Descargado 204 veces


















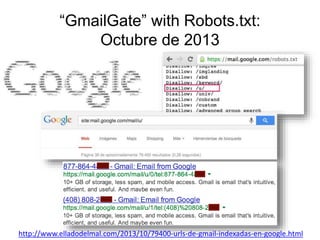
























El documento discute el uso de 'robots.txt' para prevenir la indexación de contenido en motores de búsqueda, destacando cómo puede ser utilizado para filtrar información sensible. Se presentan diversas situaciones y eventos relacionados con la indexación y filtrado de URLs en plataformas como Google y Facebook. Además, se analizan métodos para gestionar la exposición de información privada a través de configuraciones adecuadas.



























![DirtyTooth: It´s only Rock'n Roll but I like it [Slides]](https://cdn.slidesharecdn.com/ss_thumbnails/dirtytoothslides-170309122009-thumbnail.jpg?width=640&height=640&fit=bounds)










































