Descargar como PDF, PPTX




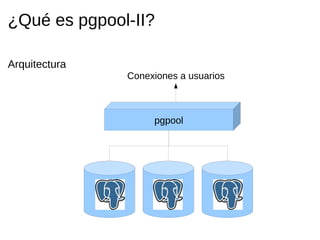
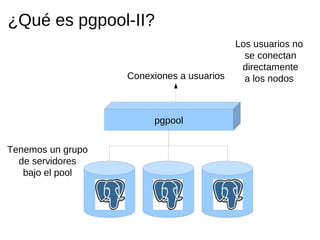
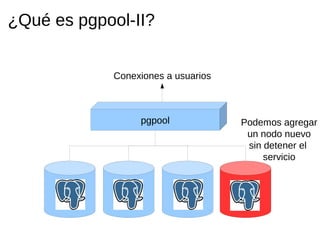
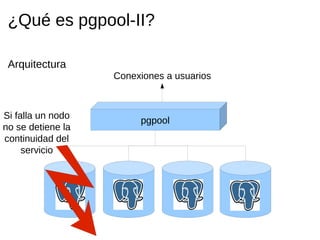
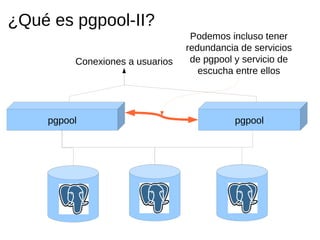
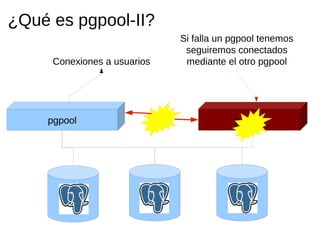
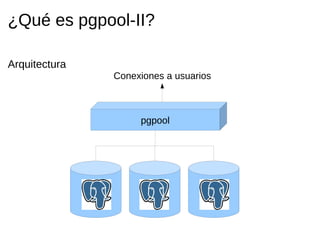






























Pgpool-II es un middleware que mejora la eficiencia de las bases de datos PostgreSQL mediante funcionalidades como agrupado de conexiones, replicación y balanceo de carga. La guía detalla la instalación, configuración y recomendaciones para su uso, incluyendo ejemplos prácticos de creación y manejo de bases de datos en un entorno cluster. Se enfatiza la importancia de seguir la documentación y utilizar prácticas de diseño adecuadas para asegurar la alta disponibilidad del servicio.
































































