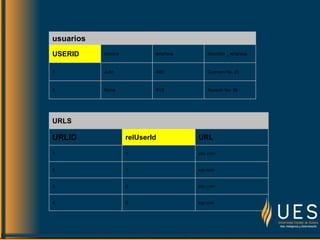
El documento describe el proceso de normalización de bases de datos. La normalización transforma los datos complejos en estructuras de datos más pequeñas y simples para hacerlas más fáciles de mantener y menos propensas a errores. Se explican las tres formas normales, que eliminan la redundancia y mejoran la integridad de los datos al separar tablas y usar claves primarias y externas. Se ilustra el proceso mediante un ejemplo de normalización de una tabla de usuarios en tres niveles.