Descargado 98 veces












![SAX
• Ejemplo: SimpleSAX
import java.io.*;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.SAXParser;
public class SimpleSAX extends DefaultHandler {
public void startElement(String ns, String local, String qName, Attributes atts) {
System.out.println("startElement: " + local);
}
public static void main(String[] args) throws SAXException {
SimpleSAX s = new SimpleSAX();
SAXParser p = new SAXParser();
p.setContentHandler(s);
try {
p.parse(args[0]);
} catch (Exception e) {
e.getMessage();
}
}
}](https://image.slidesharecdn.com/05-xmlyjava-110105014835-phpapp01/75/5-9-Curso-JEE5-Soa-Web-Services-ESB-y-XML-17-2048.jpg)





![SAX
• Contenido de un elemento
− Una vez que hemos visto cómo saber el principio y fin de un
elemento y los atributos de éste, es necesario poder acceder
al contenido del mismo.
− Puede estar formado por elementos hijos, información textual,
o una combinación de ambos
− A dicha información textual se accede mediante el método
characters, en forma de un array de caracteres
void characters(char[] ch, int start, int length)](https://image.slidesharecdn.com/05-xmlyjava-110105014835-phpapp01/75/5-9-Curso-JEE5-Soa-Web-Services-ESB-y-XML-23-2048.jpg)














![DOM
• Creación del analizador
− Ejemplo simple
import org.apache.xerces.parsers.DOMParser;
import org.w3c.dom.Document;
public class SimpleDOM {
public SimpleDOM(String uri) throws Exception {
System.out.println("Analizando el documento: " + uri + "...");
DOMParser parser = new DOMParser();
parser.parse(uri);
Document document = parser.getDocument();
}
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.out.println("Modo de empleo: SimpleDOM fichXML ");
System.exit(0);
}
new SimpleDOM(args[0]);
}
}](https://image.slidesharecdn.com/05-xmlyjava-110105014835-phpapp01/75/5-9-Curso-JEE5-Soa-Web-Services-ESB-y-XML-41-2048.jpg)
























![JAXB
• Ejemplo de código de unmarshalling:
public class Main {
public static void main( String[] args ) {
...
try {
JAXBContext jc = JAXBContext.newInstance( "alumnos" );
Unmarshaller u = jc.createUnmarshaller();
Alumnos als = (Alumnos) u.unmarshal(new FileInputStream(uri) );
TipoAlumno a = (TipoAlumno) als.getAlumno().get(0);
for (Iterator it=als.getAlumno().iterator(); it.hasNext(); ) {
TipoAlumno a = (TipoAlumno) it.next();
System.out.println("Alumno dni = " + a.getDni() + ", nota = " +a.getNota());
}
}
}](https://image.slidesharecdn.com/05-xmlyjava-110105014835-phpapp01/75/5-9-Curso-JEE5-Soa-Web-Services-ESB-y-XML-70-2048.jpg)
![JAXB
• Ejemplo de Marshalling:
public class Main {
public static void main( String[] args ) {
...
try {
JAXBContext jc = JAXBContext.newInstance( "alumnos" );
Unmarshaller u = jc.createUnmarshaller();
Alumnos als = (Alumnos) u.unmarshal(new FileInputStream(uri) );
TipoAlumno a = (TipoAlumno) als.getAlumno().get(0);
for (Iterator it=als.getAlumno().iterator(); it.hasNext(); ) {
TipoAlumno a = (TipoAlumno) it.next();
System.out.println("Alumno dni = " + a.getDni() + ", nota = " +a.getNota());
}
...
TipoAlumno ta = new TipoAlumno()
ta.setDni("12345679z");
ta.setNota("10");
als.add(ta);
Marshaller m = jc.createMarshaller();
// SI QUISIERA SALIDA POR PANTALLA
//m.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE);
//m.marshal( als, System.out );
// ahora escribimos a un fichero, en el correcto juego de caracteres
m.setProperty(Marshaller.JAXB_ENCODING, "ISO-8859-1");
FileOutputStream salida = new FileOutputStream("c:/xml/salida.xml");
m.marshal( als, salida);
...
}](https://image.slidesharecdn.com/05-xmlyjava-110105014835-phpapp01/75/5-9-Curso-JEE5-Soa-Web-Services-ESB-y-XML-71-2048.jpg)



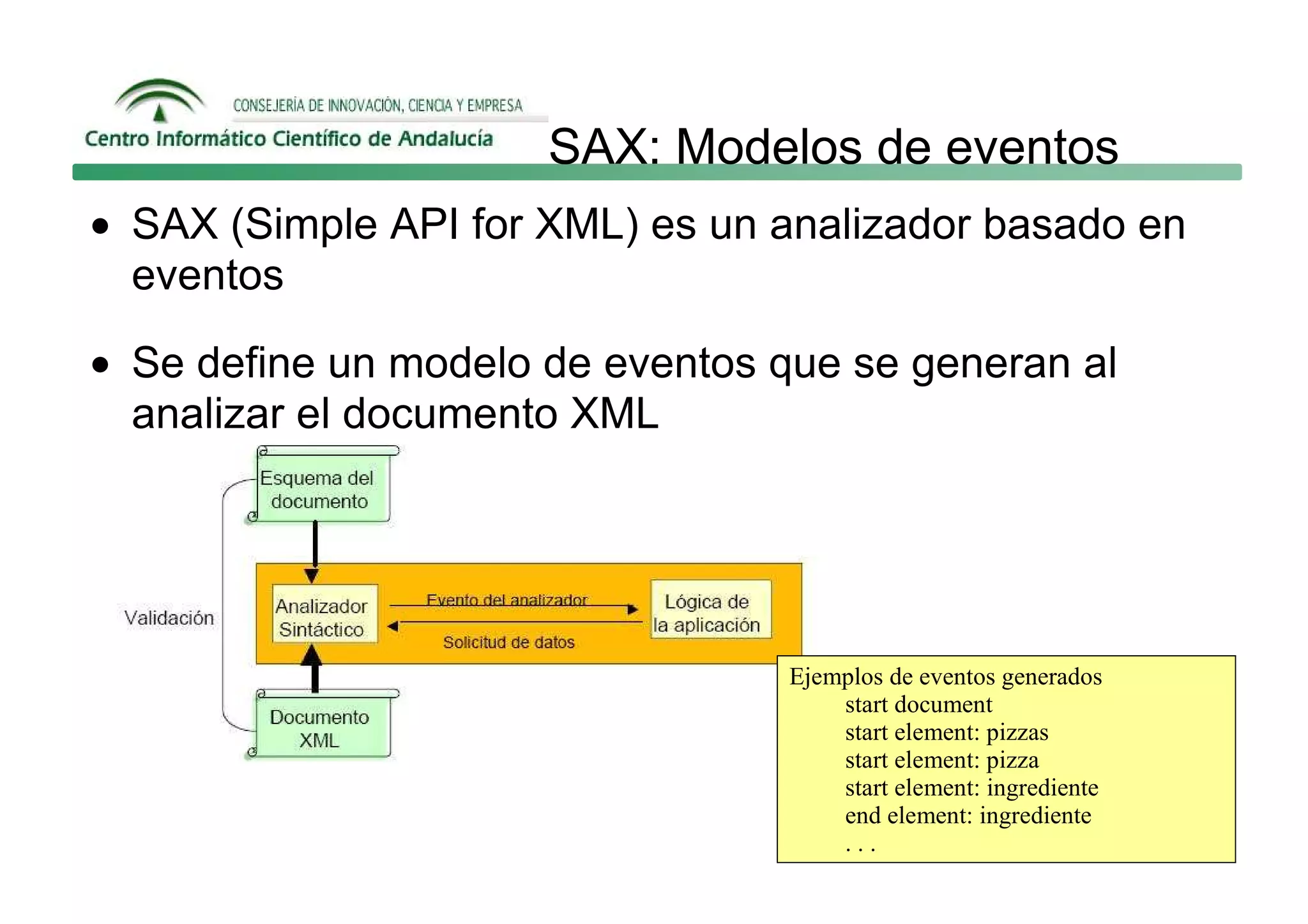
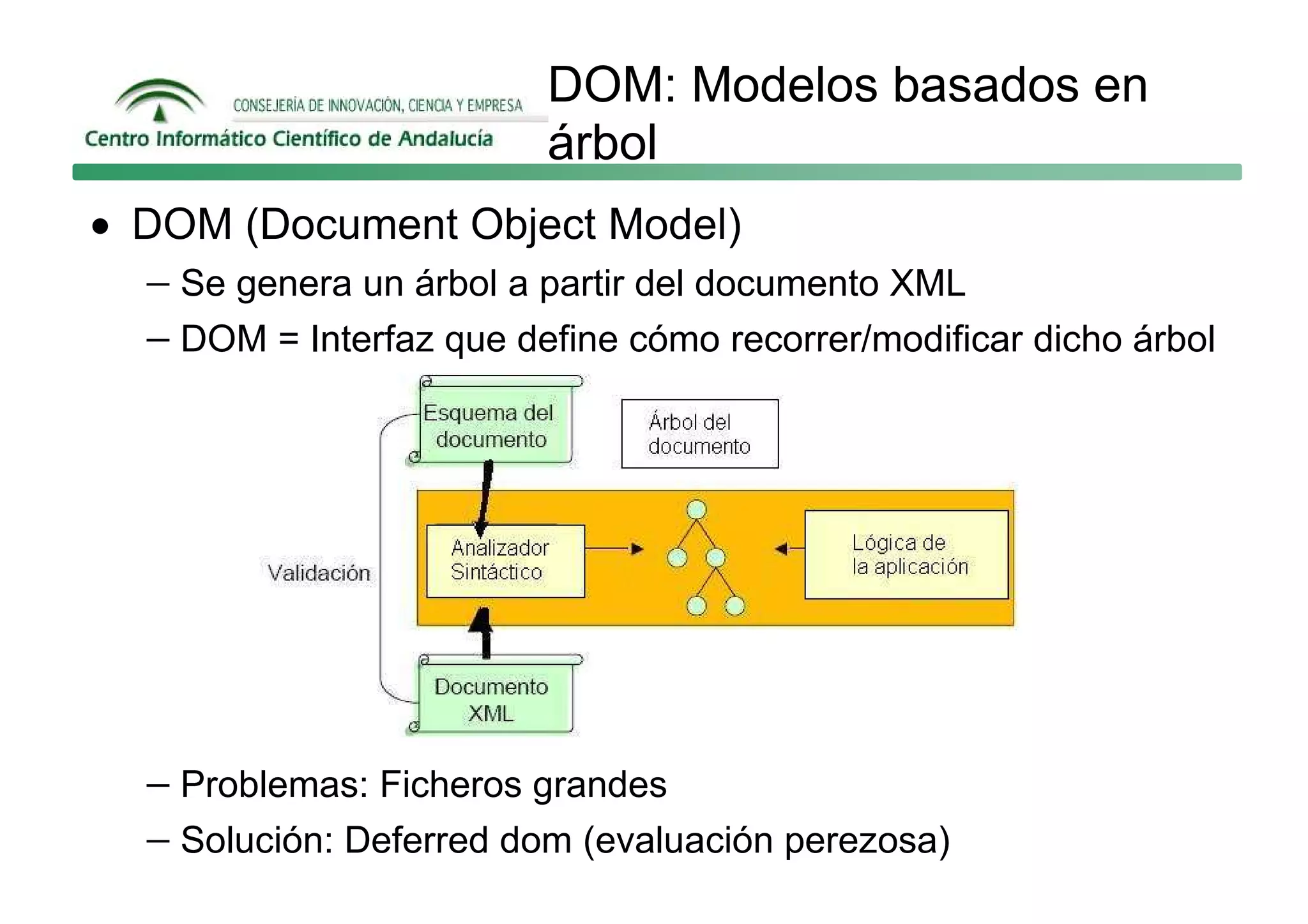
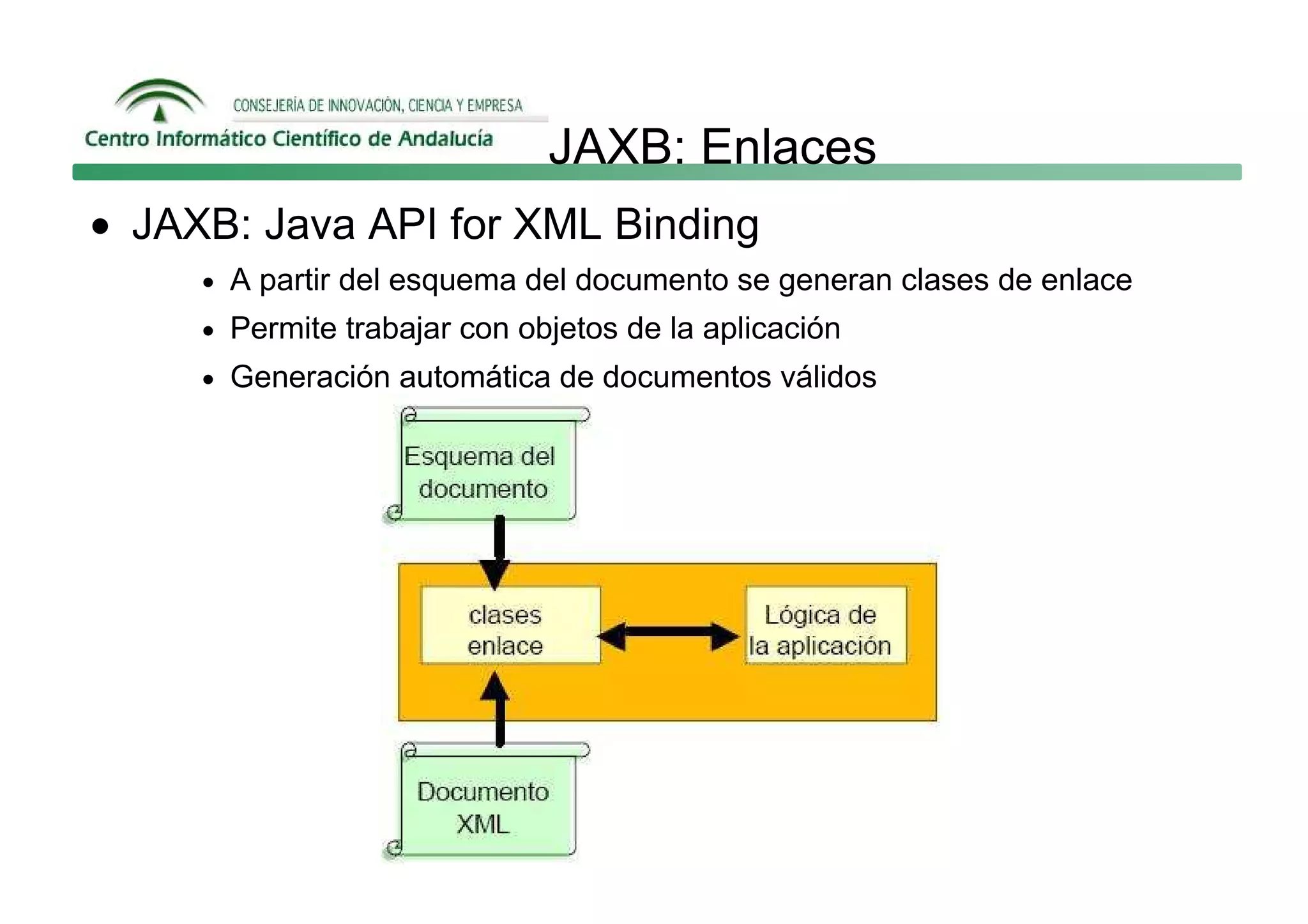
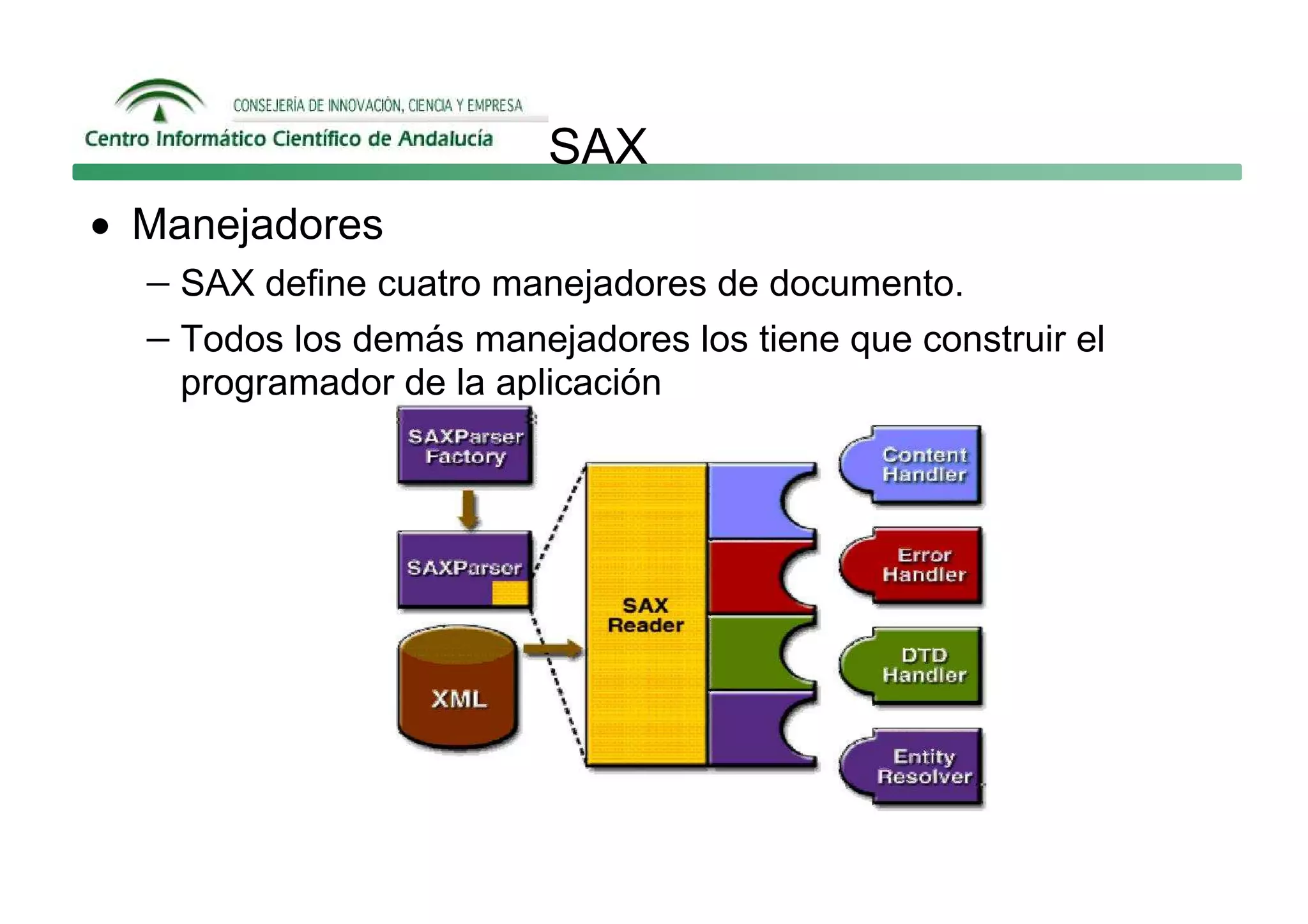
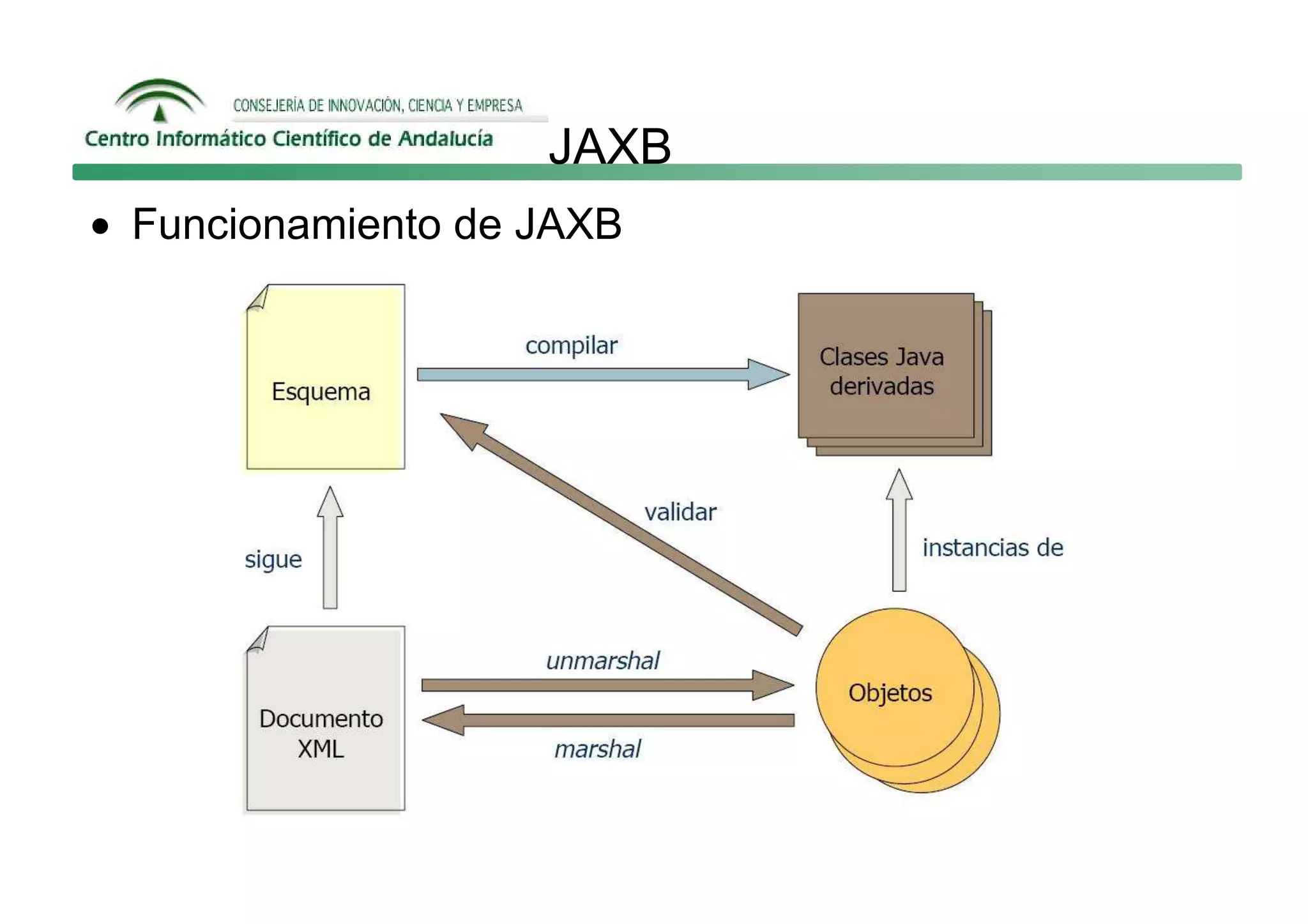
Este documento describe las principales formas de manipular documentos XML en Java: SAX, DOM y JAXB. SAX es un analizador guiado por eventos que genera eventos como startElement y endElement mientras analiza el documento. DOM carga el documento completo en memoria como un árbol de nodos. JAXB permite enlazar datos XML a objetos de Java.






























































