






























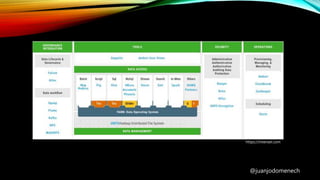

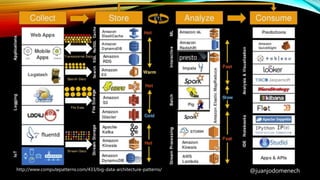




El documento proporciona un análisis detallado de Big Data, sus definiciones y características esenciales, destacando la necesidad de capturar y analizar grandes volúmenes de datos. Se abordan diferentes arquitecturas y herramientas necesarias para gestionar estos datos, incluyendo sistemas de almacenamiento, procesamiento y seguridad. Además, se mencionan ejemplos de aplicación y sectores estratégicos donde Big Data tiene un impacto significativo.















































