Descargado 223 veces










![➢ Solr vs SolrCloud
▪ Búsqueda distribuida entre Collections (siempre que sean compatibles).
http://[solr_host]:[solr_port]/solr/select?collection=collection1,collection2
▪ Las queries enviadas a cualquier nodo realizan automáticamente una búsqueda distribuida completa a través del clúster con
load-balancing y fail-over (tolerancia a errores). Es posible, también, configurar SolrCloud con la características
shards.tolerant=true para devolver sólo los documentos que están disponibles en los shards “vivos”, es decir que si un
servidor no respondiera, la consulta continúa al siguiente shard/servidor levantado.
http://[solr_host]:[solr_port]/solr/select?shards=[solr_host]:[solr_port]/solr,[solr_host]:[solr_port]/solr&indent=true&q=t
raining+solr
▪ Los updates que sean enviadas a cualquier nodo del cluste son automáticamente remitidas al shard correcto y replicadas a los
multiples nodos redundantemente.
▪ Nuevo campo _version_ (updateLog depende de este campo) para la actualización get/partial de documentos en modo Near
Real-time.
▪ Una nueva implementación del spellchecker introducida con solr.DirectSolrSpellchecker. Permite usar el índice principal para
proporcionar sugerencias para la correcció ortográfica y se realiza “on the fly” sin necesidad de ser reconstruido tras cada
commit.
1. Introducción (IX): Solr vs SolrCloud](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-13-2048.jpg)



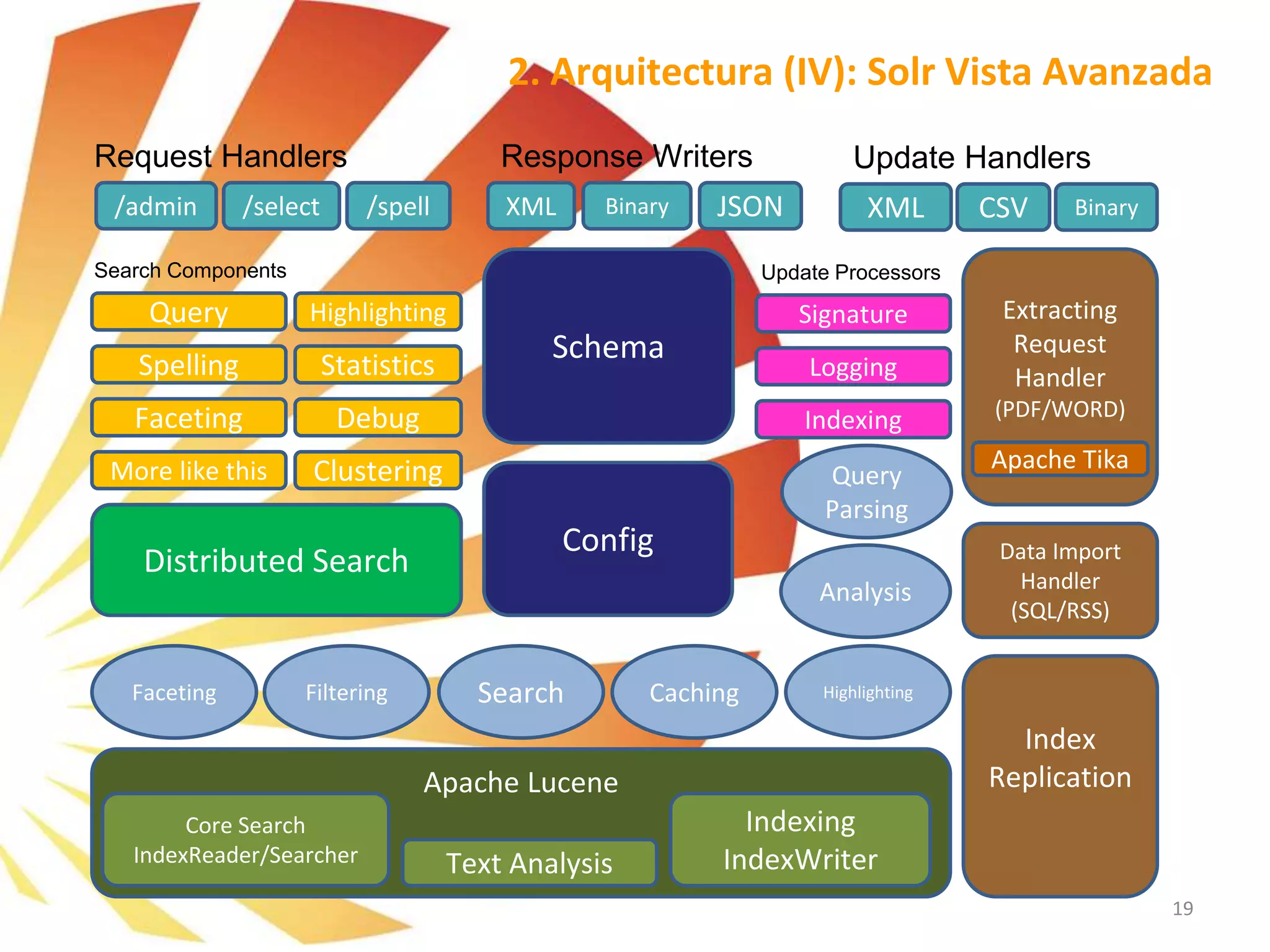
![➢ Components, Handlers, Parsers y Analyzers
▪ RequestHandlers: Maneja las peticiones (request) con URL’s REST-style. Por ejemplo: “/select”
▪ SearchComponents (parte de SearchHandler) Componentes que controlan las peticiones:
▪ Incluye: Query, Facet, Highlight, Debug, Stats
▪ Capacidad de Búsqueda distribuida.
▪ UpdateHandlers: Permite indicar de qué menara se producen las peticiones de actualización / indexación.
▪ Update Processors: Se configuran cadenas de componentes “per-handler” para manejar las actualizaciones.
▪ Query Parser plugins (QParser): Solr permite una gran variedad de métodos de consulta, los más habituales son:
▪ Standard Query Parser: Es el más habitual, proviene Lucene Query Parser, pero añade Range Queries ([a TO z]),
negative queries (-abierto:false, que encontraría todos los campos con valores donde abierto es NO falso)
▪ Dismax Query Parser: Método de consulta que permite al usuario influir en los resultados con un Sistema basado en
coeficientes de prioridad “weighting (boosts)”
▪ eDismax Query Parser: Extiende las funcionalidades del Qparser Dismax, añadiendo condiciones AND, OR, NOT, -, and
+. Mejora el Sistema de coeficientes.
▪ Text Analysis plugins: Analyzers, Tokenizers, TokenFilters
▪ Field analyzers: se usan durante el tiempo de indexación (update) y en tiempo de consulta (query). El analizador
examina los campos y genera una cadenas de tokens. Los “Analyzers” pueden ser una única clase o puede estar
compuesta de Tokenizers y Filters.
▪ Tokenizers: dividen los datos en unidades con sentido léxico, el más habitual StandardTokenizer (espacios, puntuación)
▪ Filters: revisan las cadenas de tokens y los manipulan, transforman, ignoran o crean nuevos (stemming/raíz semántica)
Tokenizers and Filters pueden ser combinados para formar cadenas, que resultan en un proceso de transformación dónde la
salida de uno es la entrada del siguiente para mejorar la búsqueda o la idexación.
▪ ResponseWriters: Componentes que serializan y transmiten la respuesta al cliente.
2. Arquitectura (V): Lucene/Solr Plugins](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-20-2048.jpg)
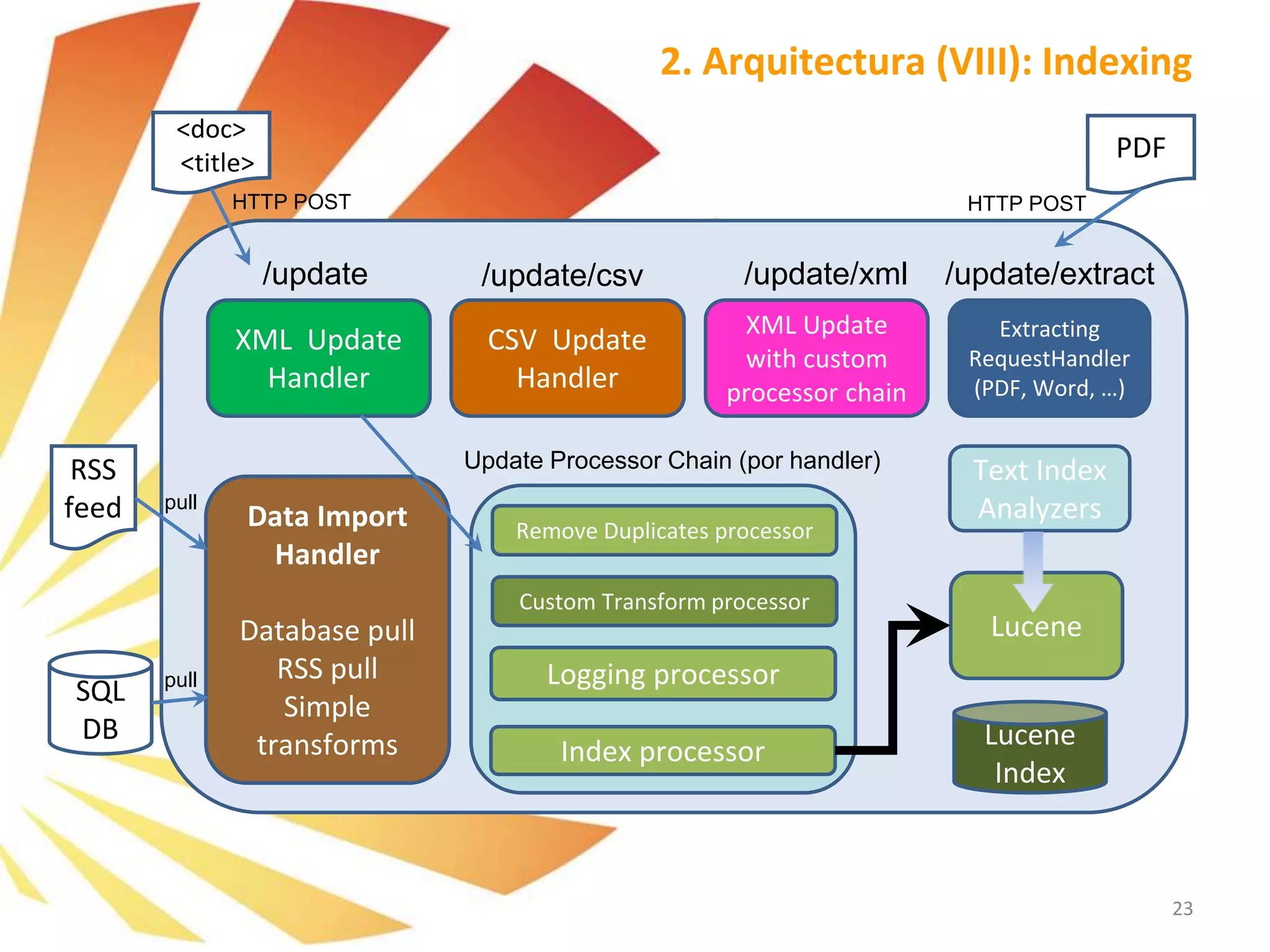











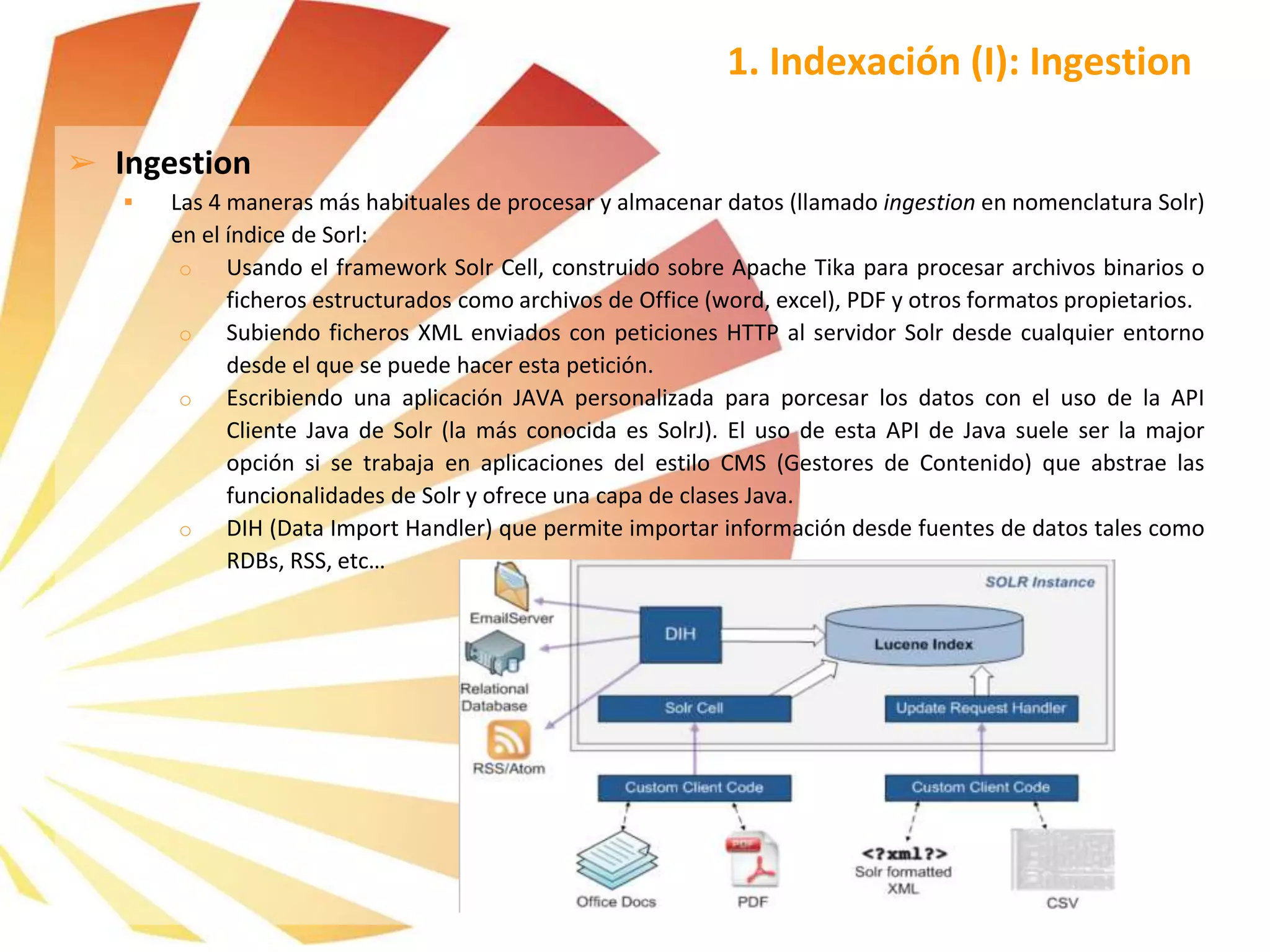



![➢ Ingestion via Solr XML HTTP
Ejemplos de usos de la indexación vía Solr XML (HTTP requests), para ello usamos curl para realizar las
peticiones HTTP y realizar las actualizaciones mediante el Update Request Handler.
1. Se puede usar la opción curl --data-binary para anexar el mensaje XML al commando curl y generar la
request HTTP POST:
curl http://[solr_host]:[solr_port]/solr/mi_collection/update -H "Content-Type: text/xml" --data-binary '
<add>
<doc>
<field name="id">0001A</field>
<field name="tipo">text/xml</field>
<field name="categoria">accesorios_de_interior_de_armario</field>
<field name="titulo">Cesta rejilla lateral Spaceo</field>
<field name="fichero_caracteristicas">centa_rejilla_lateral.xml</field>
<field name="contenido">Cesta de rejilla indicada para colocar tu ropa y complementos dentro del armario. De
80 x 50 cm. Es extraíble para acceder a su contenido con una mayor comodidad.</field>
</doc>
</add>‘
2. También se puede hacer POST de los mensajes XML contenidos en un fichero con la siguiente sintaxis:
curl http://[solr_host]:[solr_port]/solr/mi_collection/update -H "Content-Type: text/xml" --data-binary
@midoc.xml
1. Indexación (V): Ingestion](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-40-2048.jpg)
![➢ Ingestion via CSV
Es posible realizar indexaciones de contenidos almacenados en ficheros CSV.
1. Se puede usar la opción curl --data-binary para anexar el fichero CSV y posteriormente se le indica el
tipo de contenido añadiendolo en el Head con la opción -H:
curl “http://[solr_host]:[solr_port]/solr/update?rowid=id" --data-binary @myfile.csv -H 'Content-
type:application/csv; charset=utf-8‘
2. El CSV Update Handler permite también recoger el fichero almacenado en el File System de la
siguiente forma:
curl ‘http://[solr_host]:[solr_port]/solr/update/csv?stream.file=exampledocs/
data.csv&stream.contentType=text/plain;charset=utf-8’
Entre los muchos parámetros que permite este handler está el de especificar el separador, skip
fieldnames, borrar espacios en blanco (trimming), el encapsulador de cadenas de texto, etc…
curl http://[solr_host]:[solr_port]/
solr/update/csv?commit=true&separator=%09&escape=&stream.file=/tmp/myfile.text'
1. Indexación (VI): Ingestion](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-41-2048.jpg)

![➢ Ingestion de Rich Documents – Apache Tika
Particularidades de ExtractingRequestHandler :
Es possible para añadir otros campos no indexados usando Tika en los documentos enriquecidos,
para ello usamos el parámetro literal
- &literal.id=12345
- &literal.category=sports
Un ejemplo de orden para indexer un fichero html:
curl 'http://[solr_host]:[solr_port]/solr/update/extract?literal.id=doc1&commit=true' -F
myfile=@tutorial.html
Como ocurre con los ficheros CSV se puede hacer “Streaming” del fichero que se encuentre en el
sistema de archivos :
Curl 'http://[solr_host]:[solr_port]/
solr/update/extract?stream.file=/path/news.doc&stream.contentType=application/msword&literal.id=12345’
Incluso permitiría hacer con ficheros remotos siempre que se encuentren accesibles:
curl 'http://[solr_host]:[solr_port]/
solr/update/extract?literal.id=123&stream.url=http://www.solr.com/content/articulo.pdf -H
'Content-type:application/pdf’
1. Indexación (VIII): Ingestion](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-43-2048.jpg)










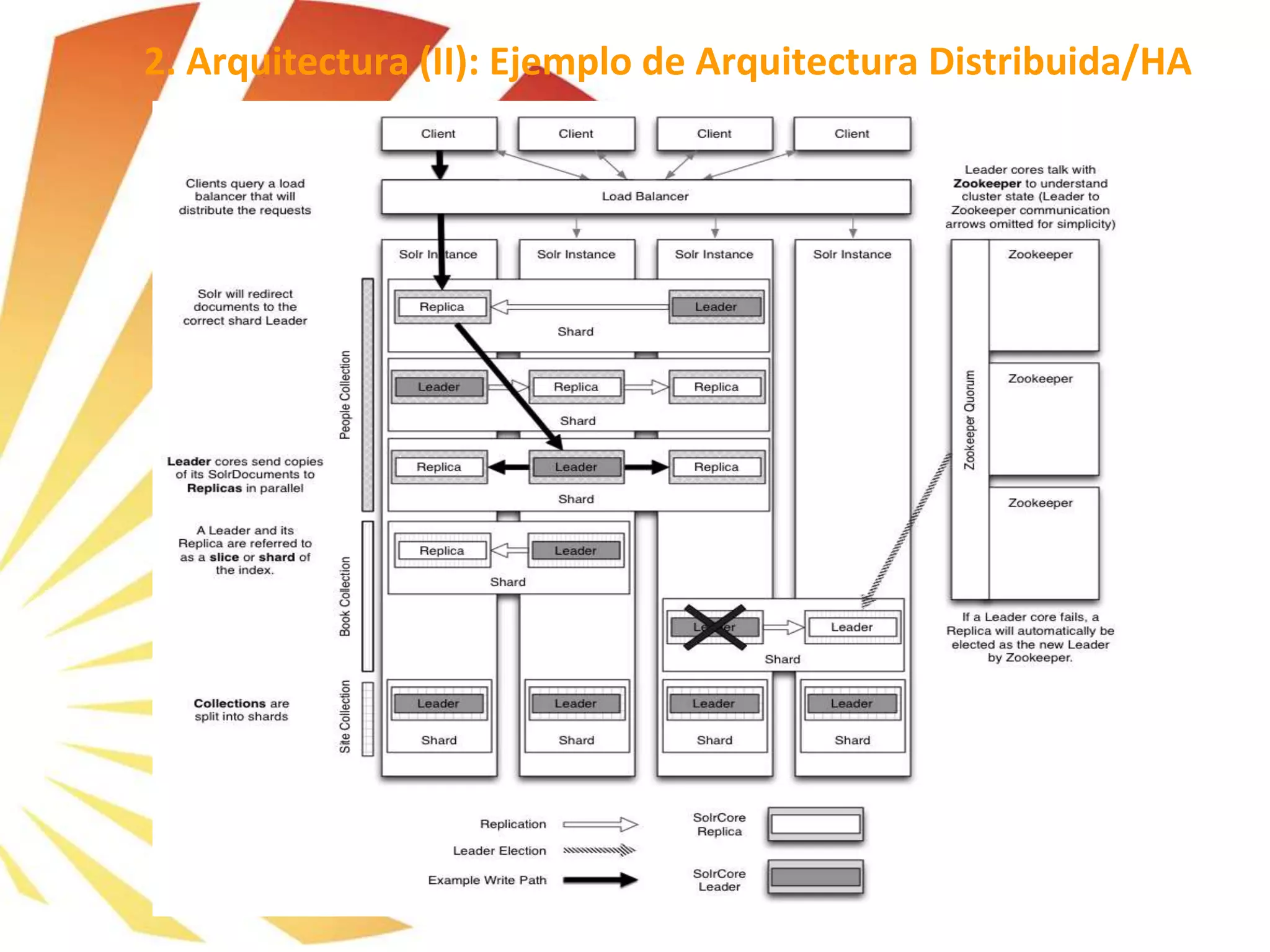
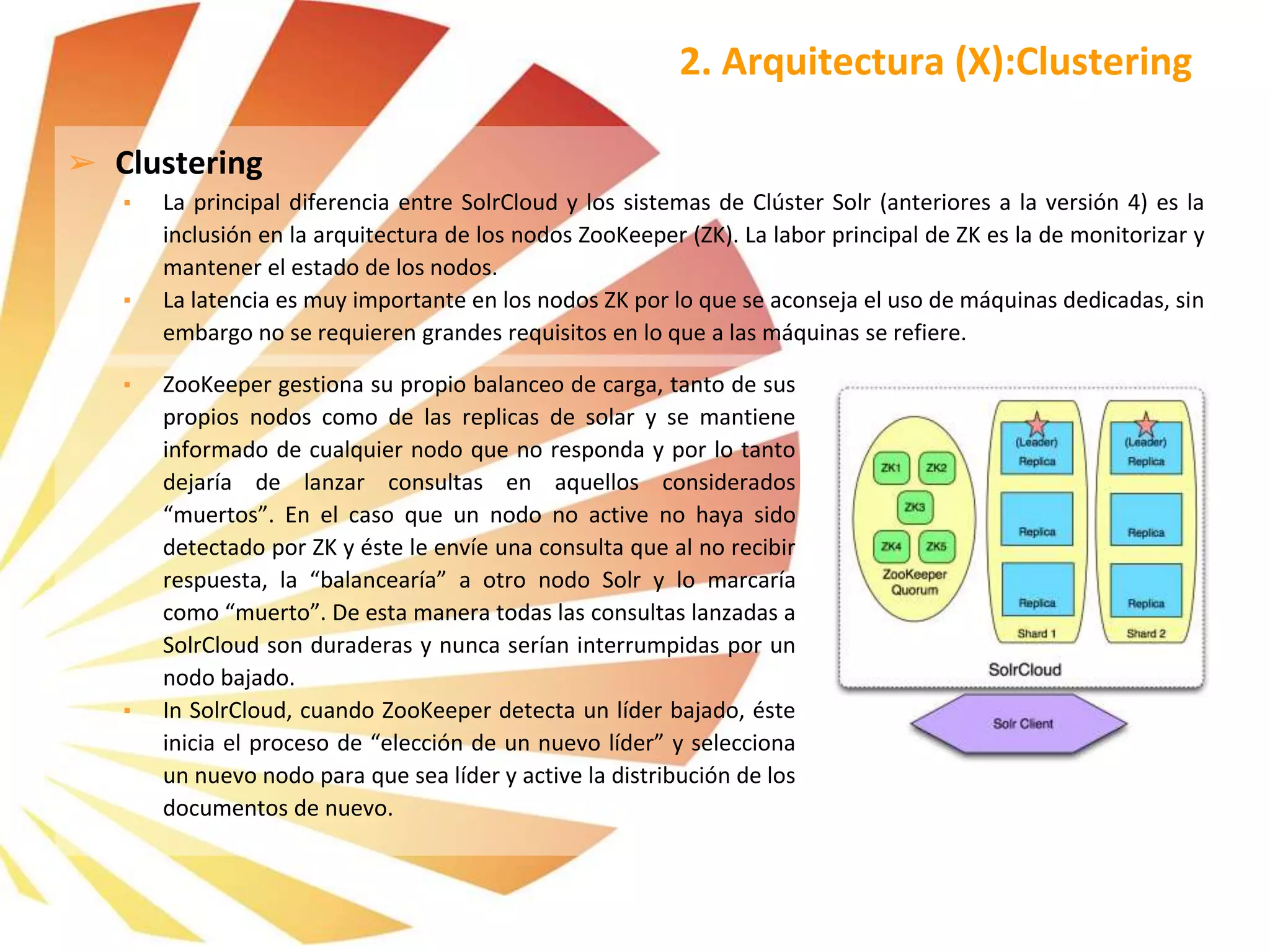
![➢ SolrCloud permite la búsqueda en uno o más shards del índice, así como en una o varias colecciones en la misma consulta.
➢ La arquitectura distribuida de SolrCloud nos permite imaginar una situación en la que tenemos un cluster donde se han
realizado varios shards del índice con sus respectivas replicas. En ese tipo de escenarios, los datos son distribuidos
automáticamente entre todos los shards y posteriormente replicados en sus respectivas réplicas.
➢ El sharding es automático y controlador por SolrCloud (con la ayuda de los ZK).
➢ Podemos realizar pruebas de funcionamiento del Sharding con comandos HTTP.
1. http://[solr_host]:[port_host]/solr/collection1_shard1_0_replica1/select?q=*%3A*&rows=0&distrib=false
Obtendríamos un resultado:
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
</lst>
<result name="response" numFound="2" start="0"/>
</response>
2. http://[solr_host]:[port_host]/solr/collection1_shard1_1_replica1/select?q=*%3A*&rows=0&distrib=false
Obtendríamos un resultado:
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
</lst>
<result name="response" numFound=“1" start="0"/>
</response>
3. http://[solr_host]:[port_host]/solr/collection1_shard1_1_replica1/select?q=*%3A*&rows=0&distrib=true
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">12</int>
</lst>
<result name="response" numFound="3" start="0" maxScore="1.0"/>
</response>
Indexación (XXII): Indexación Distribuida](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-56-2048.jpg)
![➢ Es posible detener la distribución automática de documentos aunque exista una configuración distribuida
configurada con varios Sharding. Por requisitos del proyecto es posible querer tener controlada esta
distribución para poder posteriormente realizar la búsqueda sobre la parte del índice que quisiéramos, de
esta manera disminuiríamos los tiempos tanto de indexación como de búsqueda.
➢ Para ello únicamente lo tenemos que especificar en la configuración de Solr (archivo solrconfig.xml) de la
siguiente forma:
<updateRequestProcessorChain>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
<processor class="solr.NoOpDistributingUpdateProcessorFactory" />
</updateRequestProcessorChain>
➢ Posteriormente podríamos realizar las actualizaciones en el shard elegido simplemente indicándoselo al
comando /update (del UpdateHandler)
http://[solr_host]:[port_host]/solr/shard1/update -H "Content-Type: text/xml" --data-binary @midoc.xml
Indexación (XXIII): Indexación Distribuida](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-57-2048.jpg)


![➢ Wildcards: Solr no permite wildcards iniciales
word*: * sustituye a cualquier número de caracteres.
w?rd: ? sustituye a un único carácter.
w?*d: Pueden componerse ambos comodines.
➢ Operadores Lógicos
AND: word1 AND word2 = word1 && word2 = +word1 +word2
OR: word1 OR word2 = word1 || word2 = word1 word2
NOT: word1 NOT word2 = word1 -word2
➢ Rangos: Se expresan como “campo:[A TO B]”
➢ Boosting: Se pueden ordenar resultados dando más importancia a ciertos campos
nombre:jose^2 AND alias:pepe^0.7
➢ Fuzzy: Busca términos similares basándose en número de inserciones, borrados o intercambios de
caracteres. Puede definirse el grado de proximidad.
nombre: sony~0.9 -> Devuelve resultados con nombre “sony”
nombre: sony~0.4 -> Devuelve resultados con nombre “coby”
Búsqueda (II): Parámetros y ejemplos de búsquedas](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-60-2048.jpg)


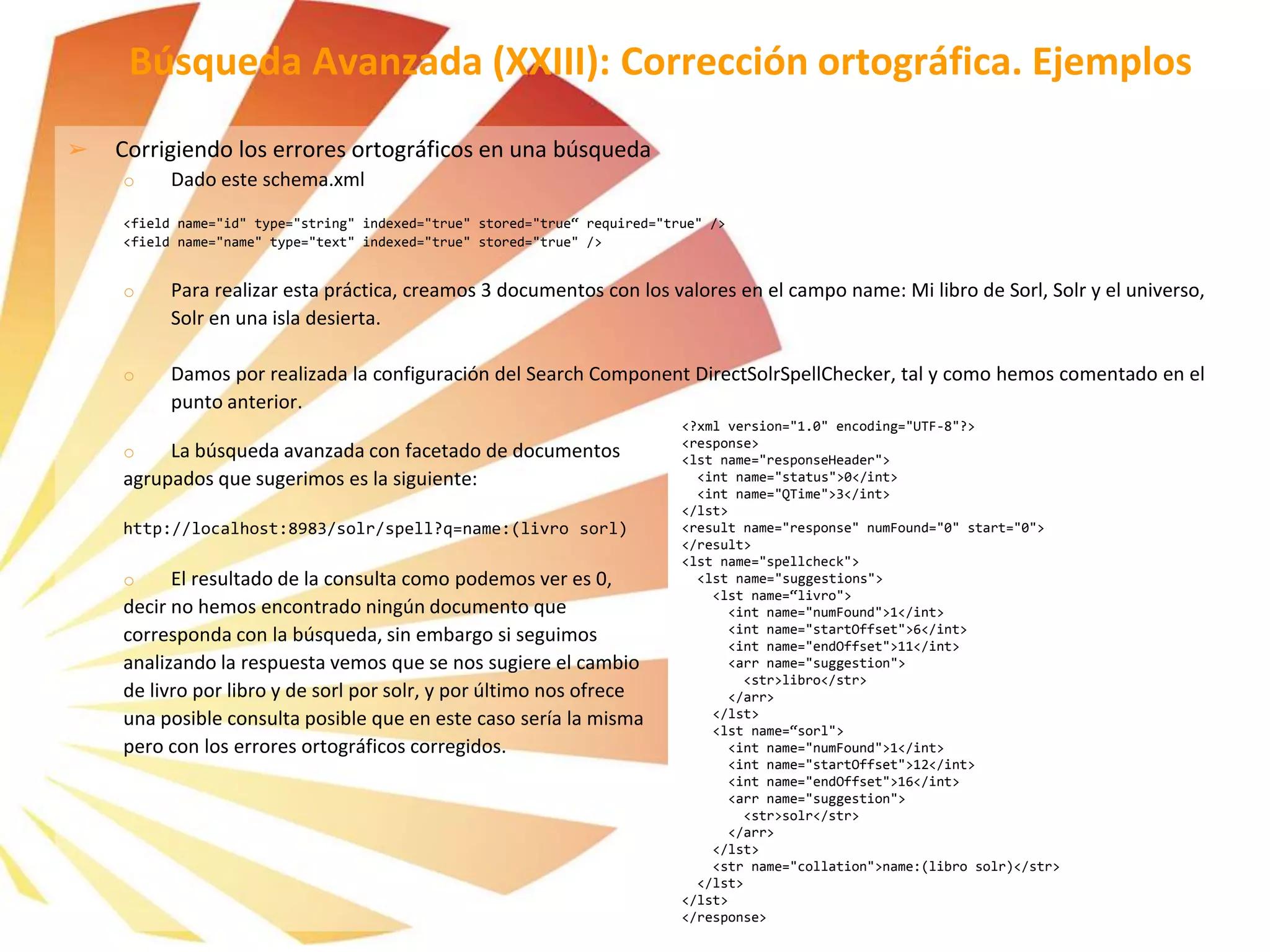
![➢ Recuperar el número de documentos con el mismo valor en un campo:
Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“ciudad" type="string" indexed="true" stored="true" />
Dado el caso en el que tuviéramos indexados tres documentos, dos documentos con valor “Barcelona” en el campo
ciudad, y un tercero con valor “Madrid” en ese mismo campo.
Si realizamos la siguiente búsqueda facetada:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&facet.field=ciudad
A la respuesta de resultados xml habitual, se le añade al final lo relacionado a la búsqueda facetada:
…
<lst name="facet_counts“>
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name=“ciudad">
<int name=“Barcelona">2</int>
<int name=“Madrid">1</int>
</lst>
</lst>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>
…
Búsqueda Avanzada (II): Facets. Ejemplos](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-63-2048.jpg)
![➢ Recuperar el número de documentos que se encuentra entre el mismo rango de valores.
o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“precio" type="float" indexed="true" stored="true" />
o Dado el caso en el que tuviéramos indexados cuatro documentos, con el campo precio de cada uno los valores: 99.90,
290, 210, 50
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&rows=0&facet=true&facet.range=precio&facet.range.start=0&facet
.range.end=400&facet.range.gap=100
o A la respuesta de resultados xml habitual, se le añade al final lo relacionado a la búsqueda facetada:
…
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
<lst name="facet_ranges">
<lst name="price">
<lst name="counts">
<int name="0.0">2</int>
<int name="100.0">0</int>
<int name="200.0">2</int>
<int name="300.0">0</int>
</lst>
<float name="gap">100.0</float>
<float name="start">0.0</float>
<float name="end">400.0</float>
</lst>
</lst>
</lst>
…
Búsqueda Avanzada (III): Facets. Ejemplos](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-64-2048.jpg)
![➢ Recuperar el número de documentos que coinciden con una query y una subquery.
o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“precio" type="float" indexed="true" stored="true" />
o Dado el caso en el que tuviéramos indexados cuatro documentos, con el campo precio de cada uno los valores: 70, 101,
201, 99.90
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&facet.query=precio:[10 TO
80]&facet.query=precio:[90 TO 300]
o A la respuesta de resultados xml habitual, se le añade al final lo relacionado a la búsqueda facetada:
…
<lst name="facet_counts">
<lst name="facet_queries">
<int name="precio:[10 TO 80]">1</int>
<int name="precio:[90 TO 300]">3</int>
</lst>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
</lst>
…
Búsqueda Avanzada (IV): Facets. Ejemplos](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-65-2048.jpg)
![➢ Eliminando filtros de los resultados de la búsqueda facetada.
o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“ciudad" type="string" indexed="true" stored="true" />
<field name=“provincia" type="string" indexed="true" stored="true />
o Dado el caso en el que tuviéramos indexados cuatro documentos, con la dupla de ciudad-provincia:
[Barcelona,Barcelona], [Oviedo,Asturias], [Barcelona,Barcelona], [Barcelona,Barcelona]
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&fq={!tag=provinciaTag}ciudad:Barcelona&facet.field=
{!ex=provinciaTag}ciudad&facet.field={!ex=provinciaTag}provincia
o En este caso la respuesta solo mostrará los
resultados de todas aquellas que cumplan el filtro
aplicado en fq, además almacenamos ese
filtro {!tag=provinciaTag} para que el resultado de los
contadores de facet no tengan en cuenta el
filtro {!ex=provinciaTag} de los resultados y muestren
el contador de registros que coinciden con el
facet.field sin aplicar el filtro, es decir que tenga en
cuenta TODOS los documentos.
Búsqueda Avanzada (V): Facets. Ejemplos
<result name="response" numFound="3"
start="0">
<doc>
<str name="id">1</str>
<str name="name">Nombre 1</str>
<str name=“ciudad">Barcelona</str>
<str name=“provincia">Barcelona</str>
</doc>
<doc>
<str name="id">3</str>
<str name="name">Nombre 3</str>
<str name="ciudad">Barcelona</str>
<str name="provincia">Barcelona</str>
</doc>
<doc>
<str name="id">4</str>
<str name="name">Nombre 4</str>
<str name="ciudad">Barcelona</str>
<str name="provincia">Barcelona</str>
</doc>
</result>
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name=“ciudad">
<int name=“Barcelona">3</int>
<int name=“Oviedo">1</int>
</lst>
<lst name=“provincia">
<int name="Barcelona">3</int>
<int name=“Asturias">1</int>
</lst>
</lst>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-66-2048.jpg)
![➢ Recuperar los resultados de la búsqueda facetada en orden alfabético.
o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“ciudad" type="string" indexed="true" stored="true" />
o Digamos que tenemos indexados 4 documentos, el campo que nos interesa para la ordenación alfabética es el de
ciudad, los valores de ese campo para cada documento son: New York, Washington, Washington y San Francisco.
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&facet.field=ciudad&facet.sort=index
o En este caso la respuesta muestra los datos sin
ordenar en cambio en relación a los datos de la
búsqueda facetada, los resultados están ordenados
alfabéticamente por el campo ciudad según lo
definido en la consulta para la búsqueda facetada.
Búsqueda Avanzada (VI): Facets. Ejemplos
<result name="response"
numFound="4" start="0">
<doc>
<str name="city">New York</str>
<str name="id">1</str>
<str name="name">House 1</str>
</doc>
<doc>
<str name="city">Washington</str>
<str name="id">2</str>
<str name="name">House 2</str>
</doc>
<doc>
<str name="city">Washington</str>
<str name="id">3</str>
<str name="name">House 3</str>
</doc>
<doc>
<str name="city">San
Francisco</str>
<str name="id">4</str>
<str name="name">House 4</str>
</doc>
</result>
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name="city">
<int name="New York">1</int>
<int name="San Francisco">1</int>
<int name="Washington">2</int>
</lst>
</lst>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-67-2048.jpg)
![➢ Implementado “autosuggest” usando facetas
o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true"required="true" />
<field name="titulo" type="text" indexed="true" stored="true" />
<field name="titulo_autocomplete" type="lowercase" indexed="true“ stored="true">
<copyField source=" titulo " dest="titulo_autocomplete" />
<fieldType name="lowercase" class="solr.TextField">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
o Tenemos en este caso indexados 4 documentos, con valores del campo título: “Lucene la base de Solr”, “Yo, yo mismo
y Solr”, “Solr me gusta”, “Solr es el Messi de los buscadores”.
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&rows=0&facet=true&facet.field=title_autocomplete&facet.prefix=
so
o En este ejemplo no queremos que nos devuelva nada de la búsqueda y es por eso que indicamos “rows=0”, pero sin
embargo deseamos los datos que nos ofrece el “Faceting” el resultado sería:
<result name="response" numFound="4" start="0"/>
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name="title_autocomplete">
<int name="solr me gusta">1</int>
<int name=“solr es el Messi de los buscadores">1</int>
</lst>
</lst>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>
Búsqueda Avanzada (VII): Facets. Ejemplos](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-68-2048.jpg)

![➢ Ordenar los resultados por el valor de una función.
o Dado este schema.xml (El mismo que en el ejemplo anterior)
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="geo" type="location" indexed="true" stored="true" />
<dynamicField name="*_coordinate" type="tdouble" indexed="true“ stored="false" />
<fieldType name="location" class="solr.LatLonType“ subFieldSuffix="_coordinate"/>
o Disponemos de 3 documentos indexados cuyo campo geo (almacenas coordenadas de geo localización), tiene un
campo de tipo location que está definido con la clase del tipo solr.LatLonType que representa una Latitud/Longitud
como un punto bi-dimensional. El campo geo de los tres documentos tienen los valores (12.2,12.2), (11.1,11.1),
(10.1,10.1)
o La búsqueda avanzada que usaremos será la siguiente
http://[solr_host]:[solr_port]/solr/select?q=*:*&pt=13,13&sort=geodist(geo,13,13)+asc
Es decir el usuario quiere realizer una búsqueda y ordernar los resultados de manera ascendente ren relación a su posición
(13,13)
o La campo dinámico “*_coordinate” es necesario para que el
tipo de campo “location” funcione y pueda ser asignado al campo
geo. Usamos una función que ya se encuentra disponible en Solr
como es “geodist” que calcula la distancia desde un punto,
finalmente como en cualquier ordenación elegimos cómo queremos
hacerla, en nuestro caso “asc” para que devuelva los resultados
ordenados del más cercano al más lejano.
Búsqueda Avanzada (IX): Ordenaciones. Ejemplos
<result name="response" numFound="3" start="0">
<doc>
<str name="id">3</str>
<str name="name">Company three</str>
<str name="geo">12.2,12.2</str>
</doc>
<doc>
<str name="id">2</str>
<str name="name">Company two</str>
<str name="geo">11.1,11.1</str>
</doc>
<doc>
<str name="id">1</str>
<str name="name">Company one</str>
<str name="geo">10.1,10.1</str>
</doc>
</result>](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-70-2048.jpg)

![➢ Usar un valores de un campo para agrupar los resultados.
o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="category" type="string" indexed="true" stored="true“ />
<field name="price" type=“tfloat" indexed="true" stored="true" />
o En esta ocasión tenemos 3 documentos 2 con valor “mechanics” en el campo category, y uno más con el valor “it” en
ese mismo campo.
o La búsqueda avanzada para agrupar documentos por los valores de un campo es la siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&group=true&group.field=category
o El resultado de respuesta que recibimos está agrupada, y recoge el
total de documentos que hacen “matching” con la búsqueda, pero
recuperamos un documento por grupo. Se podrían especificar en la
búsqueda múltiples parámetros group.field con diferentes campos para
conseguir agrupaciones más complejas.
Si quisiéramos recuperar los primeros diez documentos de cada grupo en
lugar de solo el primero, usaríamos el parámetro group.limit para indicar cuántos documentos queremos devolver de cada
grupo. Para devolver 10 resultados la query nos quedaría así
http://[solr_host]:[solr_port]/solr/select?q=*:*&group=true
&group.field=category&group.limit=10
Búsqueda Avanzada (XI): Agrupaciones. Ejemplos
<arr name="groups">
<lst>
<str name="groupValue">it</str>
<result name="doclist" numFound="2" start="0">
<doc>
<str name="id">1</str>
<str name="name">Solr book</str>
<str name="category">it</str>
<float name="price">39.99</float>
</doc>
</result>
</lst>
<lst>
<str name="groupValue">mechanics</str>
<result name="doclist" numFound="1" start="0">
<doc>
<str name="id">2</str>
<str name="name">Mechanics book</str>
<str name="category">mechanics</str>
<float name="price">19.99</float>
</doc>
</result>
</lst>
</arr>](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-72-2048.jpg)
![➢ Usar queries para agrupar los resultados.
o Dado este schema.xml (El mismo que en el ejemplo anterior)
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="category" type="string" indexed="true" stored="true“ />
<field name="price" type=“tfloat" indexed="true" stored="true" />
o Ahora nos fijamos en el campo “price”, los tres documentos indexados tienen un valor en ese campo de: 39.99, 19.99 y
49.99 respectivamente.
o La búsqueda avanzada que usaremos será:
http://[solr_host]:[solr_port]/solr/select?q=*:*&group=true&group.query=price:[20.0+TO+50.0]
&group.query=price:[1.0+TO+19.99]
o La respuesta es muy parecida a la que obtuvimos en el
ejemplo anterior. Ahora la agrupación se ha realizado basándose
en un rango de valores almacenados en uno de los campos, en
este caso el campo “Price”. Si nos fijamos bien en el resultado
el nombre de los grupos es diferente y refleja la query realizada
es decir “Price:[X TO Y]”. También come el ejemplo anterior
devolvemos el primer valor de cada grupo.
Búsqueda Avanzada (XII): Agrupaciones. Ejemplos
<lst name="grouped">
<lst name="price:[20.0 TO 50.0]">
<int name="matches">3</int>
<result name="doclist" numFound="2" start="0">
<doc>
<str name="id">1</str>
<str name="name">Solr book</str>
<str name="category">it</str>
<float name="price">39.99</float>
</doc>
</result>
</lst>
<lst name="price:[1.0 TO 19.99]">
<int name="matches">3</int>
<result name="doclist" numFound="1" start="0">
<doc>
<str name="id">2</str>
<str name="name">Mechanics book</str>
<str name="category">mechanics</str>
<float name="price">19.99</float>
</doc>
</result>
</lst>
</lst>](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-73-2048.jpg)

![➢ Cálculos facetados de los documentos relevantes agrupados
o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name="categoria" type="string" indexed="true" stored="true“ />
<field name="stock" type="boolean" indexed="true" stored="true" />
o Volvemos a tener 4 documentos indexados, con los valores en los campos categoría y stock siguientes: [books, true],
[books, true], [workbooks, false], [workbooks, true]
o La búsqueda avanzada con facetado de documentos agrupados que sugerimos es la siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&facet.field=stock&group=true&group.field=categoria
&group.truncate=true
o La respuesta a esta búsqueda, agrupará
por categoría los resultados y nos dará cifras de
facetado por stock, el parámetro de la búsqueda
group.truncate=true cambia el comportamiento
del facetado para que solo devuelva el resultado
más relevante de cada grupo.
Búsqueda Avanzada (XIV): Agrupaciones. Ejemplos
<str name="groupValue">books</str>
<result name="doclist" numFound="2" start="0">
<doc>
<str name="id">1</str>
<str name="name">Book 1</str>
<str name="categoria">books</str>
<bool name="stock">true</bool></doc>
</result>
</lst>
<lst>
<str name="groupValue">workbooks</str>
<result name="doclist" numFound="2“ start="0">
<doc>
<str name="id">3</str>
<str name="name">Workbook 1</str>
<str name="categoria">workbooks</str>
<bool name="stock">false</bool>
</doc>
</result>
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name="stock">
<int name="false">1</int>
<int name="true">1</int>
</lst>
</lst>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>](https://image.slidesharecdn.com/formacinapachesolr-tv3-150130071830-conversion-gate02/75/Formacion-apache-Solr-75-2048.jpg)













El documento presenta una guía detallada sobre Apache Solr, una plataforma de búsqueda empresarial open source, abordando su arquitectura, características y funcionamiento. Se explican conceptos clave como el índice invertido, la indexación distribuida y las funcionalidades de Solr y SolrCloud, incluyendo clustering y búsqueda 'near real-time'. Además, se analizan su implementación y configuración necesarias para optimizar su rendimiento en aplicaciones web.



































































