Descargar como PDF, PPTX














































![NFL Theorem [Wolpert ‘97]
"Promediados sobre todos los problemas posibles dos algoritmos de optimización
cualesquiera son equivalentes"](https://image.slidesharecdn.com/testingarmeetupviii-luisargerich-theriseofthemachines-161026033314/75/TestingAR-Meetup-VIII-Luis-Argerich-Una-Breve-Introduccion-a-Machine-Learning-59-2048.jpg)




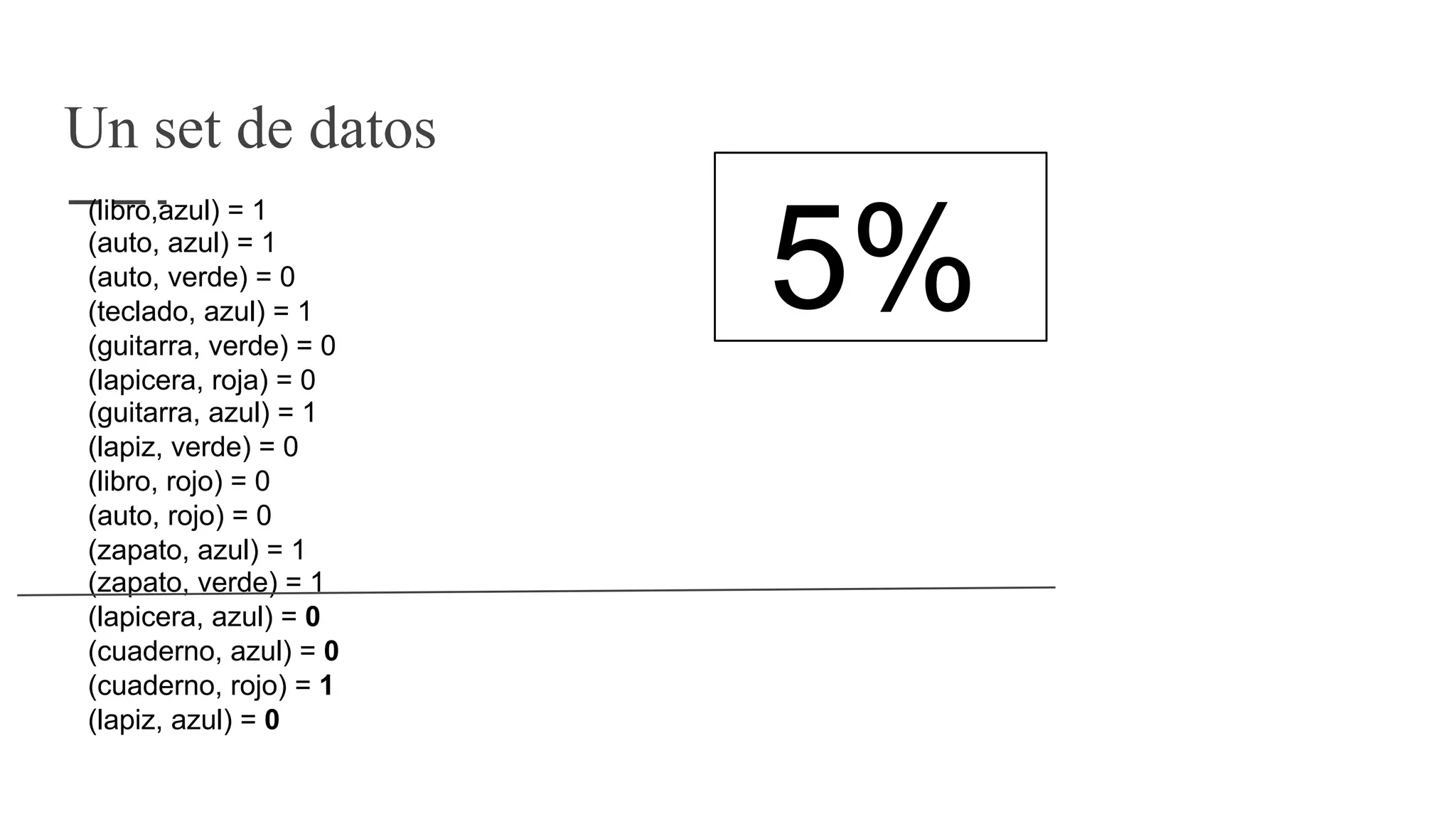


























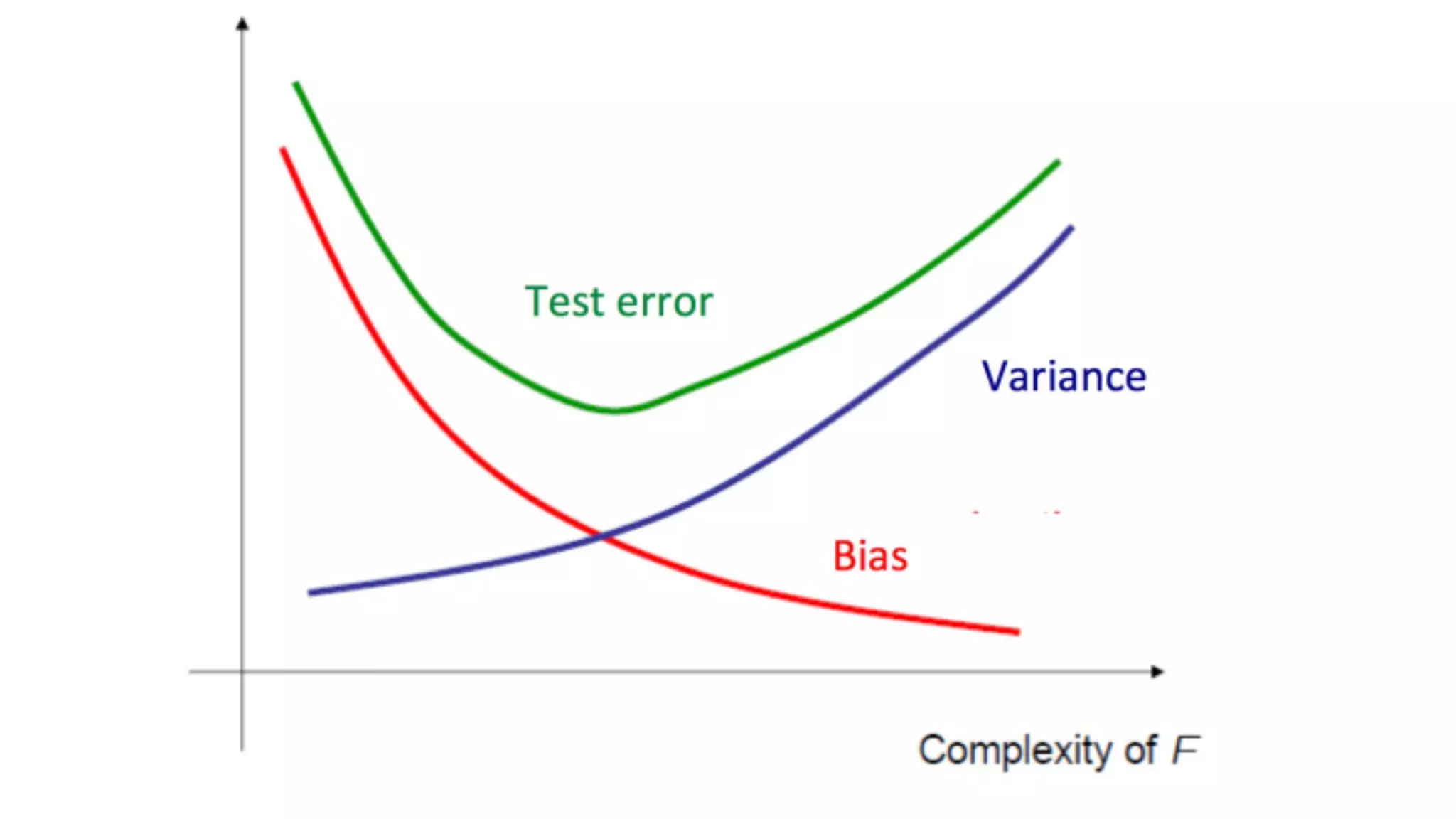
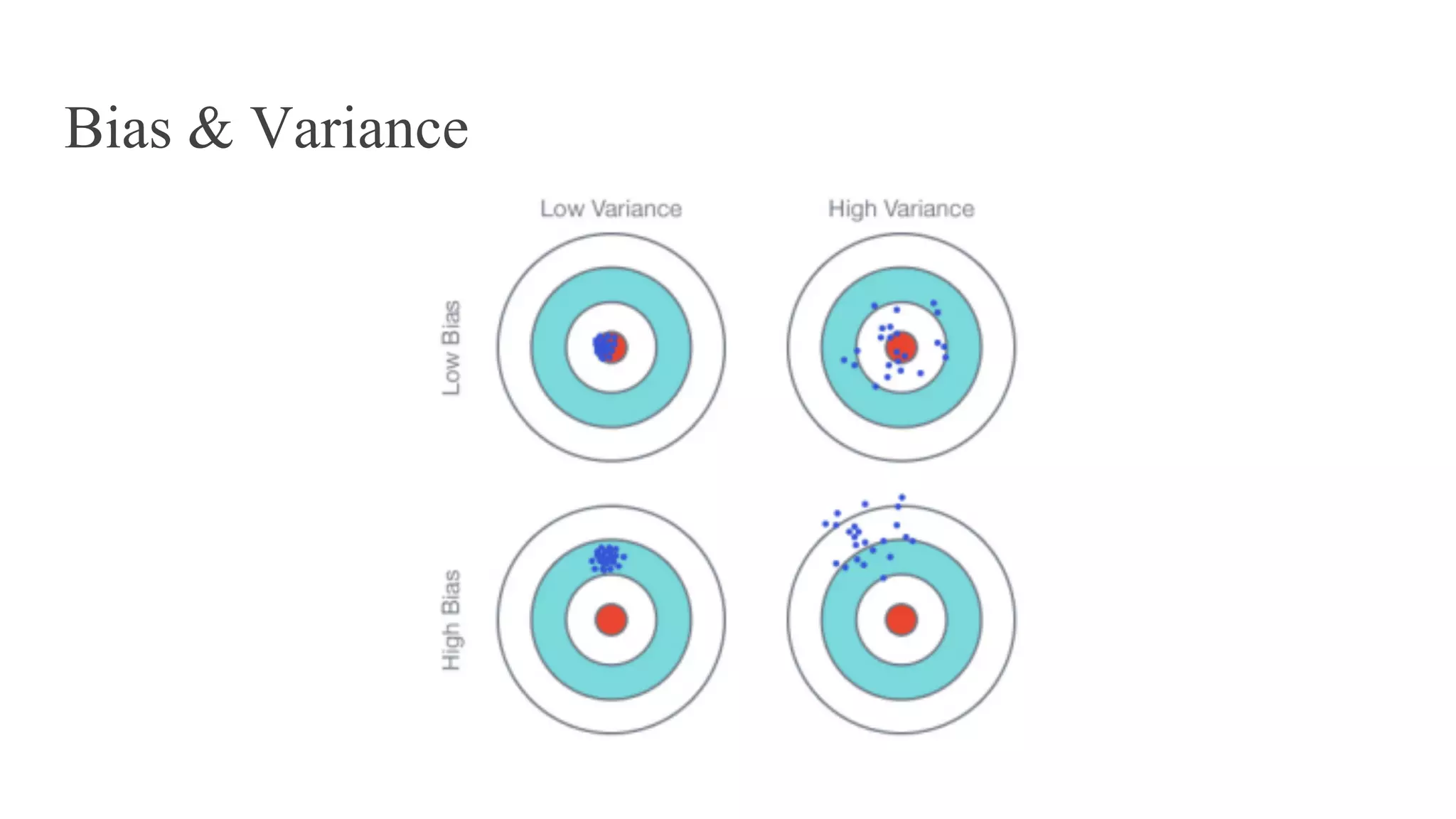
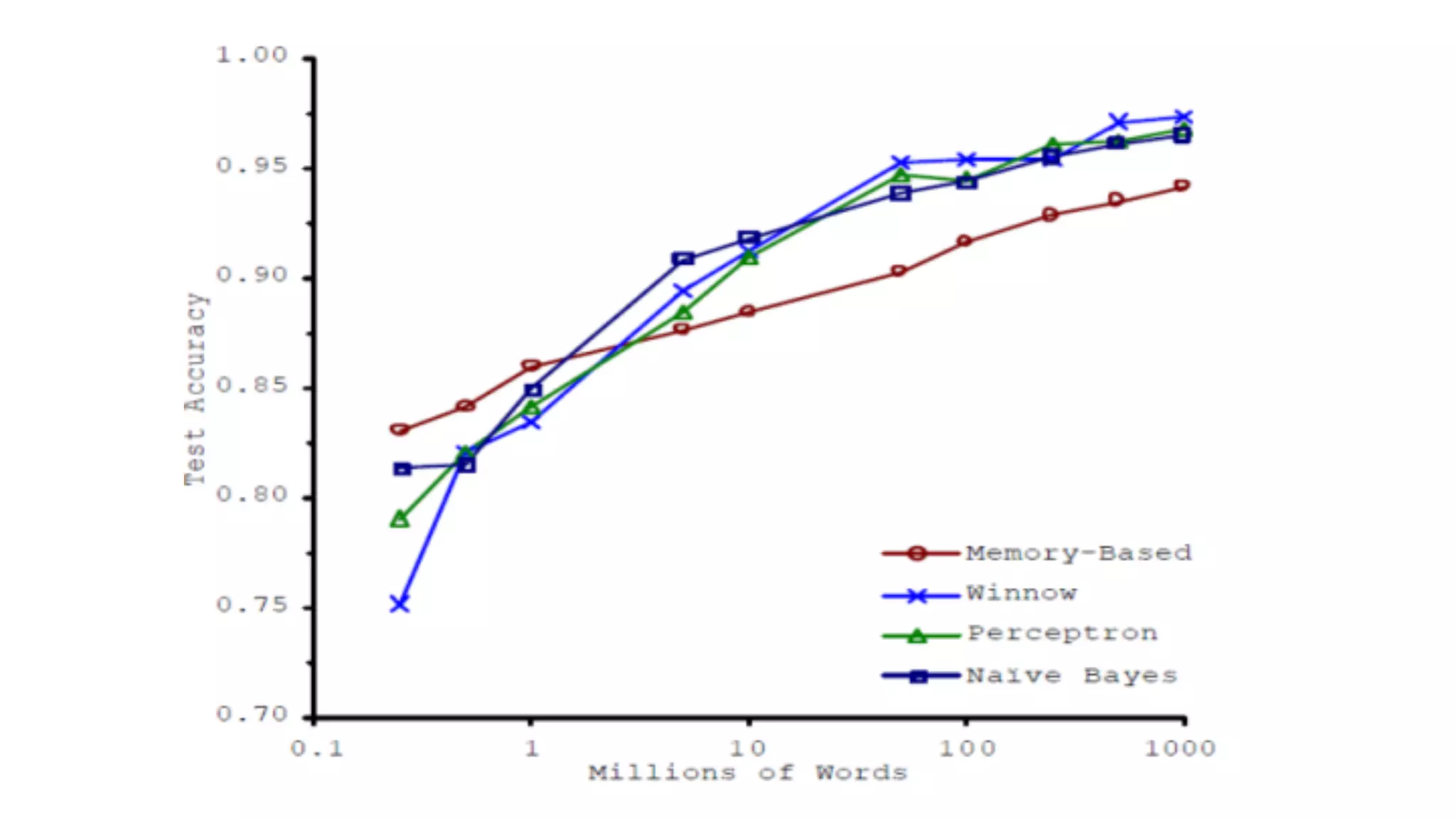
El documento proporciona una introducción al aprendizaje automático, destacando los tipos de algoritmos (supervisados y no supervisados), la importancia de la validación cruzada y la evaluación de modelos, así como conceptos clave como sobreajuste, subajuste y regularización. También se discuten las 'tribus' del aprendizaje automático, como simbolistas y conexionistas, y la importancia de la ingeniería de características y el ensamblaje de modelos. Finalmente, se resalta la necesidad de un enfoque artesanal en el proceso de machine learning, enfatizando la recolección y limpieza de datos, así como la reproducibilidad de los resultados.



































































