Descargado 218 veces





















![{
_id : ObjectId("4e2e3f92268cdda473b628f6"),
title : “Too Big to Fail”,
when : Date(“2011-07-26”),
author : “joe”,
text : “blah”,
tags : [“business”, “news”, “north america”]
}
> db.posts.find( { tags : “news” } )
34](https://image.slidesharecdn.com/2012nosqlintro-spanish-120913133357-phpapp01/75/Introduccion-a-NoSQL-y-MongoDB-Webinar-34-2048.jpg)
![{
_id : ObjectId("4e2e3f92268cdda473b628f6"),
title : “Too Big to Fail”,
when : Date(“2011-07-26”),
author : “joe”,
text : “blah”,
tags : [“business”, “news”, “north america”],
votes : 3,
voters : [“dmerr”, “sj”, “jane” ]
}
35](https://image.slidesharecdn.com/2012nosqlintro-spanish-120913133357-phpapp01/75/Introduccion-a-NoSQL-y-MongoDB-Webinar-35-2048.jpg)
![{
_id : ObjectId("4e2e3f92268cdda473b628f6"),
title : “Too Big to Fail”,
when : Date(“2011-07-26”),
author : “joe”,
text : “blah”,
tags : [“business”, “news”, “north america”],
votes : 3,
voters : [“dmerr”, “sj”, “jane” ],
comments : [
{ by : “tim157”, text : “great story” },
{ by : “gora”, text : “i don’t think so” },
{ by : “dmerr”, text : “also check out...” }
]
}
36](https://image.slidesharecdn.com/2012nosqlintro-spanish-120913133357-phpapp01/75/Introduccion-a-NoSQL-y-MongoDB-Webinar-36-2048.jpg)
![{
_id : ObjectId("4e2e3f92268cdda473b628f6"),
title : “Too Big to Fail”,
when : Date(“2011-07-26”),
author : “joe”,
text : “blah”,
tags : [“business”, “news”, “north america”],
votes : 3,
voters : [“dmerr”, “sj”, “jane” ],
comments : [
{ by : “tim157”, text : “great story” },
{ by : “gora”, text : “i don’t think so” },
{ by : “dmerr”, text : “also check out...” }
]
}
> db.posts.find( { “comments.by” : “gora” } )
> db.posts.ensureIndex( { “comments.by” : 1 } )
37](https://image.slidesharecdn.com/2012nosqlintro-spanish-120913133357-phpapp01/75/Introduccion-a-NoSQL-y-MongoDB-Webinar-37-2048.jpg)








![MySQL MongoDB
START TRANSACTION; db.contacts.save( {
INSERT INTO contacts VALUES userName: ‚joeblow‛,
(NULL, ‘joeblow’); emailAddresses: [
INSERT INTO contact_emails VALUES ‚joe@blow.com‛,
( NULL, ‛joe@blow.com‛, ‚joseph@blow.com‛ ] } );
LAST_INSERT_ID() ),
( NULL, ‚joseph@blow.com‛,
LAST_INSERT_ID() );
COMMIT;
59](https://image.slidesharecdn.com/2012nosqlintro-spanish-120913133357-phpapp01/75/Introduccion-a-NoSQL-y-MongoDB-Webinar-59-2048.jpg)
![MySQL MongoDB
START TRANSACTION; db.contacts.save( {
INSERT INTO contacts VALUES userName: ‚joeblow‛,
(NULL, ‘joeblow’); emailAddresses: [
INSERT INTO contact_emails VALUES ‚joe@blow.com‛,
( NULL, ‛joe@blow.com‛, ‚joseph@blow.com‛ ] } );
LAST_INSERT_ID() ),
( NULL, ‚joseph@blow.com‛,
LAST_INSERT_ID() );
COMMIT;
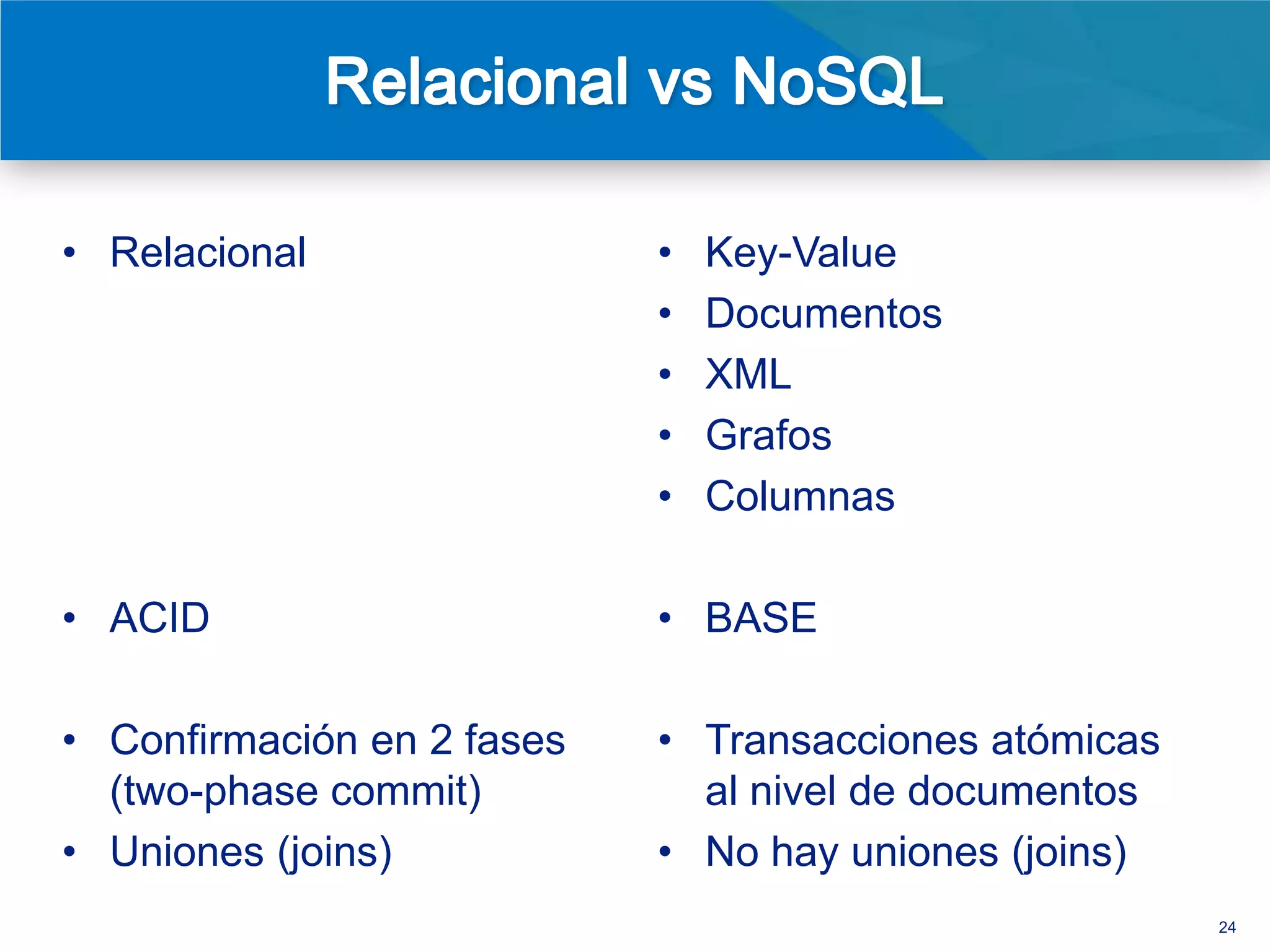
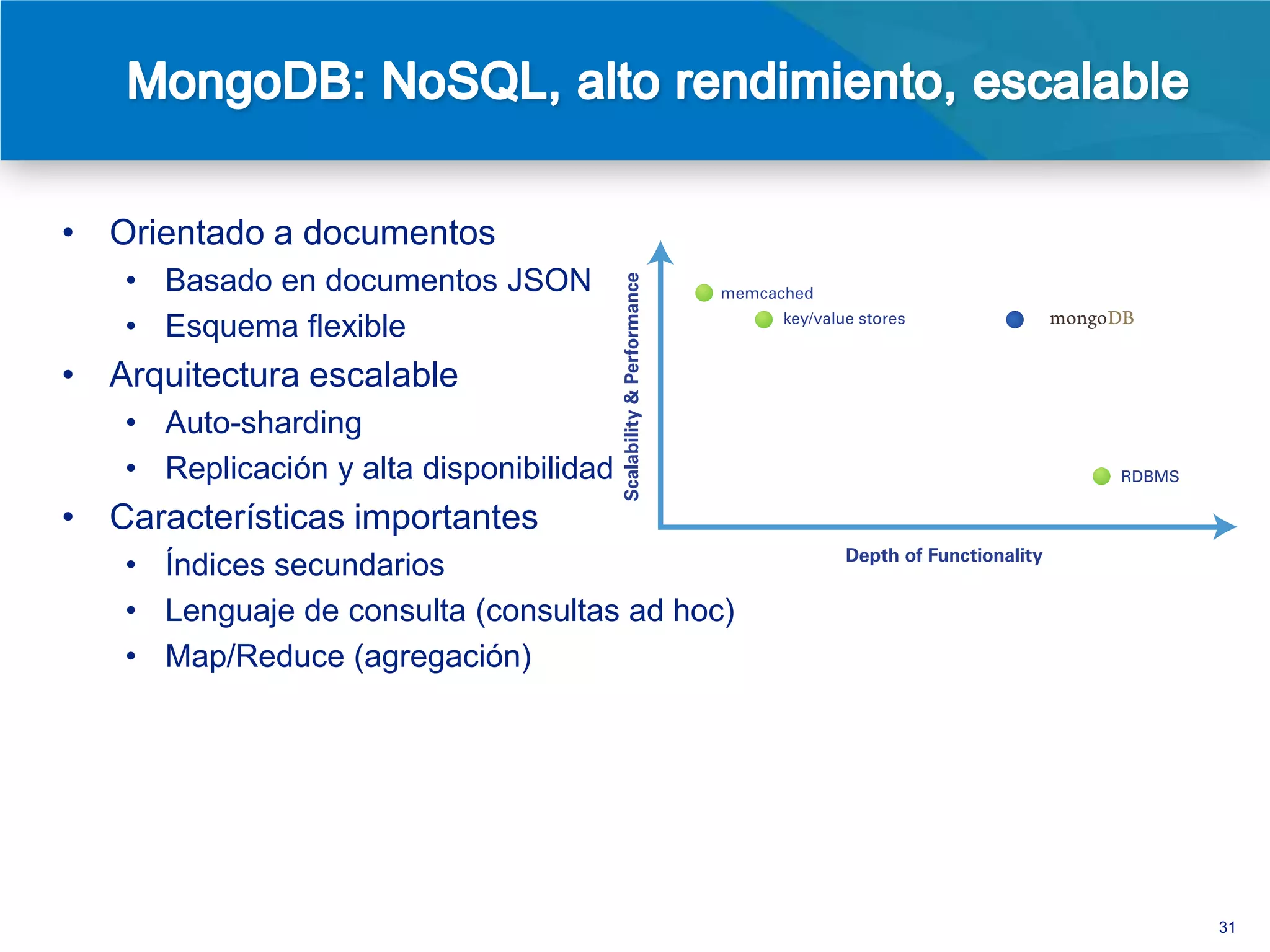
• Existen interfaces (drivers) para docenas de lenguajes de
programación
• Una relación natural entre objetos (OO) y documentos
60](https://image.slidesharecdn.com/2012nosqlintro-spanish-120913133357-phpapp01/75/Introduccion-a-NoSQL-y-MongoDB-Webinar-60-2048.jpg)


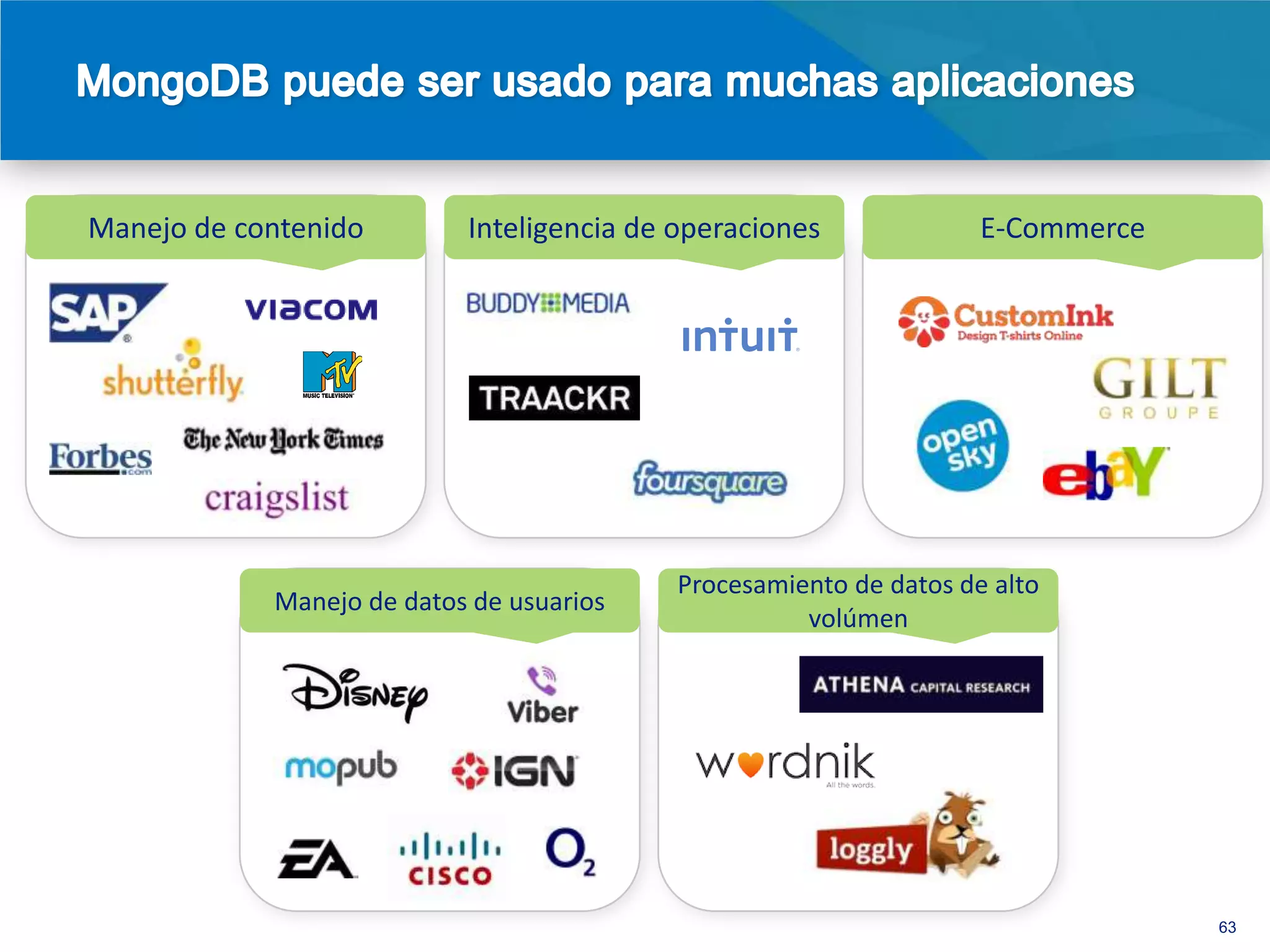

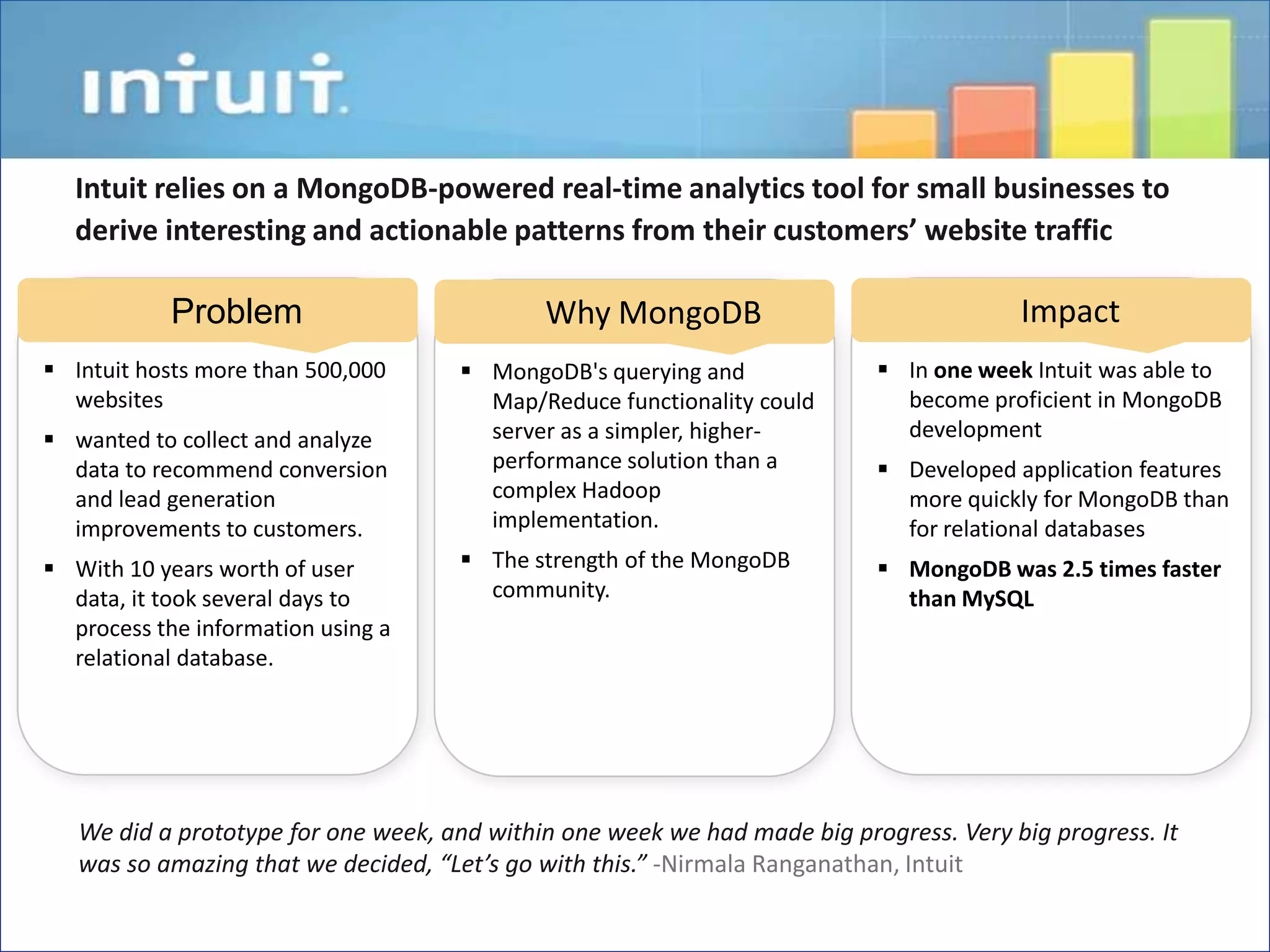



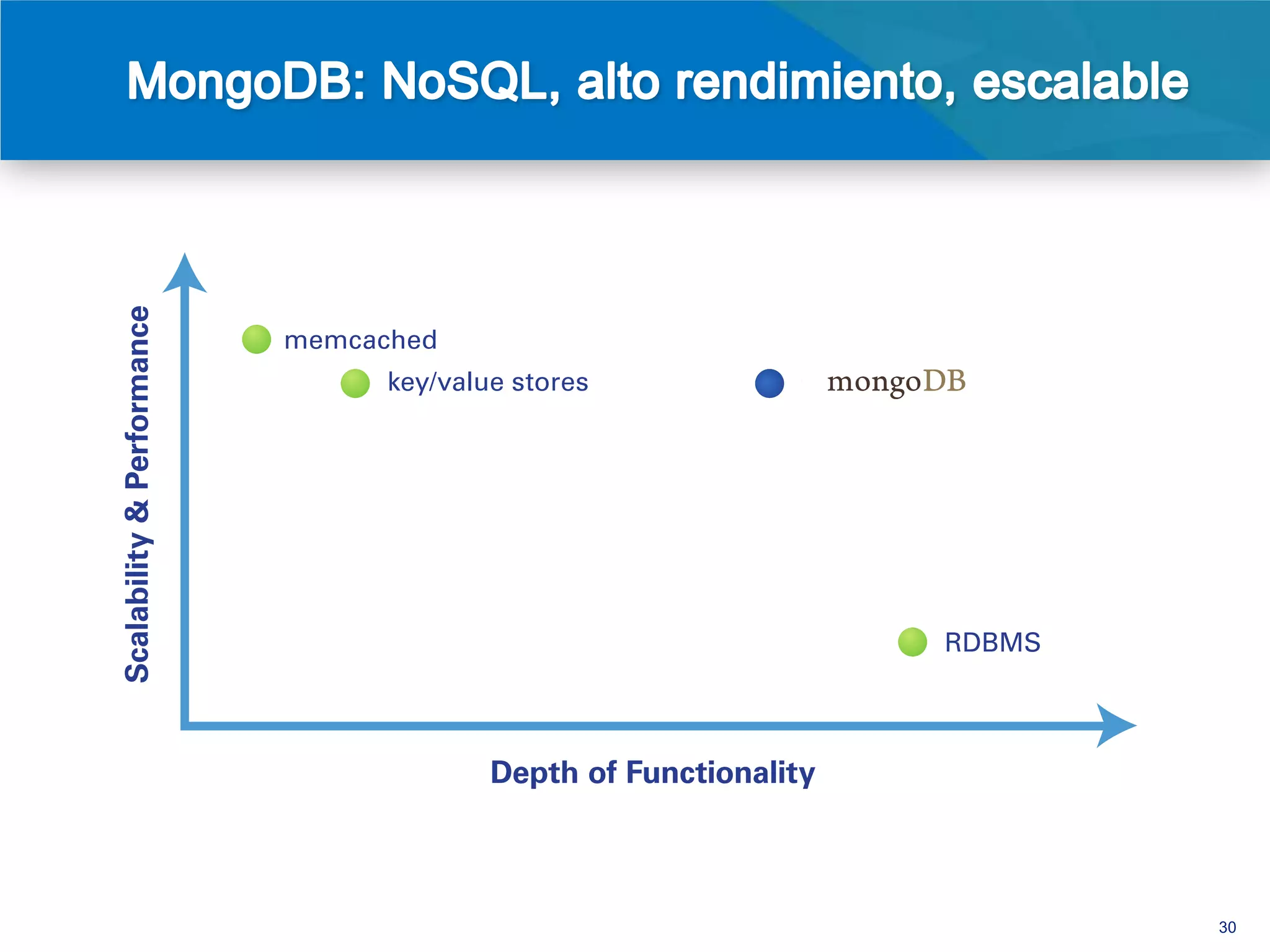
El documento discute la evolución de las bases de datos desde las relacionales hasta las NoSQL, resaltando las limitaciones de las primeras en términos de escalabilidad y flexibilidad. Se presenta MongoDB como un sistema de base de datos NoSQL orientado a documentos que ofrece ventajas como un esquema flexible, alta disponibilidad y un rendimiento mejorado en comparación con soluciones tradicionales. Además, se destacan casos de uso exitosos de MongoDB en grandes empresas, evidenciando sus beneficios en el manejo de grandes volúmenes de datos.








![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)





















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











