Descargar para leer sin conexión






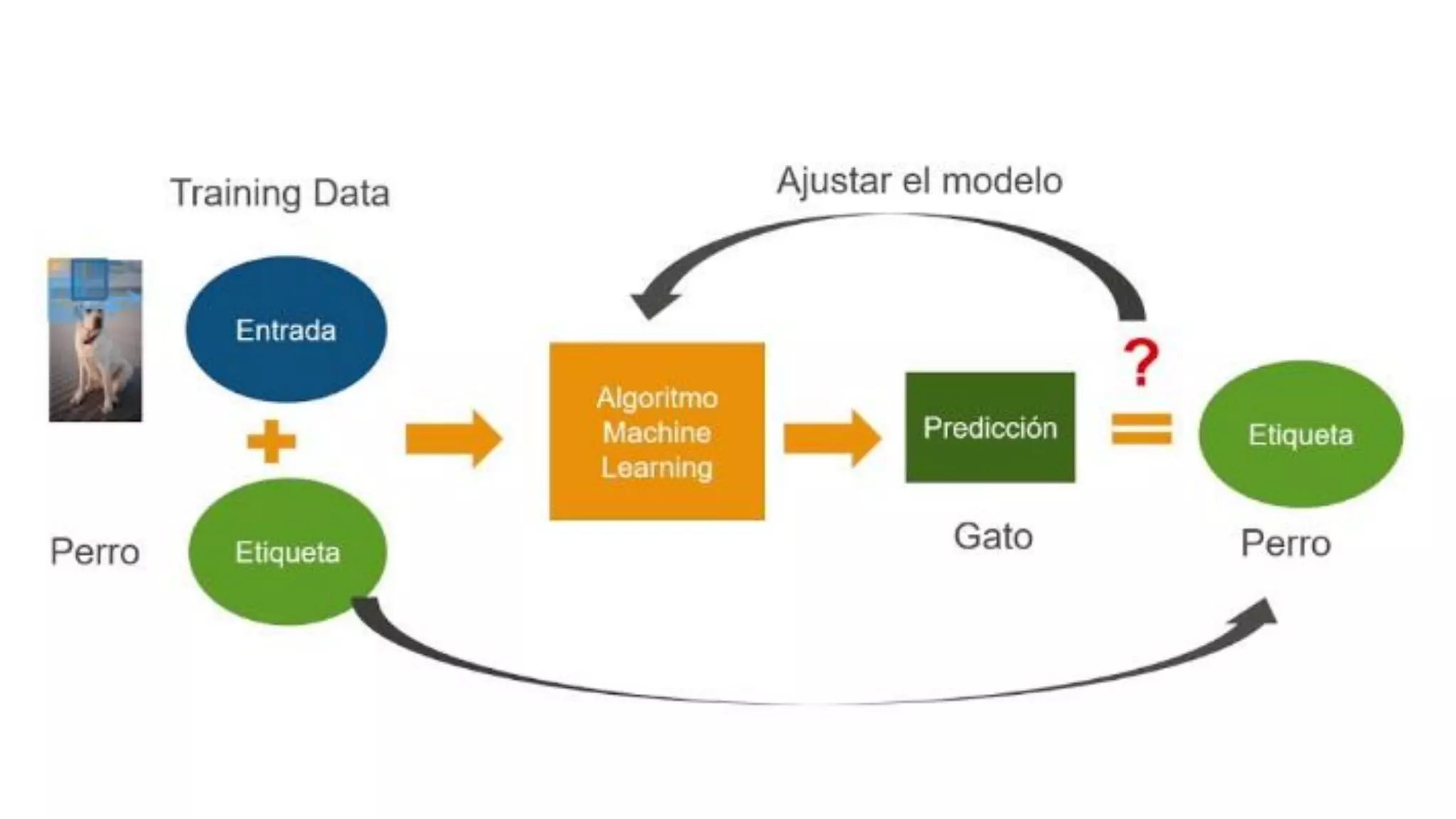
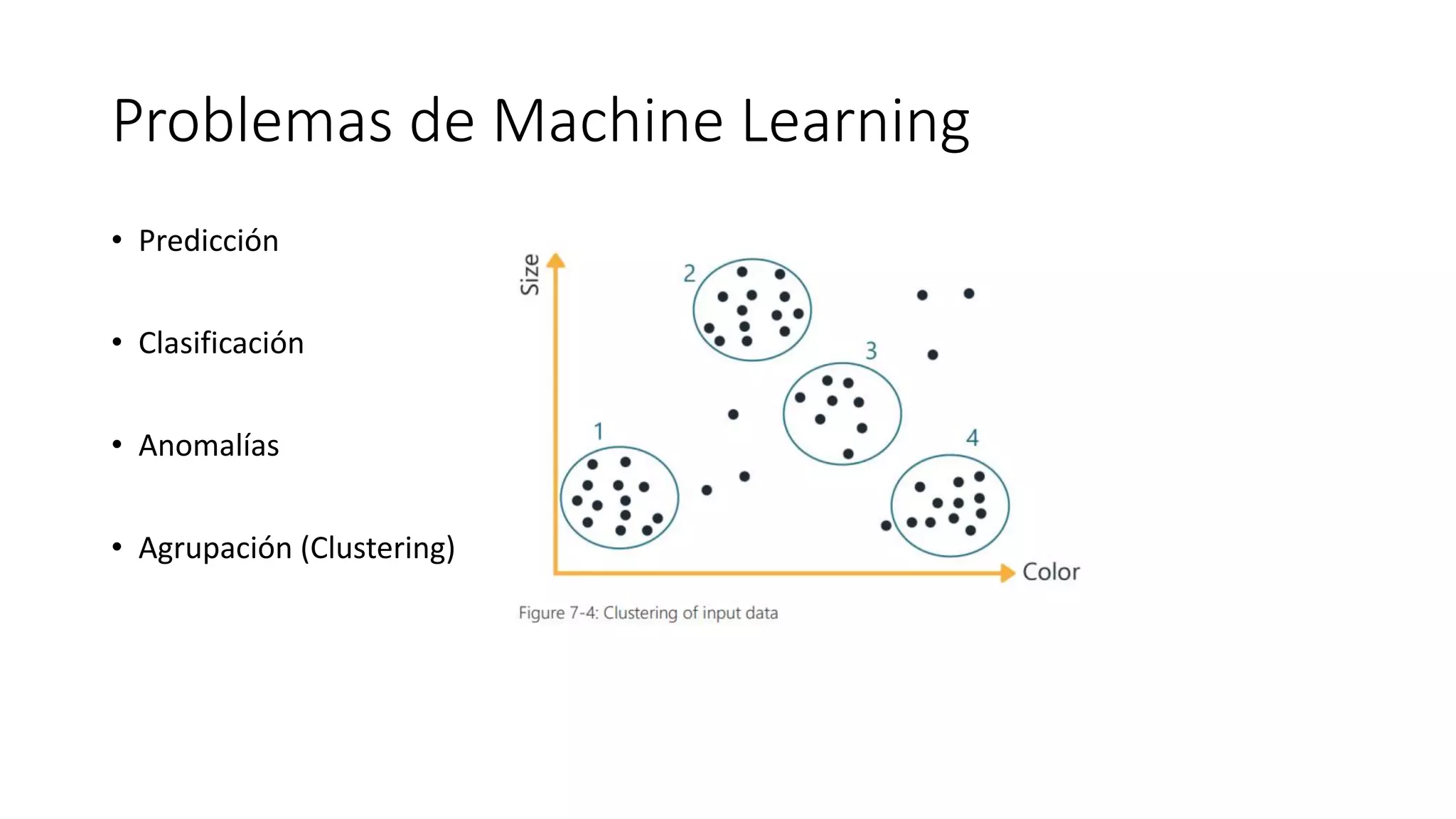
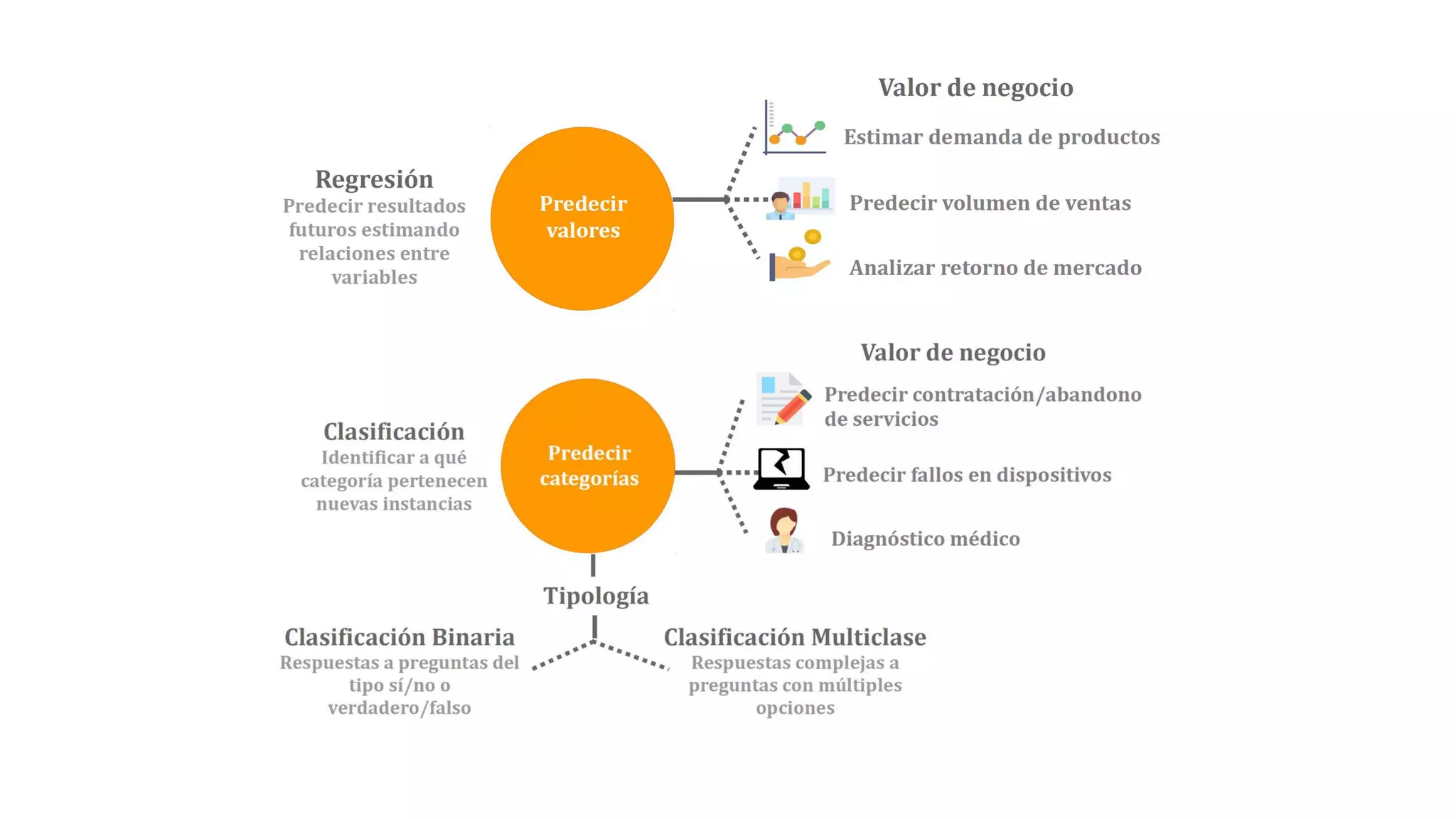
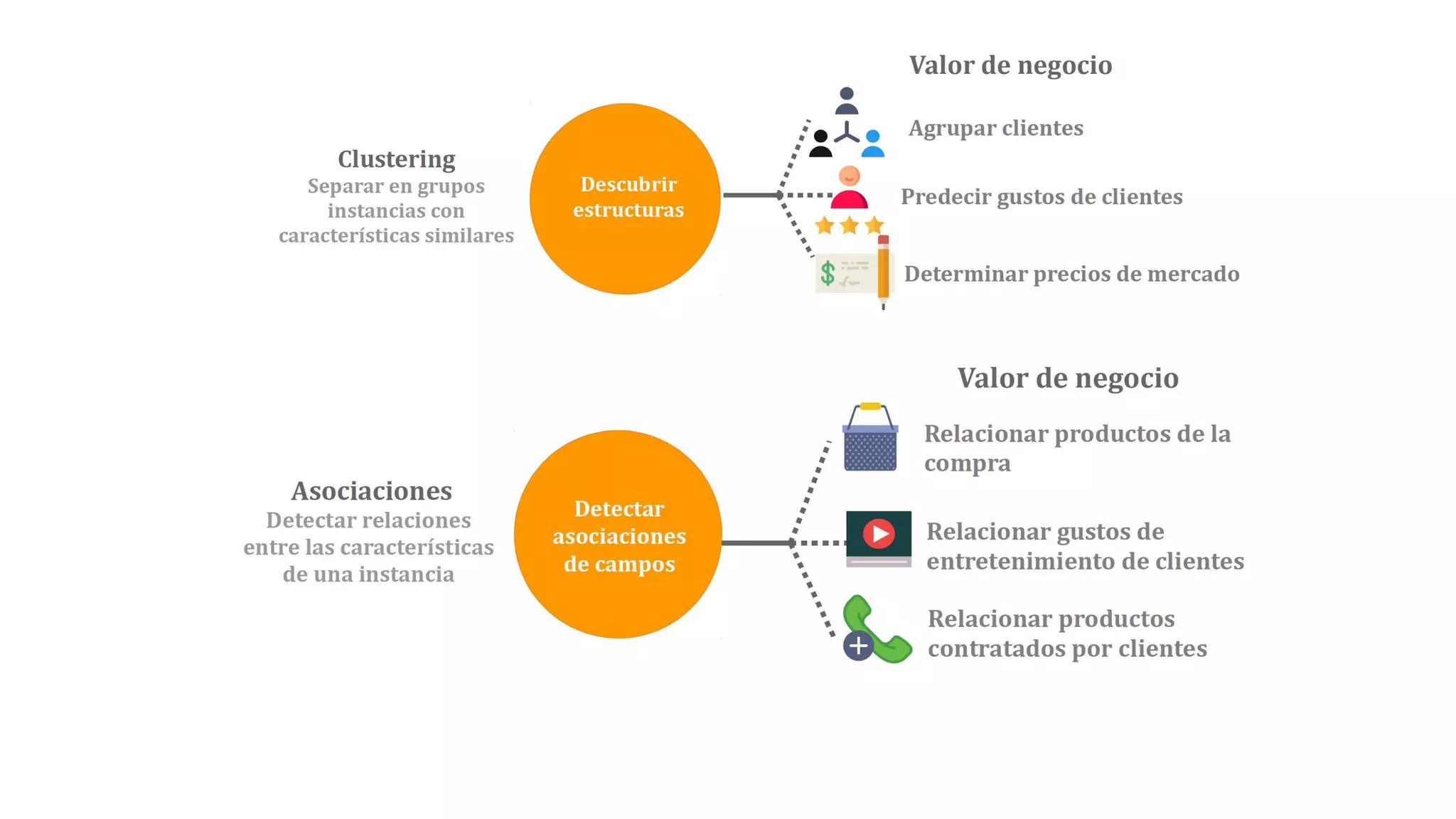
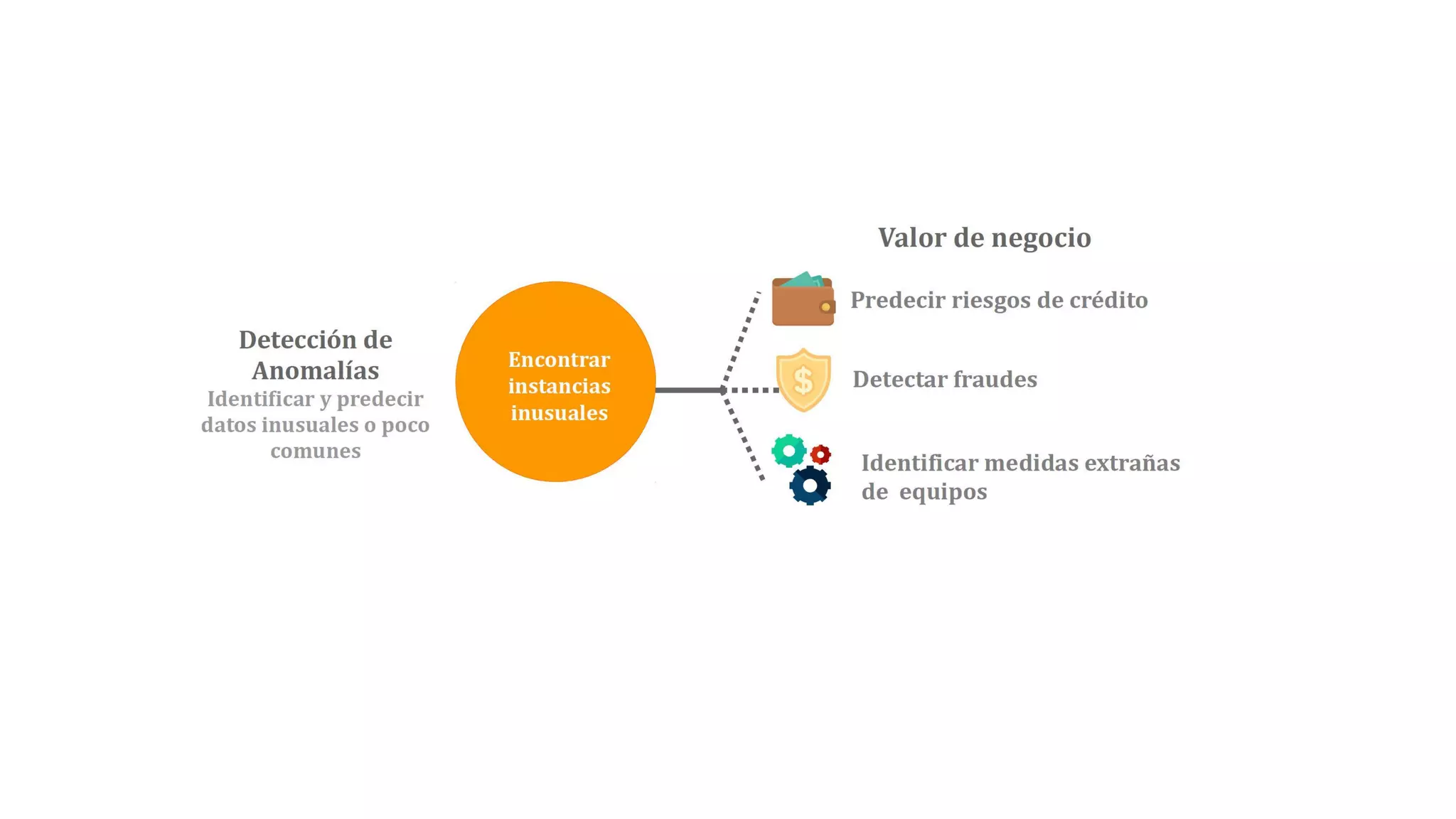
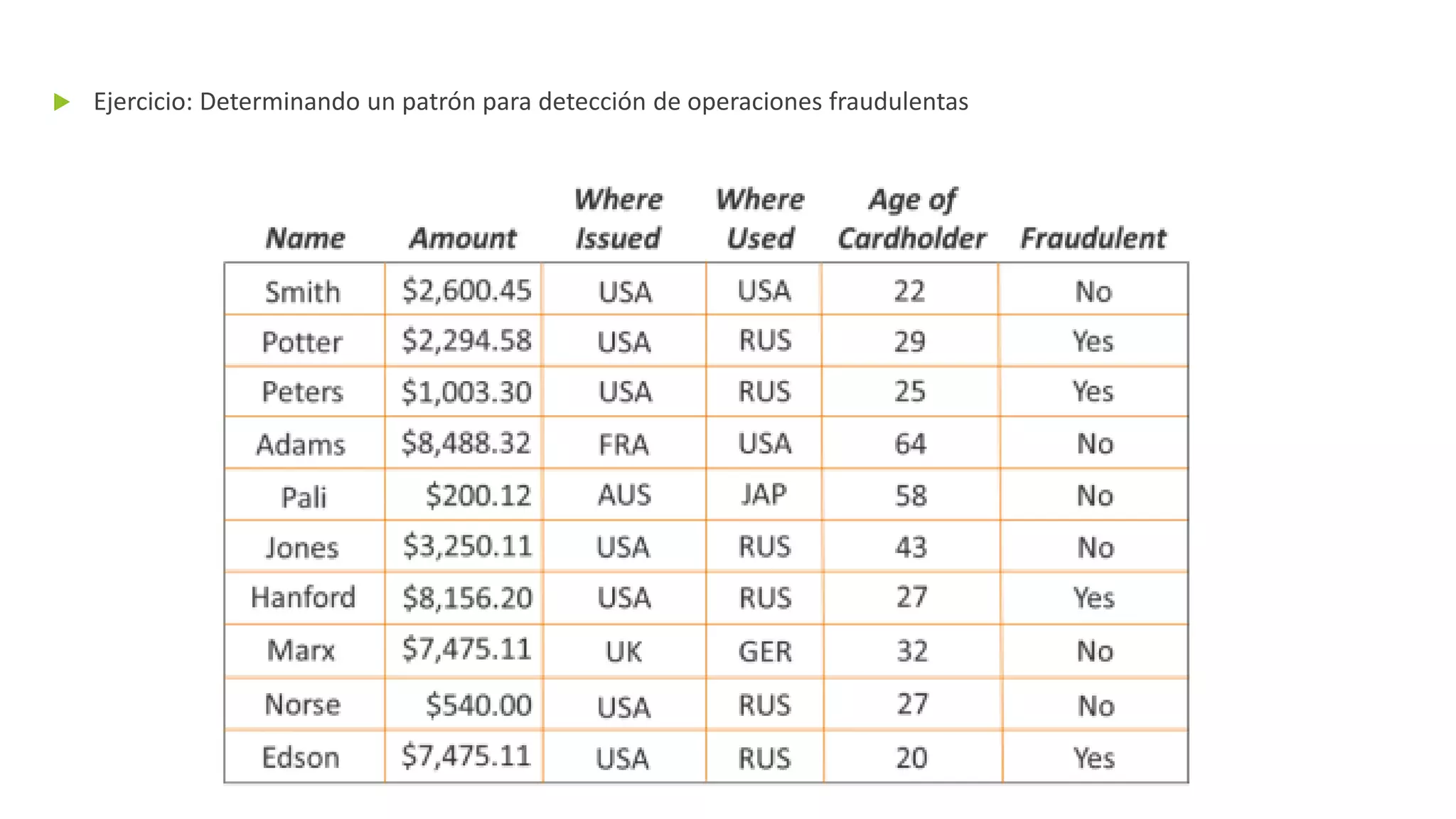
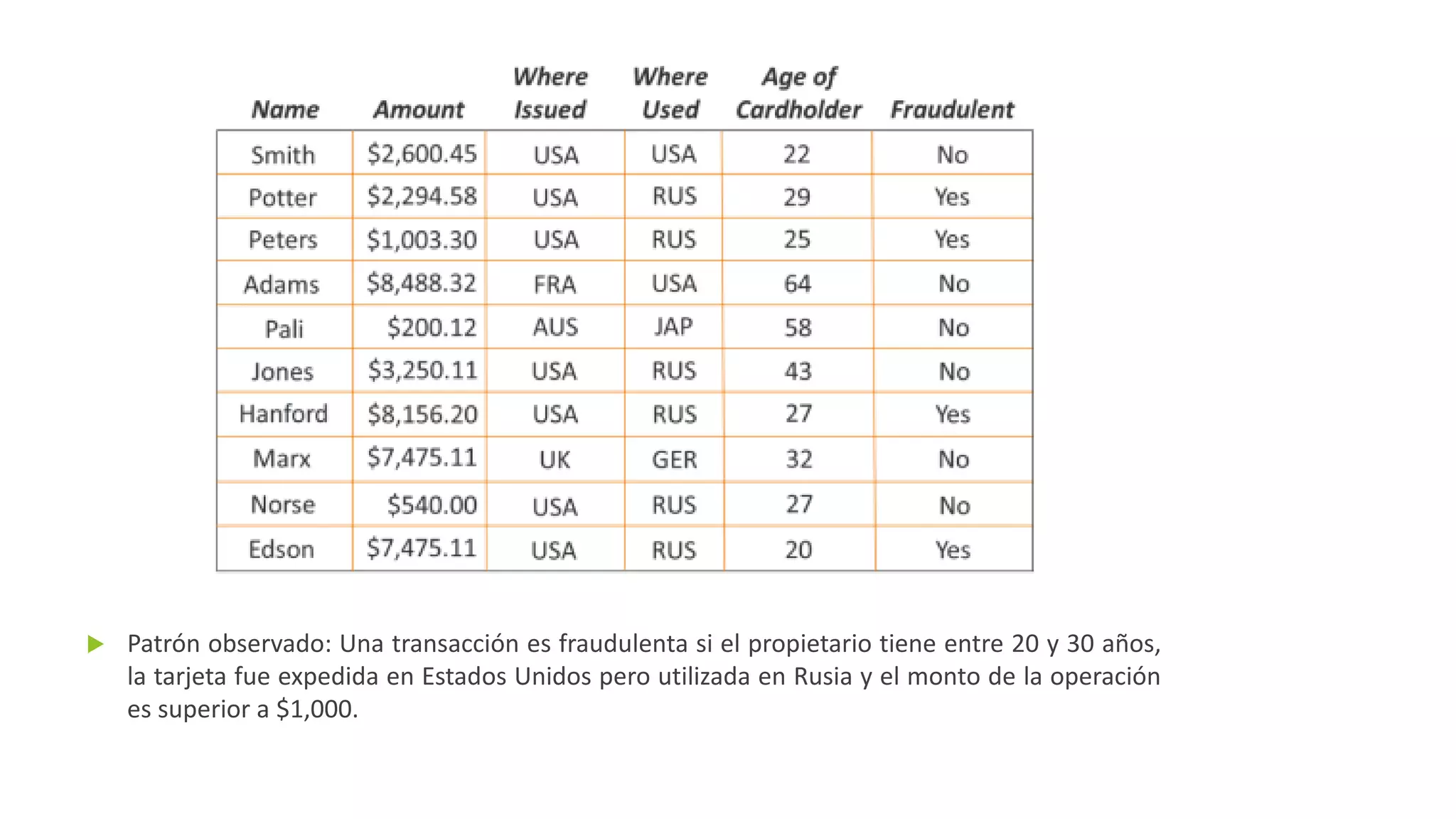
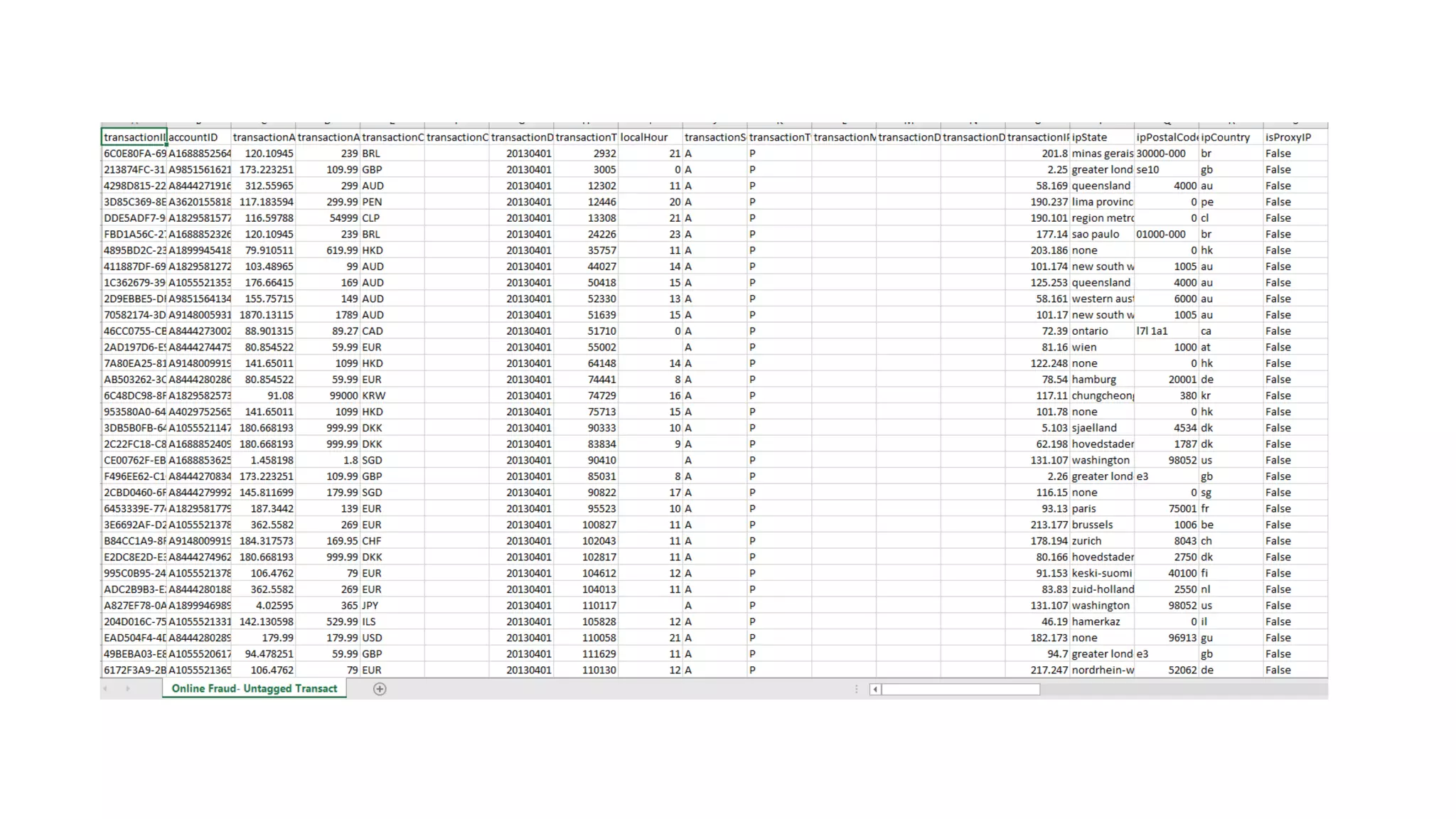


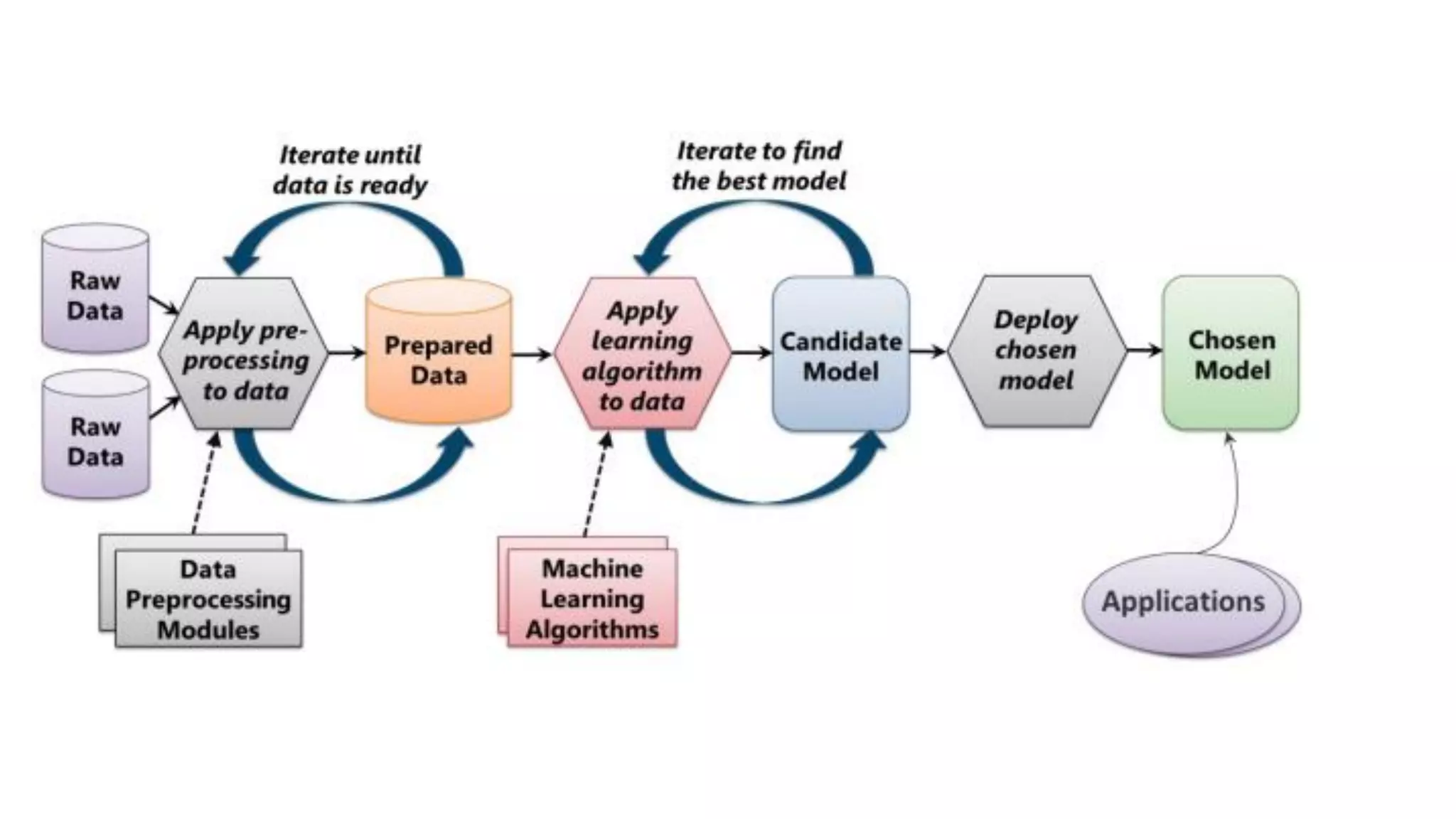




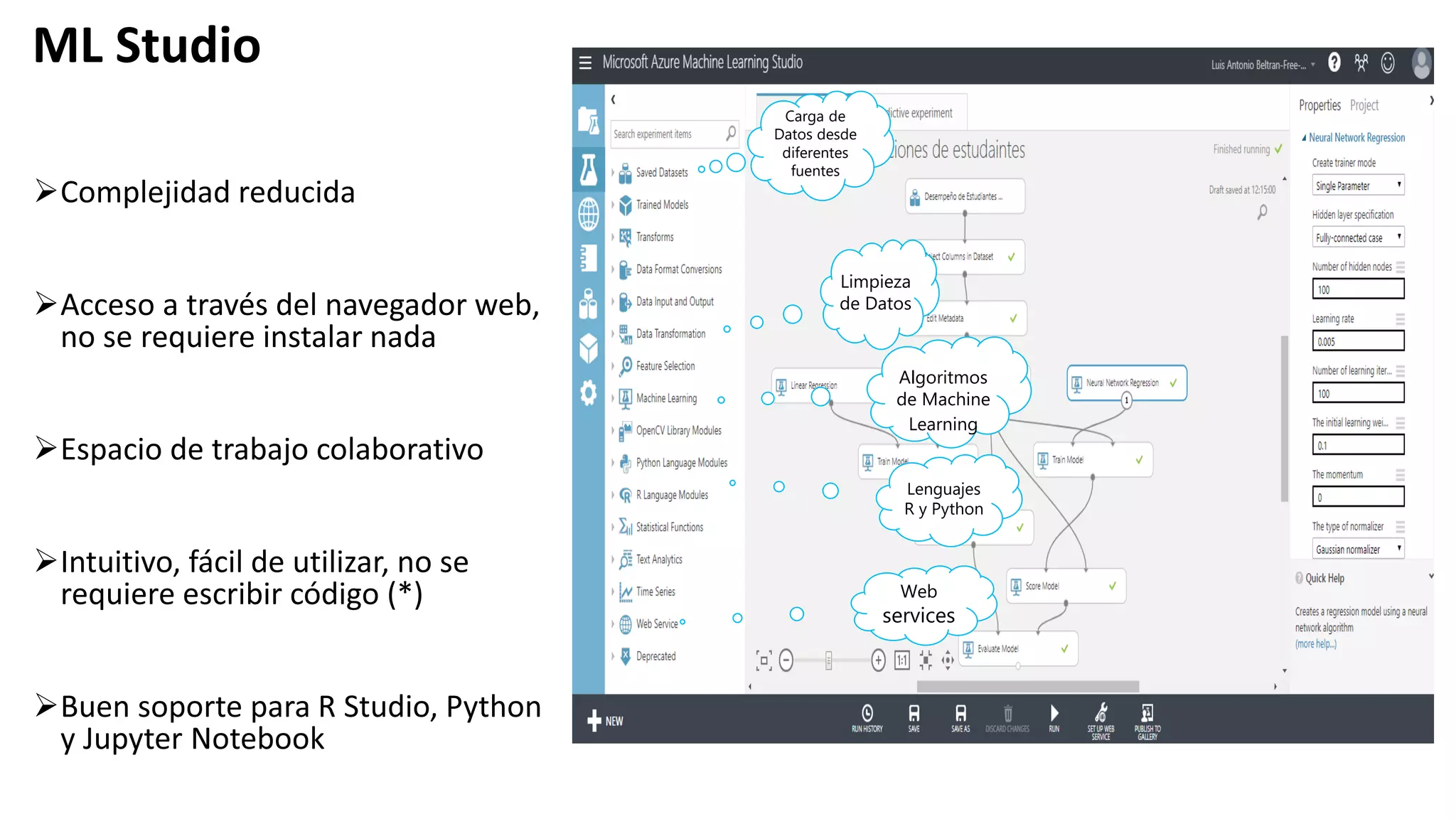
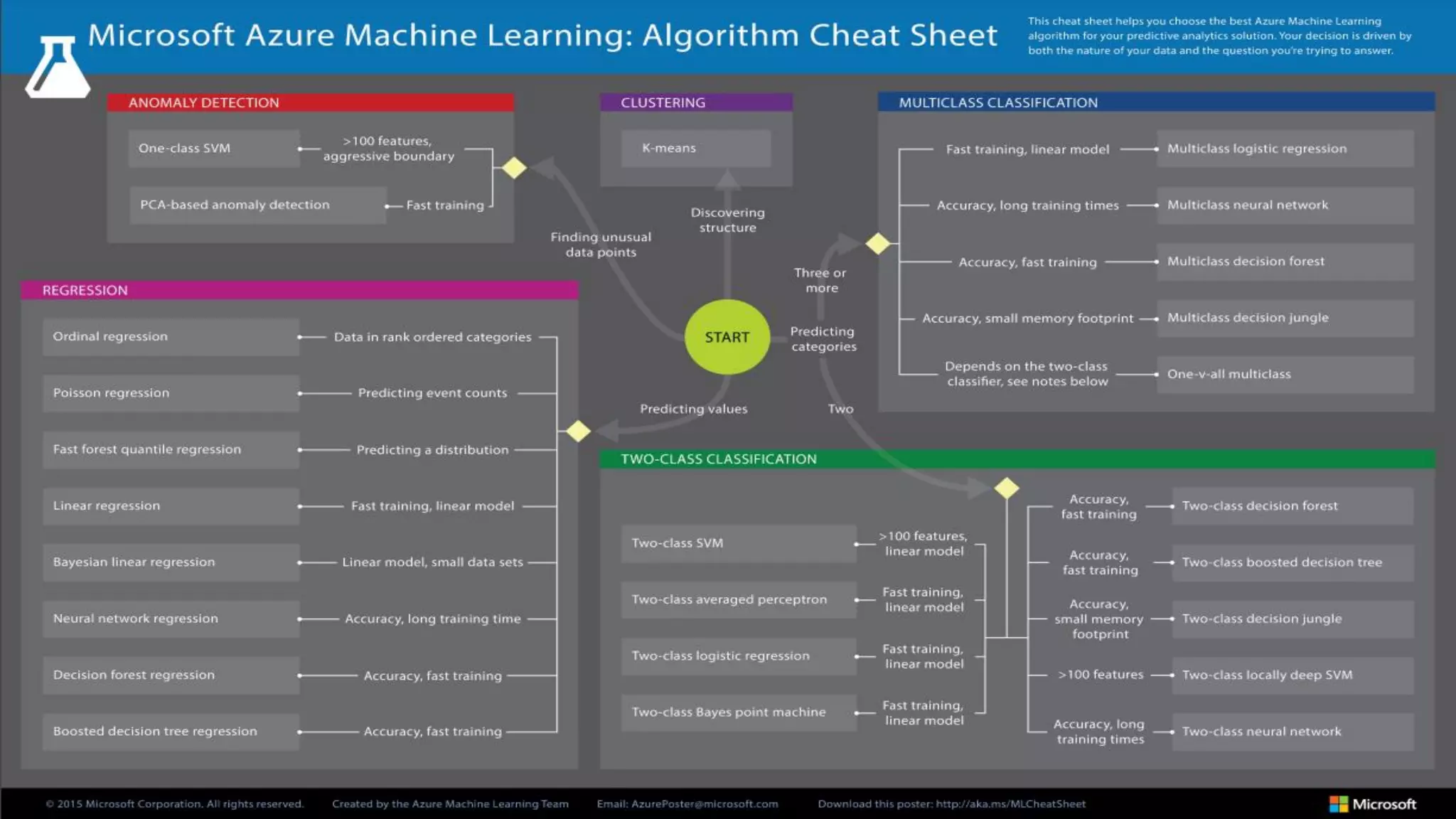
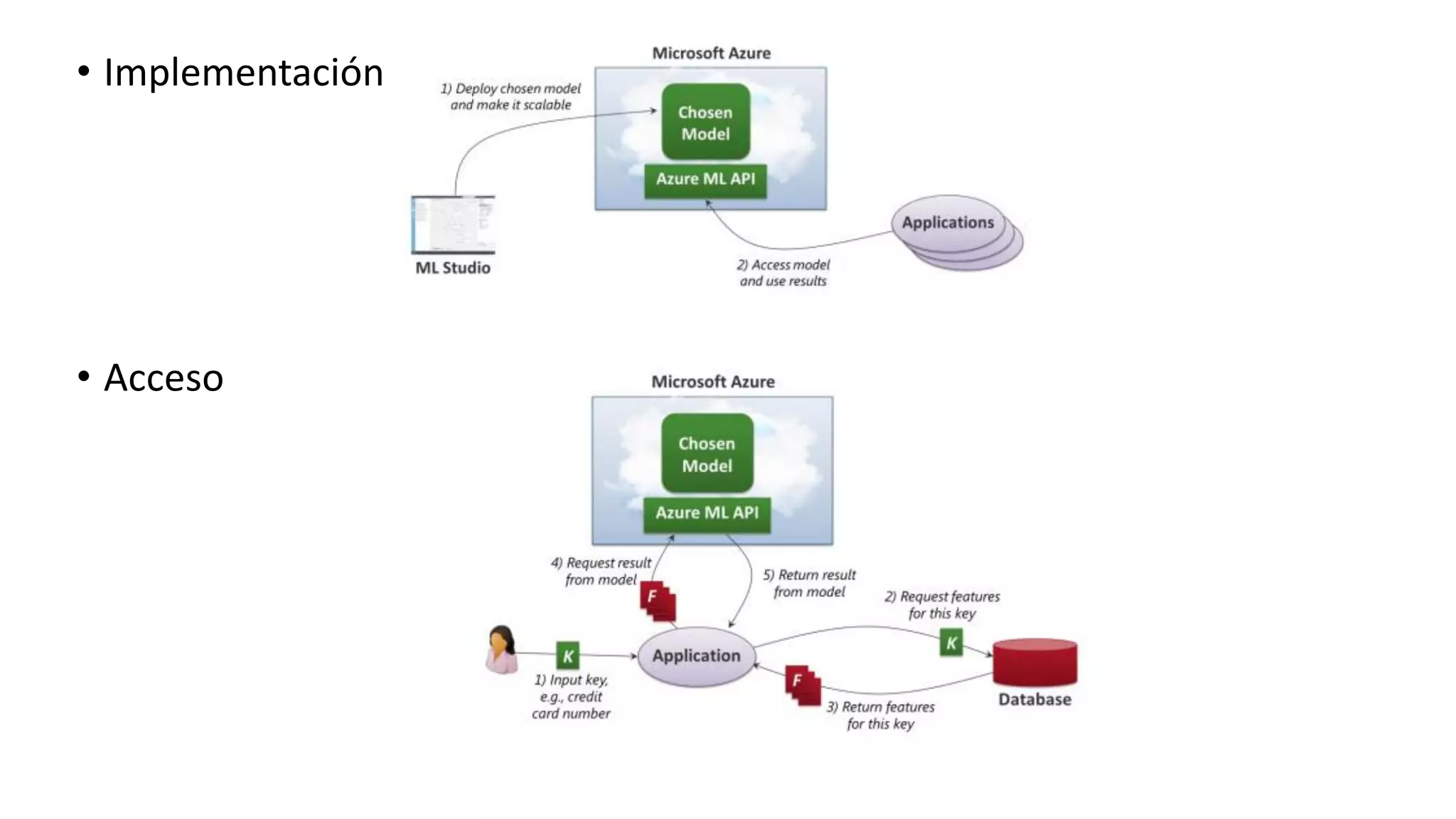

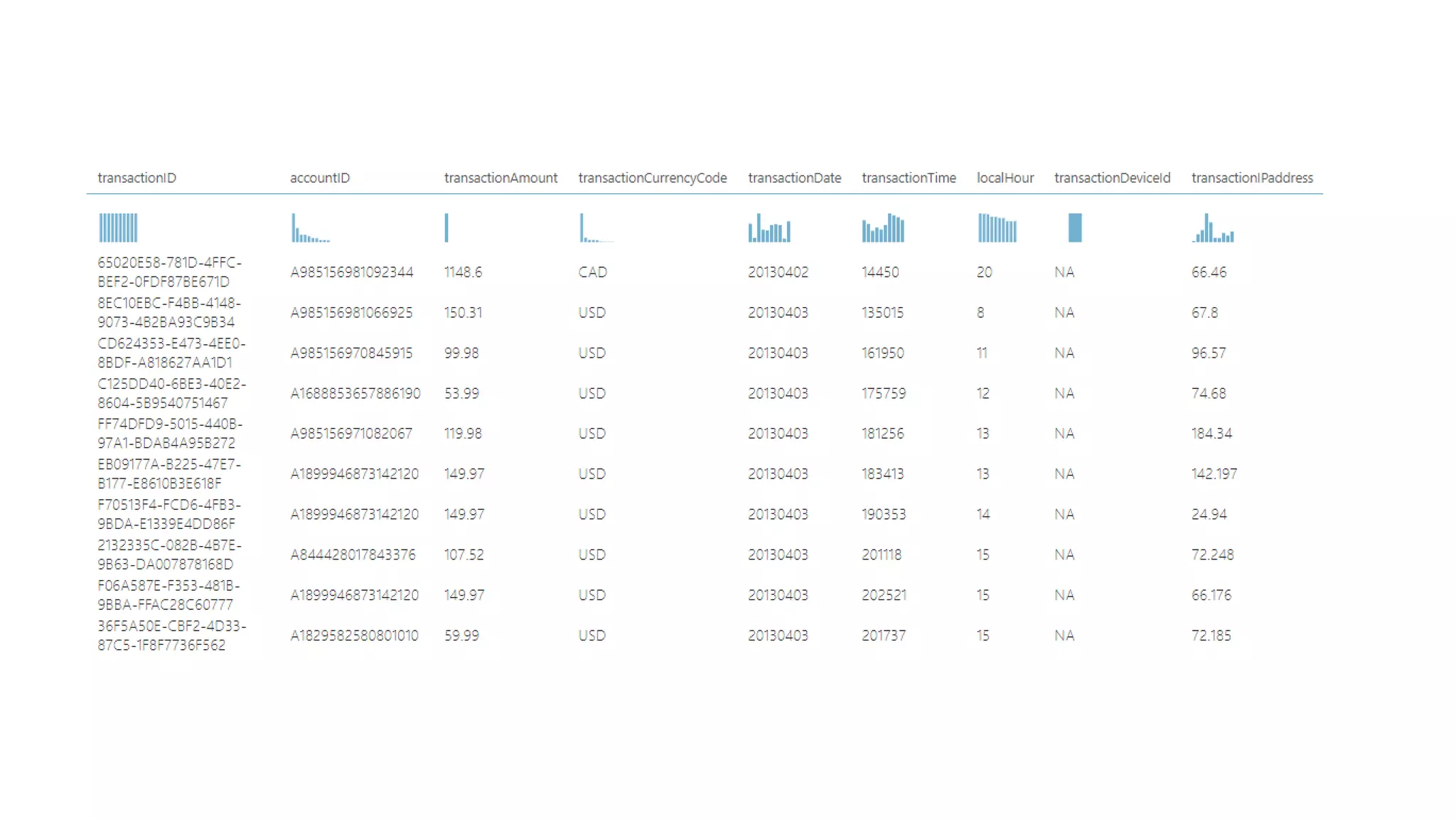
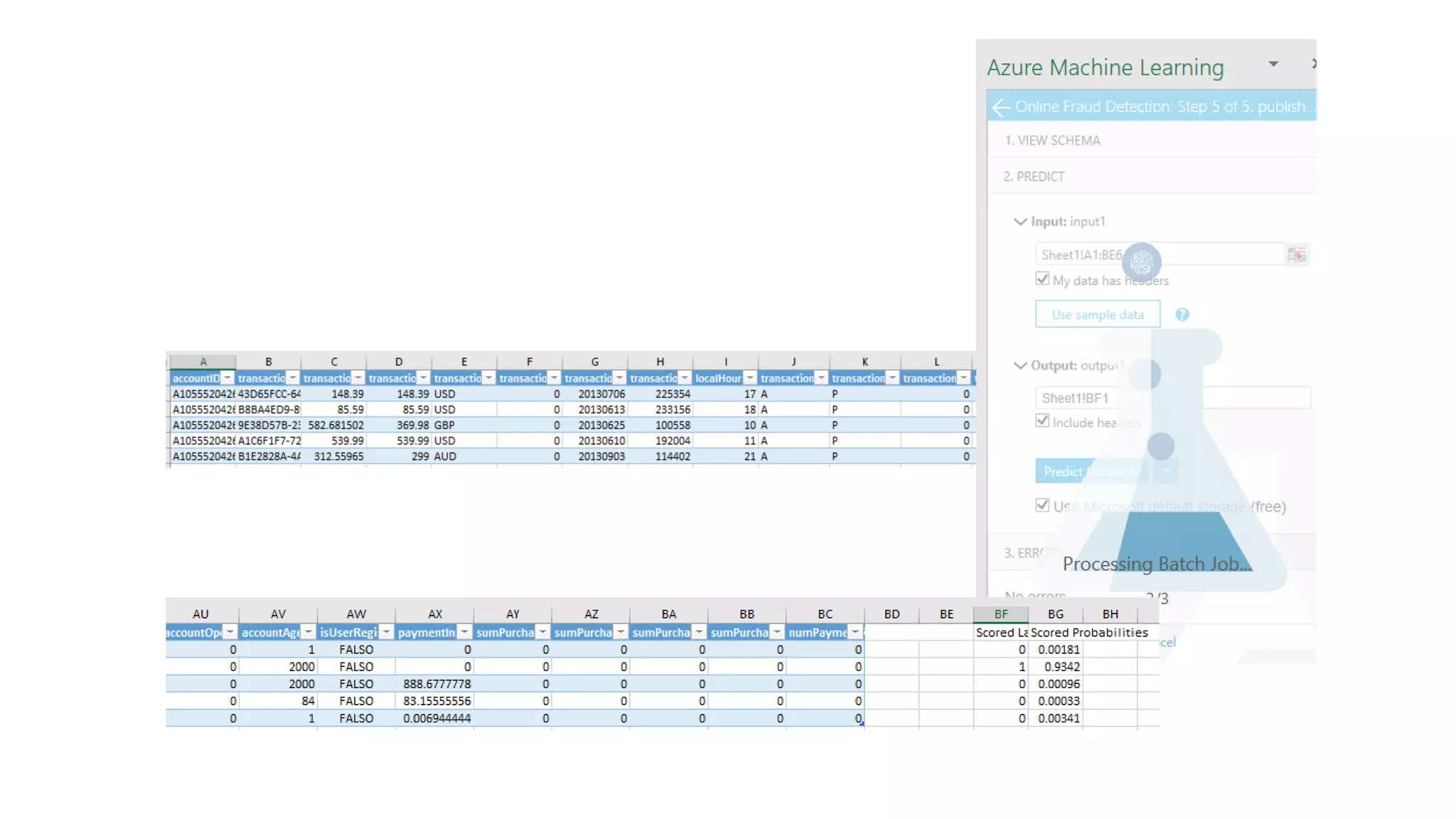





El documento habla sobre machine learning y su aplicación en Azure Machine Learning. Brevemente describe machine learning como sistemas que se vuelven más inteligentes a través de la experiencia y datos históricos. Luego explica que Azure Machine Learning facilita la construcción e implementación de soluciones analíticas utilizando machine learning a través de servicios en la nube. Finalmente, muestra una demostración de cómo se puede utilizar este servicio para cargar datos, limpiarlos, aplicar algoritmos de machine learning y crear servicios web.























































