![ Creamos un data frame.
grade_lookup = {'GRADE LEVEL': pd.Series(['ELEMENTARY','MIDDLE/HIGH', 'MISC']),
'LEVEL': pd.Series([1, 2, 3])}
grade_lookup2 = pd.DataFrame(grade_lookup)
La tabla que usaremos como base es la de estudiantes.
df[['GRADE LEVEL']][0:5]
Inner Join.
d_sub = df[0:5].join(grade_lookup2.set_index(['GRADE LEVEL']),
on=['GRADE LEVEL'], how='inner')
CRUZAR DATOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-42-2048.jpg)
![ Left Join.
d_sub = df[0:5].join(grade_lookup2.set_index(['GRADE LEVEL']),
on=['GRADE LEVEL'], how='left')
Full Outer Join.
d_sub = df[0:5].join(grade_lookup2.set_index(['GRADE LEVEL']),
on=['GRADE LEVEL'], how='outer')
CRUZAR DATOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-43-2048.jpg)
![df['NO. OBESE'].groupby(d['GRADE LEVEL']).sum()
d['NO. OBESE'].groupby(d['GRADE LEVEL']).mean()
d['NO. OBESE'].groupby(d['GRADE LEVEL']).std()
AGRUPAR DATOS](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-44-2048.jpg)

![[Sesion03] introduccion python](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-46-2048.jpg)
![[Sesion03] introduccion python](https://image.slidesharecdn.com/sesion03introduccionpython-210521020557/75/Sesion03-introduccion-python-47-2048.jpg)













































