Descargado 38 veces







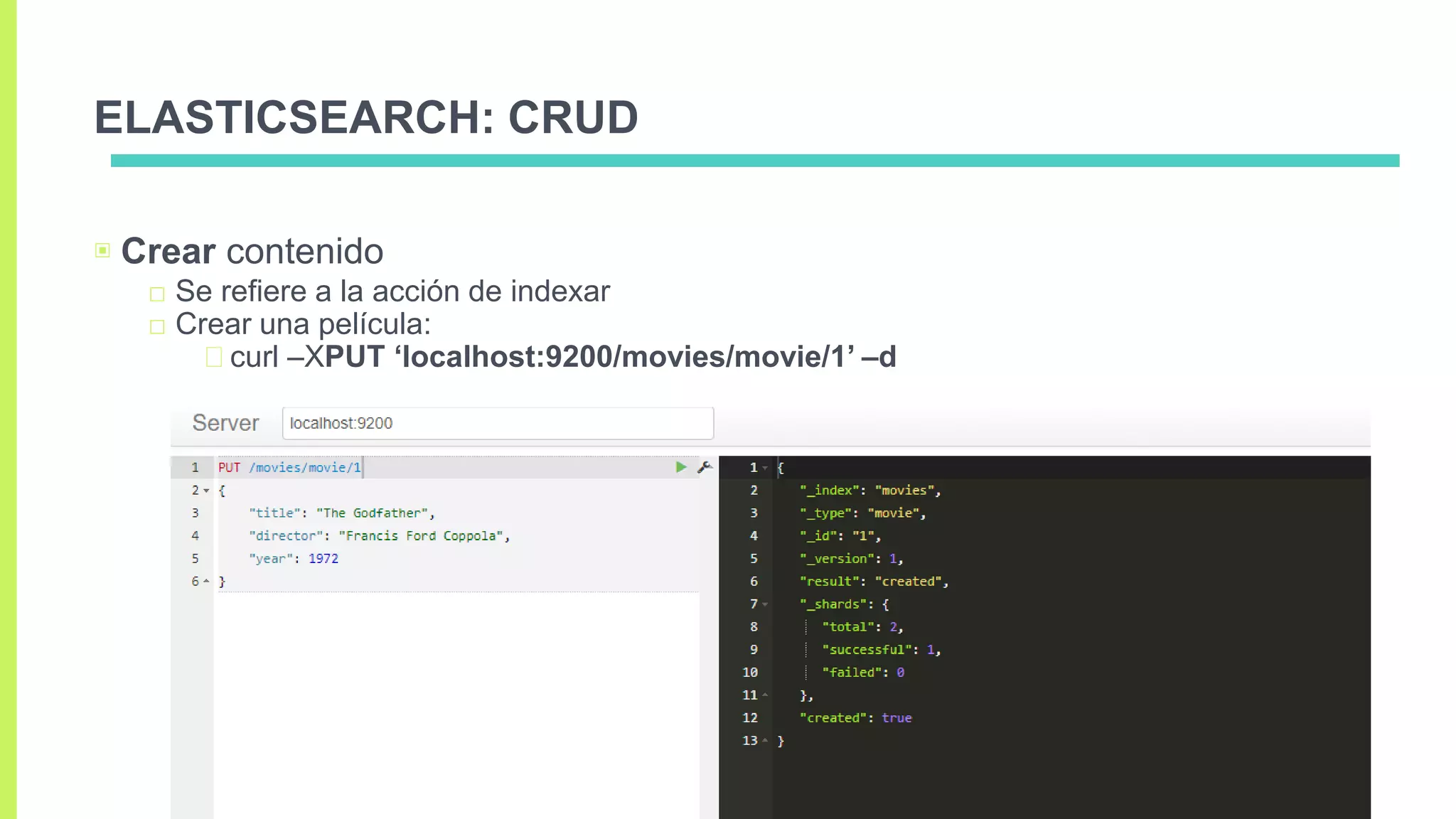


Elasticsearch es un servidor de búsquedas basado en Apache Lucene, diseñado para la escalabilidad y la obtención de datos desde diversas fuentes a través de una API REST. Permite búsquedas near real-time y organiza la información en clusters, nodos, índices, tipos y shards, garantizando alta disponibilidad mediante réplicas. Además, contiene funcionalidades CRUD para gestionar y manipular el contenido almacenado.





































































