Descargar para leer sin conexión












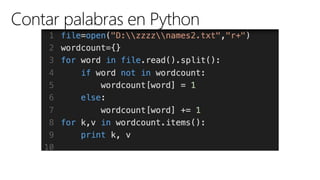














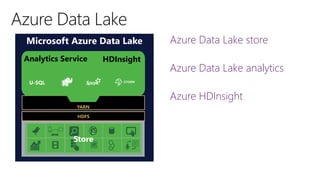
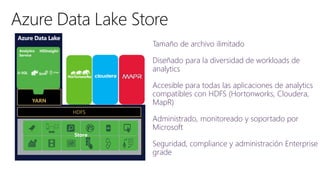





El documento discute los conceptos y herramientas relacionados con Big Data, enfocándose en la oferta de Microsoft Azure para el análisis de datos. Se mencionan tecnologías como Hadoop, U-SQL y Azure Data Lake, resaltando su capacidad para manejar grandes volúmenes y variedades de datos de manera escalable. También se citan ejemplos de grandes empresas que utilizan estas herramientas para sus operaciones de datos masivos.


















































