Descargar para leer sin conexión










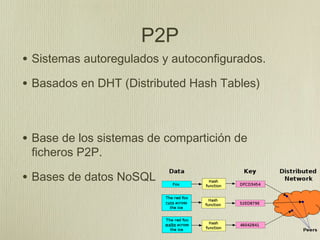



















Este documento discute el fenómeno del Big Data y la Ciencia de Datos. Habla sobre cómo ahora tenemos acceso a grandes cantidades de datos heterogéneos de todo tipo provenientes de fuentes como sensores, redes sociales y ciudades inteligentes. También describe los desafíos técnicos asociados con el almacenamiento y procesamiento masivo de datos, así como cuestiones éticas relacionadas con la privacidad de los datos personales.


















































































