Descargar como PDF, PPTX





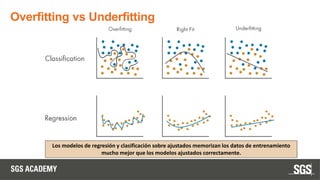

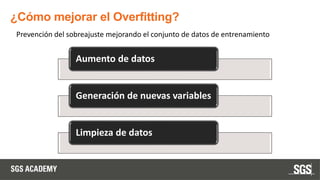
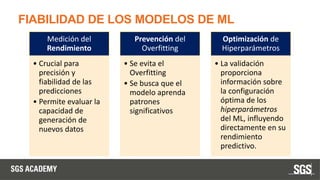
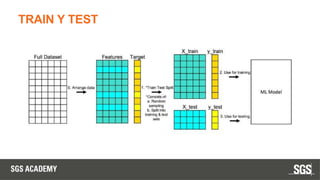

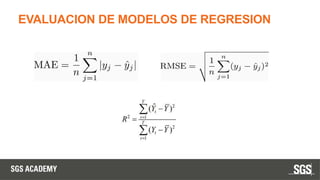
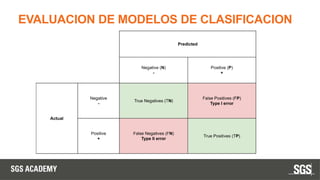

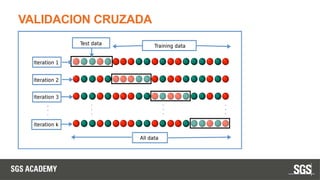




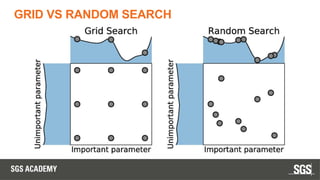










Este documento se centra en técnicas de validación en aprendizaje automático, incluyendo la separación de datos en conjuntos de entrenamiento y prueba, y la importancia de prevenir el sobreajuste (overfitting) y el subajuste (underfitting). Se discuten métodos como la validación cruzada, la optimización de hiperparámetros y métricas de evaluación como la precisión y el F1-score para evaluar el rendimiento de los modelos. Además, se abordan casos prácticos y la comparación de modelos mediante técnicas como grid search y random search.

















