Descargado 27 veces






![<3
REST
Índice ID
curl -XPUT 'http://localhost:9200/articulos/articulo/1' -d '{
"titulo": "Buenas cervezas", Tipo
"contenido": "Todas. Menos Budweiser.",
"tags": ["cerveza", "budweiser"]
}'
Le pasás JSON
curl -XGET
'http://localhost:9200/articulos/articulo/_search?q=cerveza&pretty'
API
Te devuelve JSON](https://image.slidesharecdn.com/elasticsearch-121104143706-phpapp02/85/ElasticSearch-la-tenes-atroden-Google-8-320.jpg)

![Actualizar documento
curl -XPUT 'http://localhost:9200/articulos/articulo/1' -d '{
"titulo": "Buenas cervezas",
"contenido": "Todas. Menos Budweiser. Tampoco Schneider.",
"tags" ["cerveza", "budweiser", "schneider"]
}'
{
"ok":true,
"_index":"articulos",
"_type":"articulo",
"_id":"1",
"_version":2
}](https://image.slidesharecdn.com/elasticsearch-121104143706-phpapp02/85/ElasticSearch-la-tenes-atroden-Google-10-320.jpg)



![Filtros
curl -XPUT 'http://localhost:9200/articulos/articulo/1' -d '{
"titulo": "Buenas cervezas",
"contenido": "Todas. Menos Budweiser.",
"publicado": "2012-11-04 06:43:00",
"tags": ["cerveza", "budweiser"],
"rating": {"promedio": 8.7, "total": 15}
}'
curl -XGET 'http://localhost:9200/articulos/articulo/_search?q=cerveza' -d '{
"filter": {
"range": {"rating.total": {"from": 10}}
}
}'](https://image.slidesharecdn.com/elasticsearch-121104143706-phpapp02/85/ElasticSearch-la-tenes-atroden-Google-14-320.jpg)


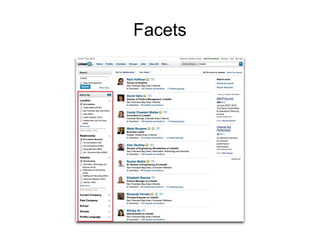



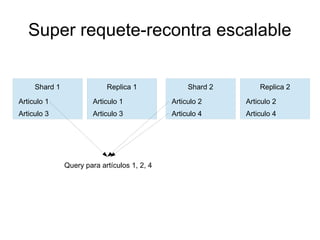





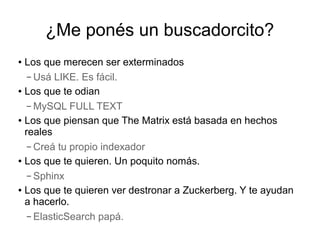
Este documento presenta ElasticSearch, una herramienta de búsqueda y análisis de datos distribuida basada en Lucene. Explica conceptos clave como nodos, índices y tipos de datos, y cómo ElasticSearch permite realizar búsquedas, agregados y filtros de forma distribuida y en tiempo real sobre grandes volúmenes de datos. También describe características como shards, replicas y auto-escalabilidad para lograr alta disponibilidad y tolerancia a fallos, así como su interfaz RESTful y capacidades de integración con otros sistem



























![[131] packetbeat과 elasticsearch](https://cdn.slidesharecdn.com/ss_thumbnails/113packetbeatelasticsearch-150914020054-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![José Ramón Palanco - NoSQL Security [RootedCON 2011]](https://cdn.slidesharecdn.com/ss_thumbnails/rooted-nosqlsecurity-110307132650-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























