Descargado 48 veces





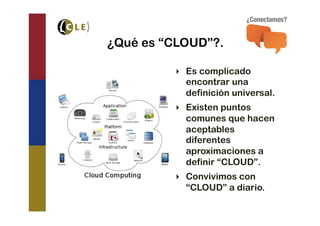


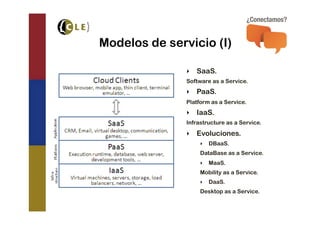
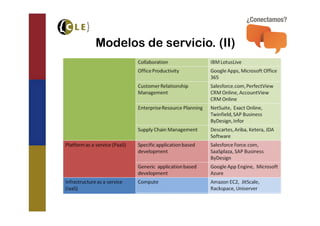
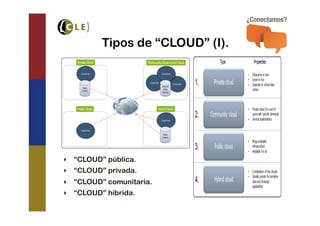









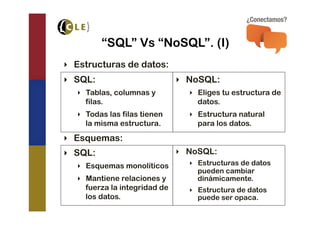







El documento explora las tecnologías de 'cloud' y 'big data', definiendo sus tipos, modelos de servicio y cómo interactúan entre sí. Se discuten las bases de datos SQL y NoSQL, incluyendo sus diferencias, ventajas y desventajas, así como la necesidad de adoptar estrategias mixtas para aprovechar ambas. También se analizan los requisitos y desafíos para implementar 'big data' en la nube de manera efectiva.















































