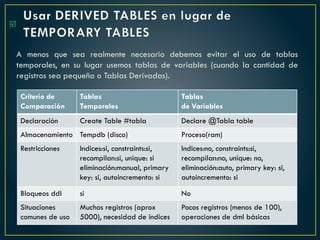
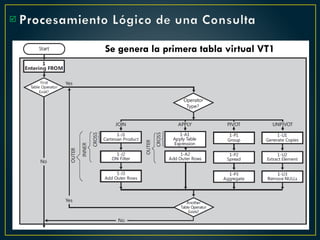
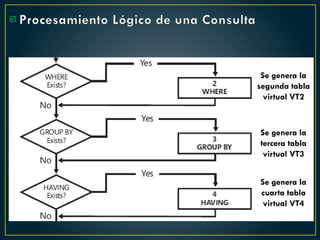
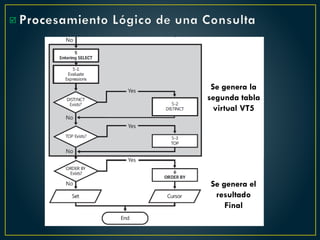
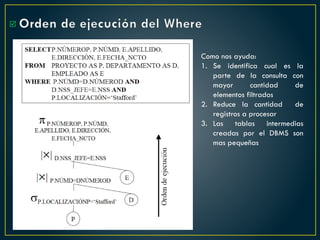
El documento proporciona una guía sobre cómo optimizar sentencias SQL, enfatizando la importancia de seleccionar solo las columnas necesarias, evitar el uso excesivo de conteos, y preferir la utilización de variables y tablas derivadas sobre temporales. Además, sugiere el uso de 'EXISTS' en lugar de 'IN', el manejo adecuado de los operadores en condiciones y la optimización del rendimiento mediante buenas prácticas en las consultas. También destaca errores comunes y cómo corregirlos para mejorar la eficiencia en las bases de datos.




![Usar Nombre de las columnas
Al igual que en los select debemos utilizar los nombres de las columnas de las
tablas al momento de hacer los queries de insert.
Usar
INSERT INTO [proveedor]
([IdProveedorAch], [Nombre])
VALUES
(1000, 'El Proveedor 100')
GO
En lugar de
INSERT INTO [proveedor]
VALUES
(1000, 'El Proveedor 100')
GO
Usar
INSERT INTO [proveedor]
([IdProveedorAch], [Nombre])
VALUES
(@IdProveedor, @NombreProveedor)
GO
En lugar de
INSERT INTO [proveedor]
VALUES
(@IdProveedor, @NombreProveedor)
GO](https://image.slidesharecdn.com/ditic-desarrollodesistemasrecomendacionesbd-240711025930-639d15ee/85/DITIC-Desarrollo-de-Sistemas_Recomendaciones_BD-pdf-4-320.jpg)

















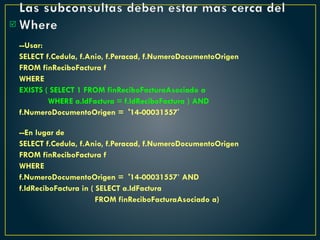









![Union y Distinct
Recordar que el UNION muestra los registros diferentes de la unión
de las consultas, por lo que no es necesario aplicar la operación de
distinct.
Se recomienda no utilizar operaciones innecesarias ya que
consumen tiempo de procesamiento y memoria del servidor.
En lugar de
Select distinct [IdSolicitudBS],
[Numero], [FechaDocumento]
from solicitud_bs s where (s.idestatus
= 12 and s.presupuestario = 0)
Union
Select distinct [IdSolicitudBS],
[Numero], [FechaDocumento]
from solicitud_bs s where (s.idestatus
= 55 and s.presupuestario = 1)
Usar
Select [IdSolicitudBS], [Numero],
[FechaDocumento]
from solicitud_bs s where (s.idestatus
= 12 and s.presupuestario = 0)
Union
Select [IdSolicitudBS], [Numero],
[FechaDocumento]
from solicitud_bs s where (s.idestatus
= 55 and s.presupuestario = 1)
](https://image.slidesharecdn.com/ditic-desarrollodesistemasrecomendacionesbd-240711025930-639d15ee/85/DITIC-Desarrollo-de-Sistemas_Recomendaciones_BD-pdf-37-320.jpg)











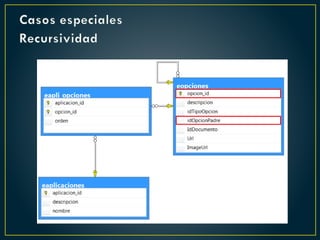
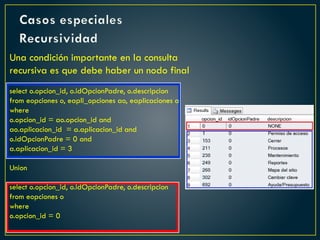
![Casos especiales
Recursividad
Estructura de una CTE Recursiva
WITH cte_name ( column_name [,...n] )
AS
(
CTE_query_definition -- Elemento inicial/Padre/Delimitador
UNION ALL
CTE_query_definition -- Elemento Hijo/Recursivo
)
SELECT ( column_name [,...n] -- Statement using the CTE
FROM cte_name](https://image.slidesharecdn.com/ditic-desarrollodesistemasrecomendacionesbd-240711025930-639d15ee/85/DITIC-Desarrollo-de-Sistemas_Recomendaciones_BD-pdf-50-320.jpg)