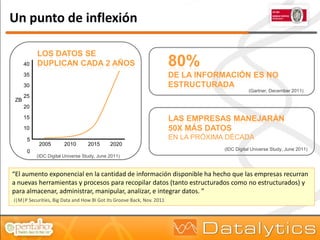
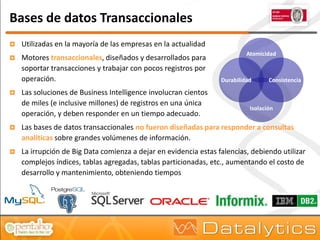
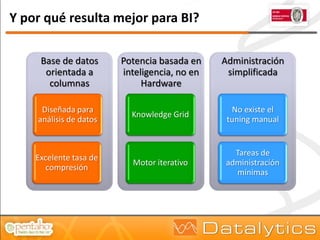
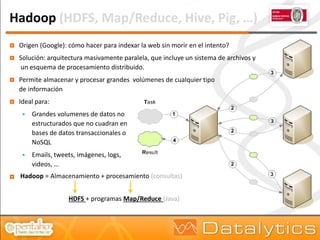
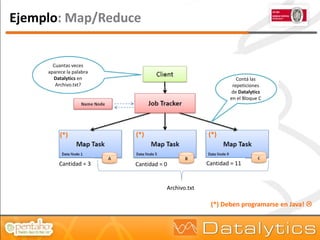
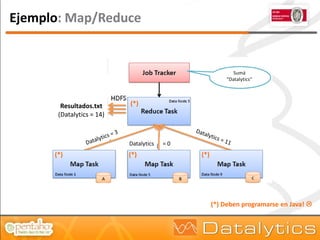
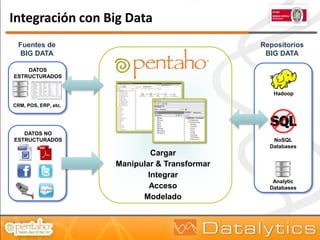
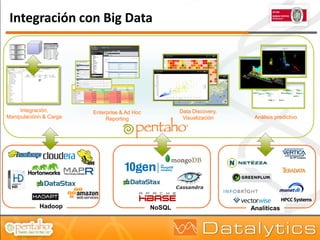
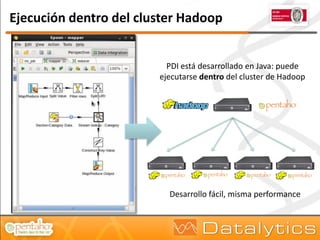
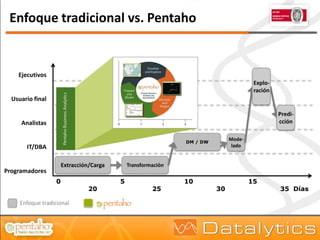
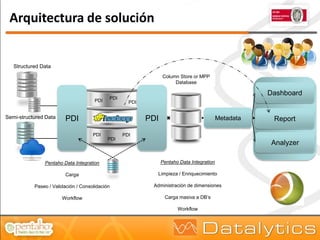
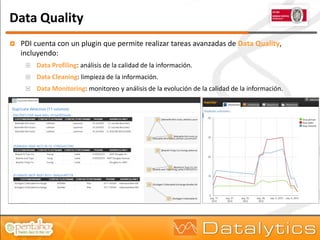
El documento aborda la evolución del concepto de 'big data', que se refiere a volúmenes masivos de datos que no pueden ser gestionados con las técnicas tradicionales. Se discuten diferentes tipos de bases de datos, como las transaccionales, NoSQL y analíticas, así como la importancia de tecnologías como Hadoop en el almacenamiento y procesamiento de datos. Además, se presentan características destacadas de Infobright, un motor de base de datos analítico que ofrece altas tasas de compresión y fácil administración.