Descargar para leer sin conexión






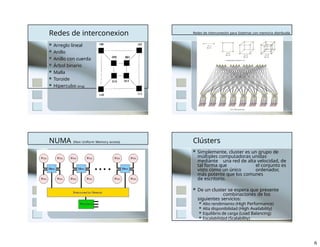




El documento ofrece una visión general de las supercomputadoras, definiéndolas como máquinas de alto rendimiento capaces de procesar grandes volúmenes de información en poco tiempo, con aplicaciones en la investigación científica y el análisis de datos. Se detalla la historia del desarrollo de estas computadoras, destacando a Seymour Cray y su influencia en el sector, y describe las distintas generaciones y clasificaciones de las arquitecturas de supercomputación, así como los clusters y grids como tecnologías relacionadas. Finalmente, se mencionan las tecnologías clave que sustentan el diseño moderno de supercomputadoras.



























