The document presents a talk by Joe Mészáros on revolutionizing online advertisement metrics using Enbrite.ly's antifraud, brand safety, and viewability products. It discusses the data collection and processing methods using Apache Spark on Amazon EMR, as well as real-world applications for detecting bot traffic in advertisements. The speaker emphasizes the importance of optimizing configurations, minimizing technical debt, and ensuring robust monitoring in distributed applications.





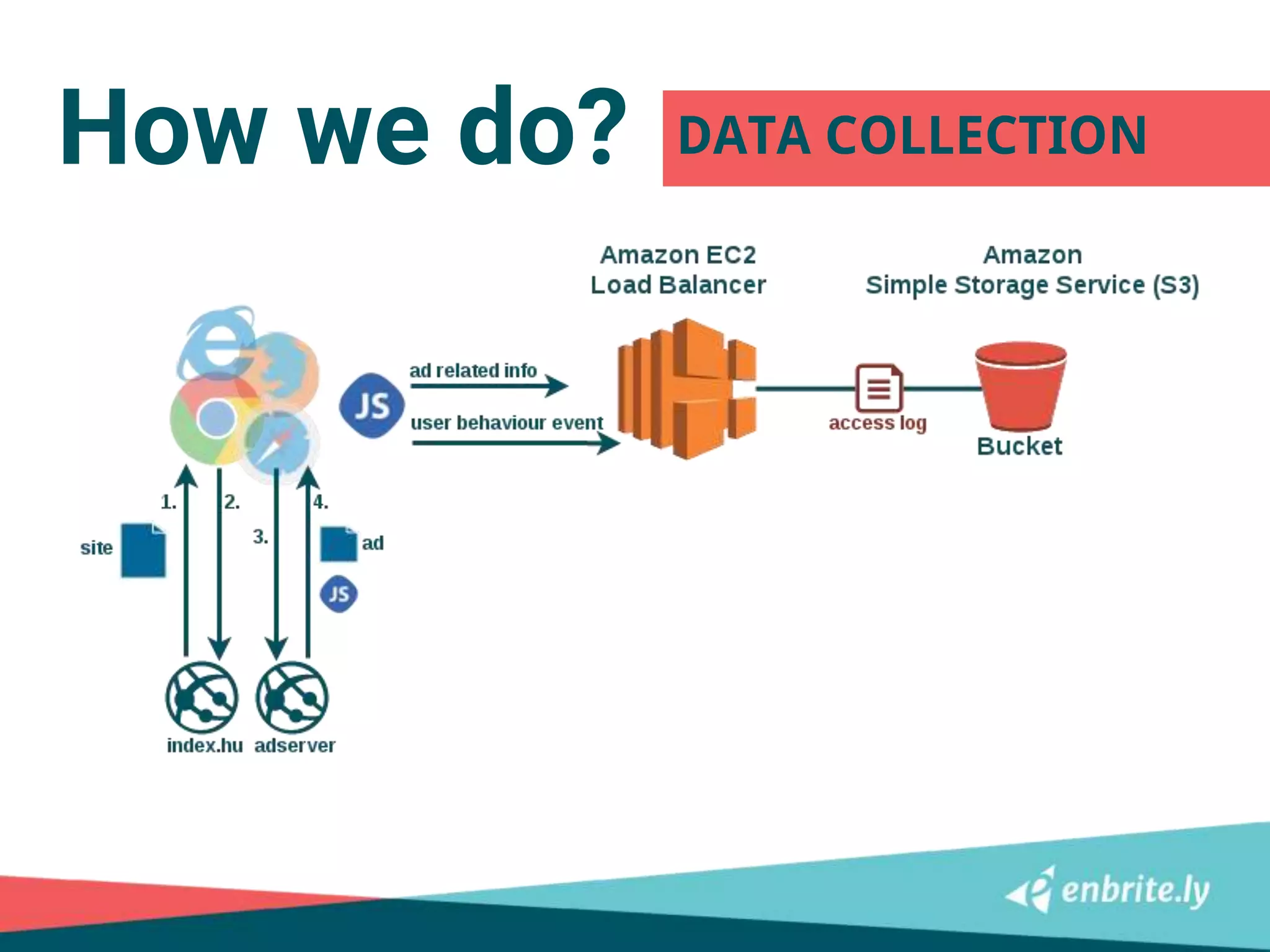



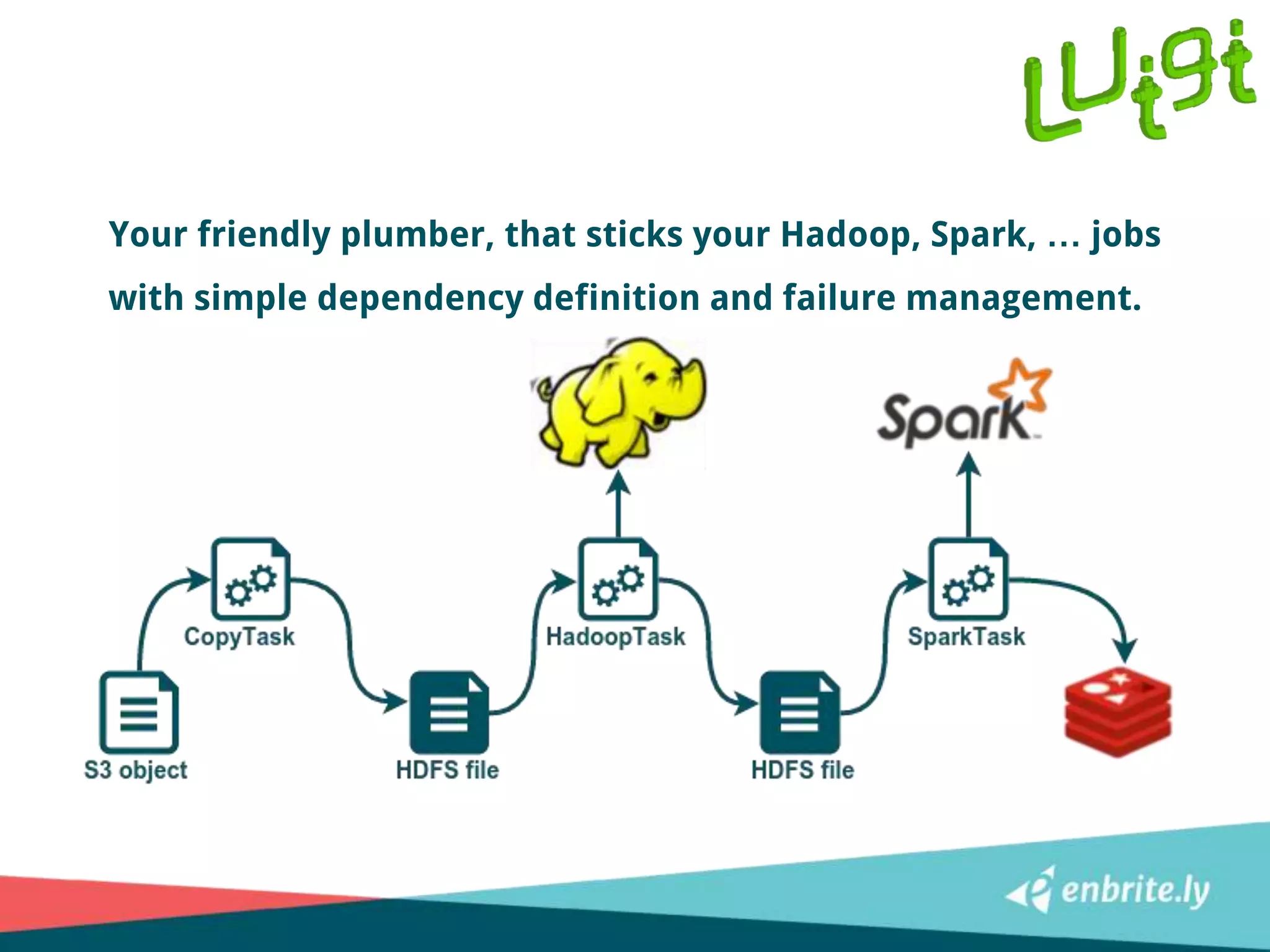


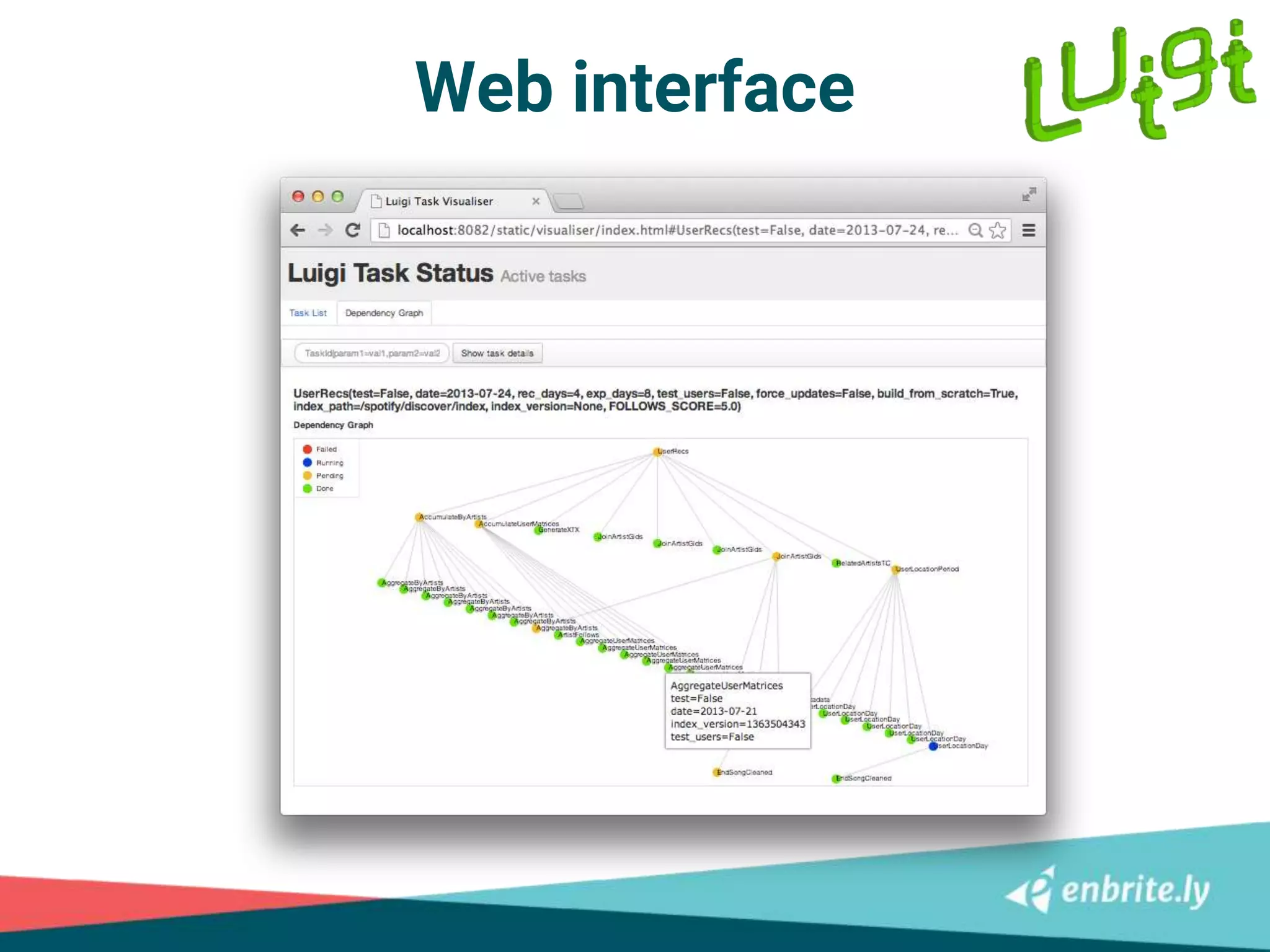


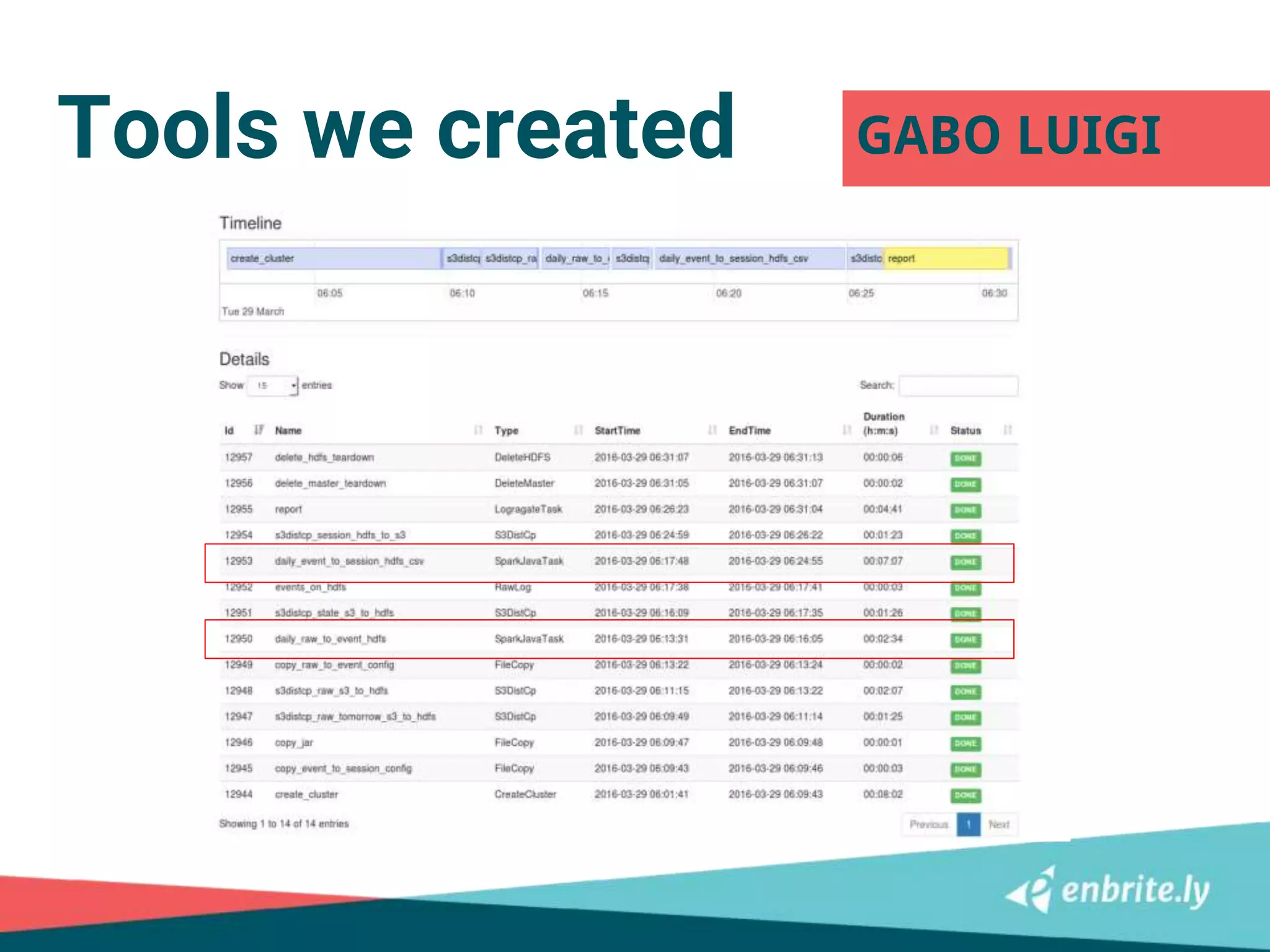







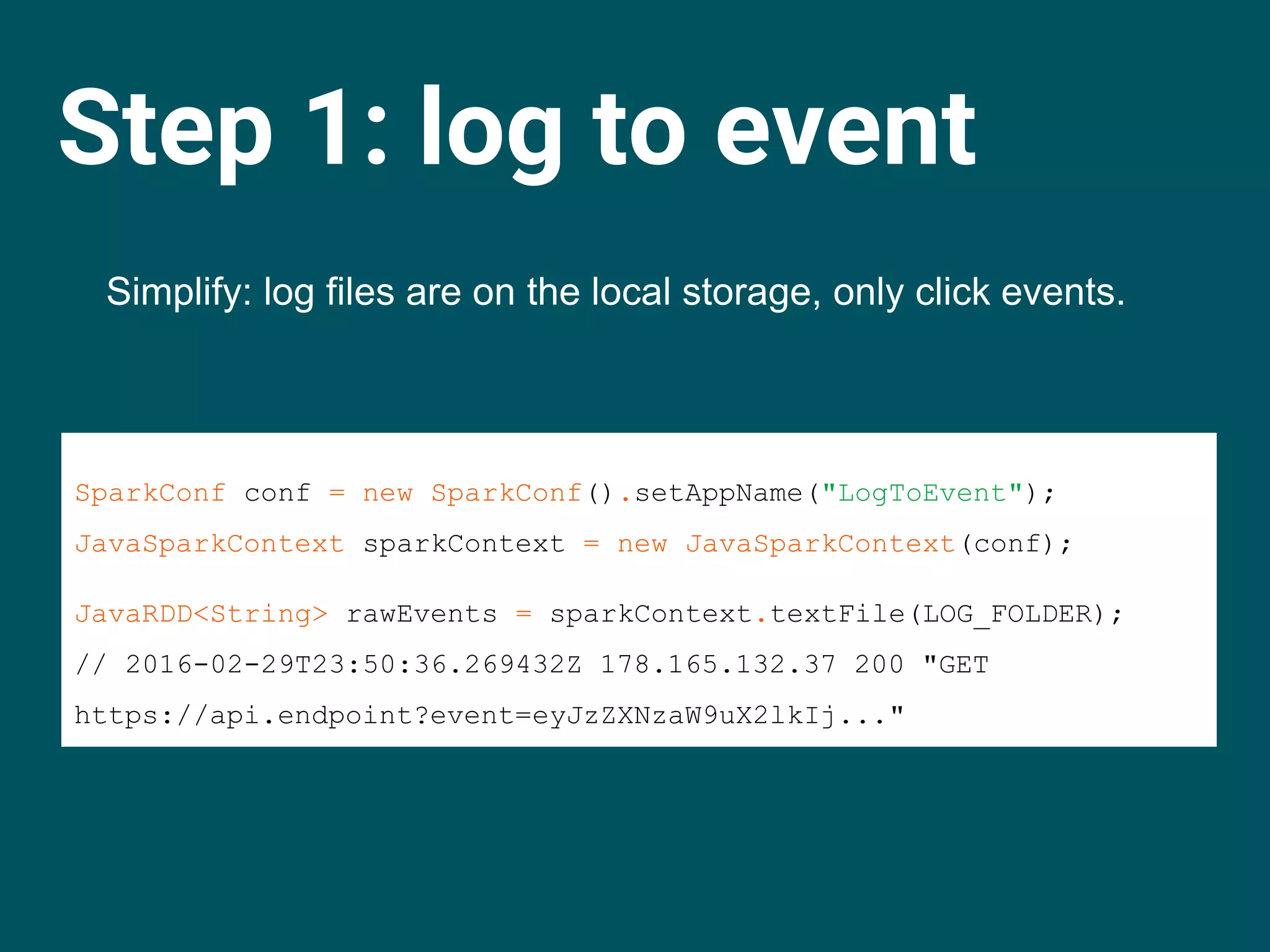
![Step 1: log to event
JavaRDD<String> rawUrls = rawEvents.map(l -> l.split("s+")[3]);
// GET https://api.endpoint?event=eyJzZXNzaW9uX2lkIj...
JavaRDD<String> rawUrls = rawEvents.map(l -> l.split("s+")[3]);
// GET https://api.endpoint?event=eyJzZXNzaW9uX2lkIj...
JavaRDD<String> eventParameter = rawUrls
.map(u -> parseUrl(u).get("event"));
// eyJzZXNzaW9uX2lkIj…
JavaRDD<String> rawUrls = rawEvents.map(l -> l.split("s+")[3]);
// GET https://api.endpoint?event=eyJzZXNzaW9uX2lkIj...
JavaRDD<String> eventParameter = rawUrls
.map(u -> parseUrl(u).get("event"));
// eyJzZXNzaW9uX2lk
JavaRDD<String> base64Decoded = eventParameter
.map(e -> new String(Base64.getDecoder().decode(e)));
// {"session_id": "spark_meetup_jsmmmoq",
// "timestamp": 1456080915621, "type": "click"}
IoUtil.saveAsJsonGzipped(base64Decoded);](https://image.slidesharecdn.com/apachesparkenbrite-160331144742/75/Budapest-Spark-Meetup-Apache-Spark-enbrite-ly-25-2048.jpg)




































![[Toroman/Kranjac] Red Team vs. Blue Team in Microsoft Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/fs0fswrr36f3q9puu3u6-signature-d4523b3bf020616e67040d2a940ba8bf9aeab187b20da49956548f98de22ea12-poli-180606121949-thumbnail.jpg?width=640&height=640&fit=bounds)




















![開源 x 節流:企業導入實例分享 (二) [2016/03/31] 文件自由日研討會](https://cdn.slidesharecdn.com/ss_thumbnails/20160321x-jasoncheng-160331145235-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)