Descargado 473 veces































![40
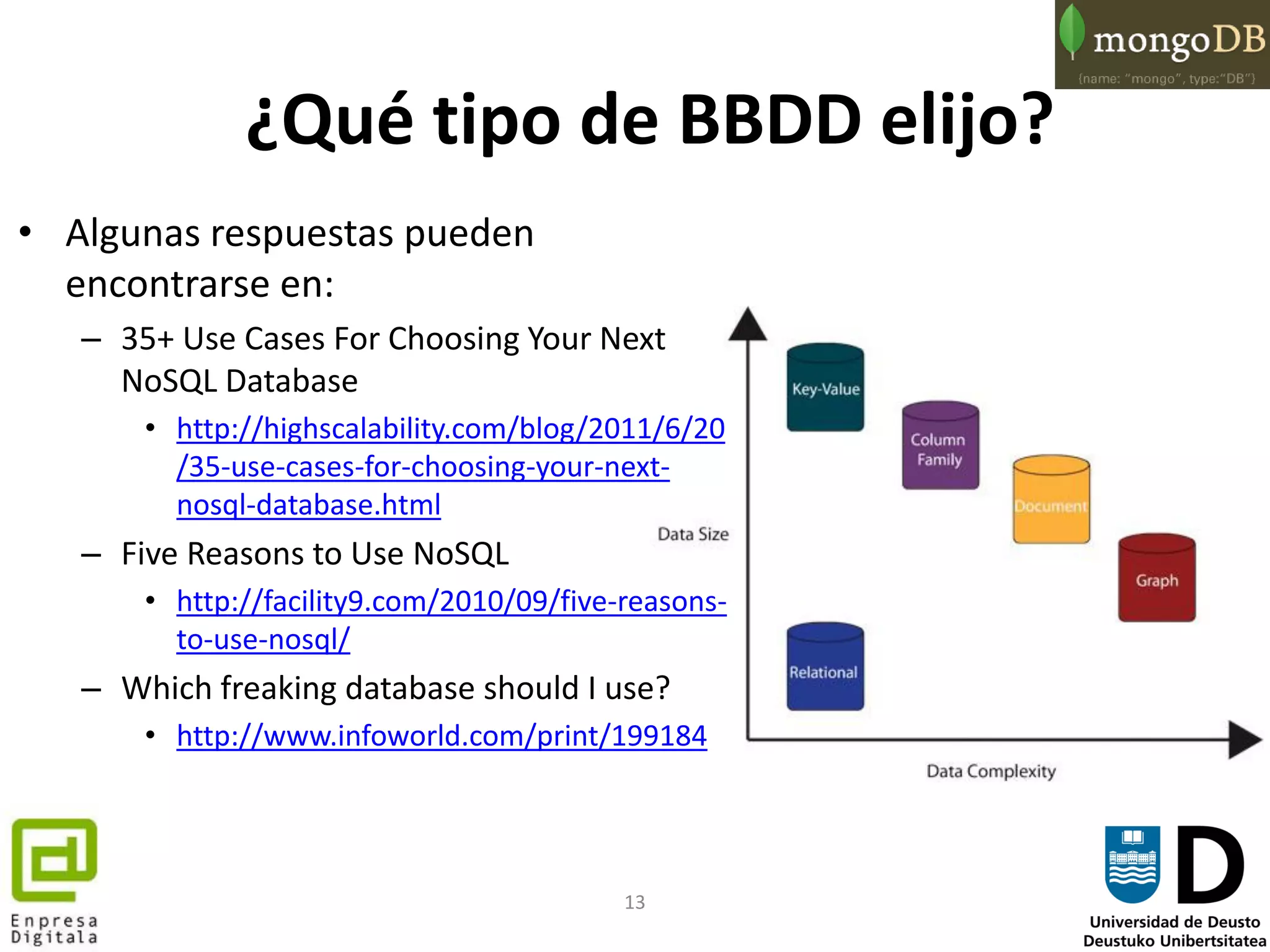
Usando MongoDB
> // Store the cursor of the DB in a variable
> var cursor = db.things.find();
> while (cursor.hasNext()) printjson(cursor.next());
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d90"), "name" : "mongo" }
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d91"), "x" : 3 }
...
> // Use functional features of JavaScript
> db.things.find().forEach(printjson);
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d90"), "name" : "mongo" }
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d91"), "x" : 3 }
...
> // cursors like an array
> var cursor = db.things.find();
> printjson(cursor[4]);
{ "_id" : ObjectId("51e50d3b70f9b7c7fdbd8d94"), "x" : 4, "j" : 3 }
>](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-40-2048.jpg)




![45
Selectores de Consulta
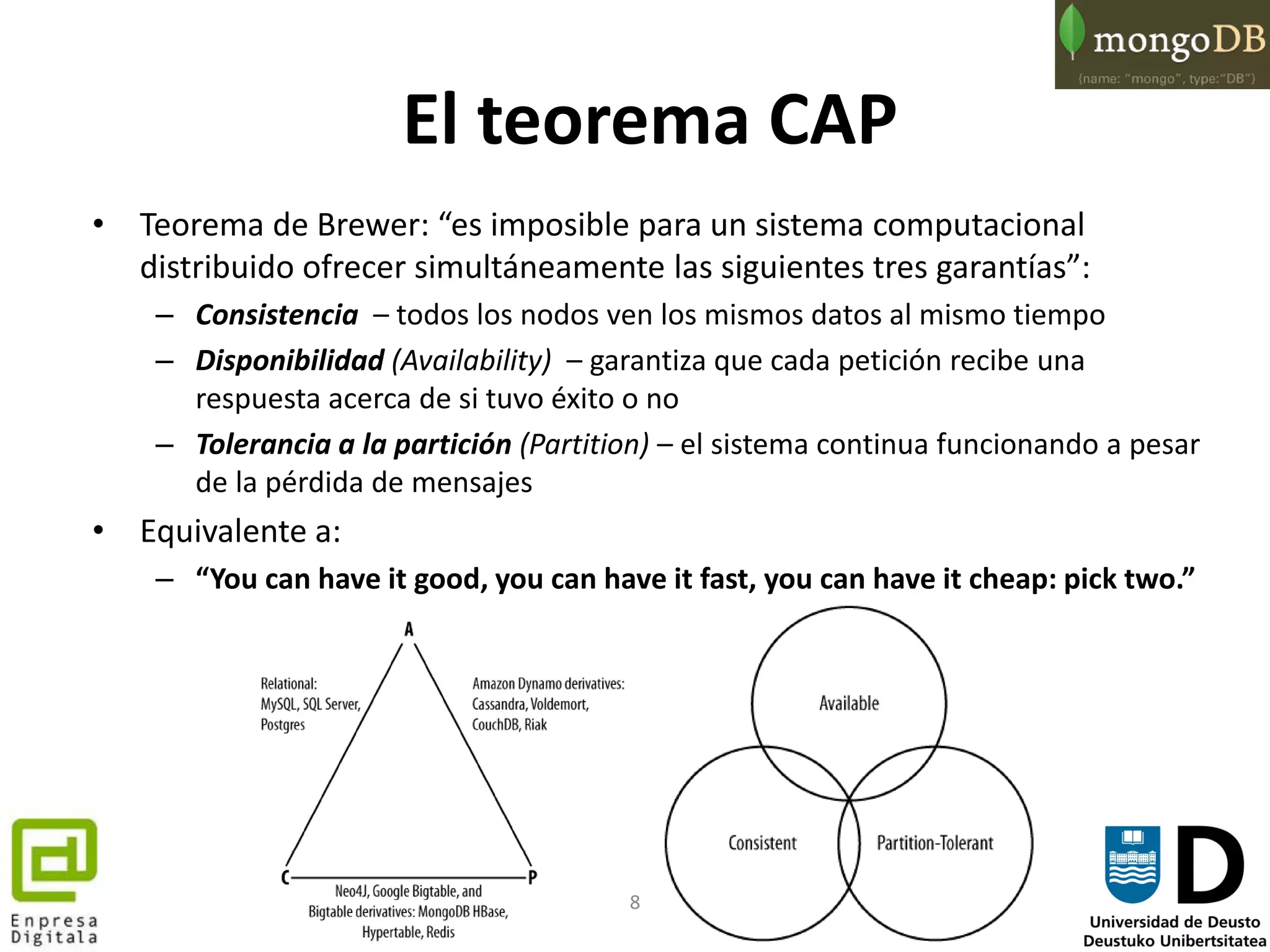
• El operador $exists se utiliza para comprobar la presencia o ausencia
de un campo:
– db.unicorns.find({vampires: {$exists: false}})
• Si queremos utilizar el operador booleano OR tenemos que hacer uso del
operador $or y asociarle un array de tuplas clave/valor sobre los que
realizar el OR:
– db.unicorns.find({gender: 'f', $or: [{loves: 'apple'},
{loves: 'orange'}, {weight: {$lt: 500}}]})
• Dado que los arrays en MongoDB son objetos de primera categoría se
puede comprobar la inclusión de un elemento dentro de un array al igual
que si compararamos con un único valor:
– {loves: 'watermelon'} devolverá un documento donde watermelon es un
valor del campo loves
• Un valor de tipo ObjectId asociado al campo _id puede seleccionarse
como:
– db.unicorns.find({_id: ObjectId("TheObjectId")})](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-45-2048.jpg)
![46
Actualizando documentos
• El comando update tiene dos argumentos: el selector where a
usar y qué campo a actualizar:
db.unicorns.update({name: 'Roooooodles'},
{weight: 590})
• Cuidado!!! Realmente con esa sentencia el documento encontrado
que tiene el nombre dado es remplazado con un nuevo documento
que mantiene el campo _id pero tiene ahora sólo el campo
adicional weight
• SOLUCIÓN cuando quieres sólo cambiar el valor de un campo o
varios campos, hay que usar el modificador $set:
db.unicorns.update({weight: 590}, {$set: {name:
'Roooooodles', dob: new Date(1979, 7, 18, 18,
44), loves: ['apple'], gender: 'm', vampires:
99}})](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-46-2048.jpg)








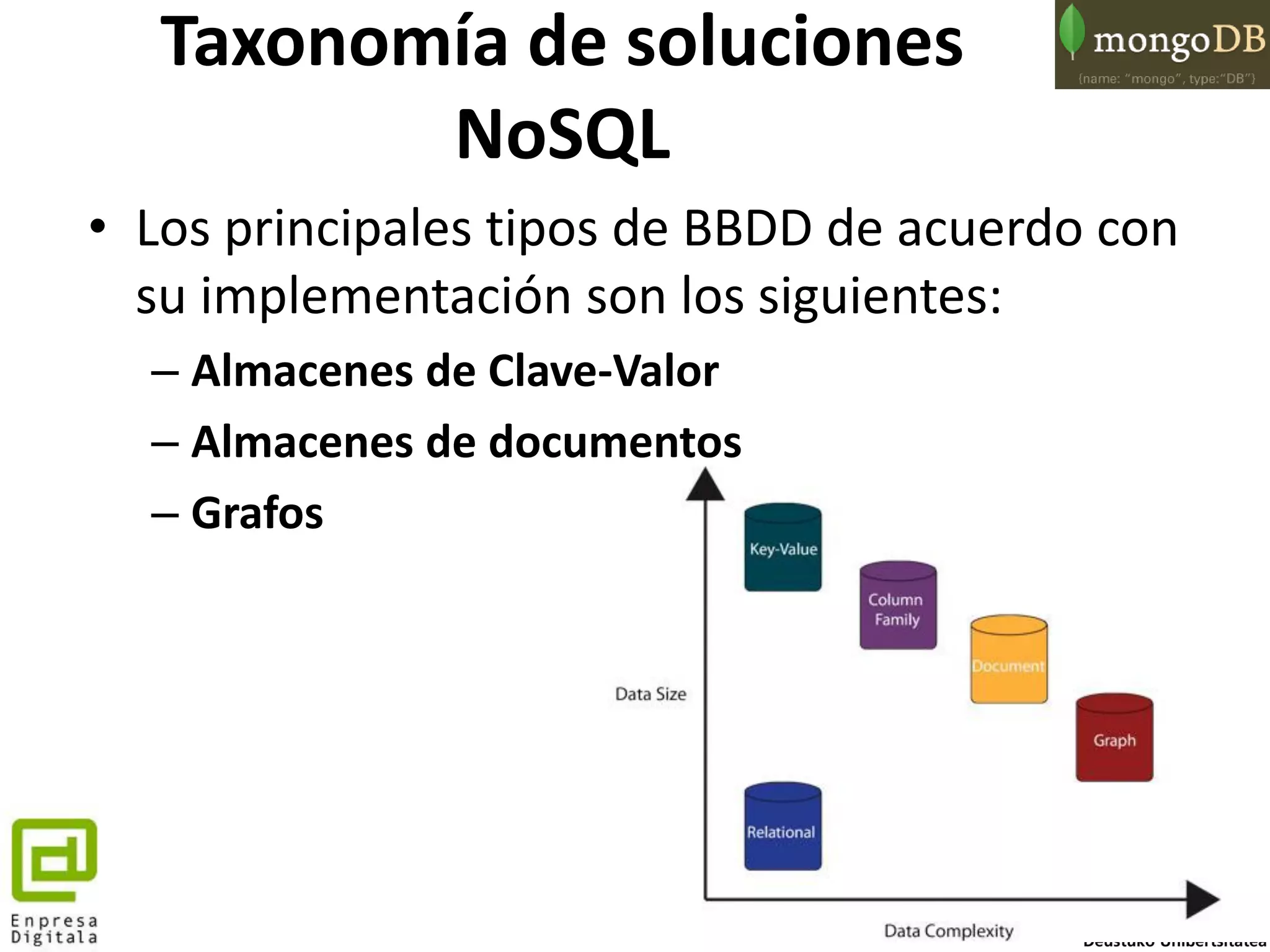
![57
• En MongoDB se usan dos técnicas para modelar relaciones many-to-one y many-to-many,
sobretodo en los casos que el “many” hace referencia a “few”
• Arrays:
db.employees.insert({_id: ObjectId("4d85c7039ab0fd70a117d733"),
name: 'Siona',
manager: [ObjectId("4d85c7039ab0fd70a117d730"),
ObjectId("4d85c7039ab0fd70a117d732")] });
db.employees.find({manager: ObjectId("4d85c7039ab0fd70a117d730")})
– De modo interesante el método find()funciona independientemente de si se aplica a un vector a un escalar
• Documentos empotrados:
db.employees.insert({_id: ObjectId("4d85c7039ab0fd70a117d734"), name:
'Ghanima',
family: {mother: 'Chani', father: 'Paul', brother:
ObjectId("4d85c7039ab0fd70a117d730")} });
db.employees.find({'family.mother': 'Chani'})
– Los documentos pueden ser consultados usando una notación separada por puntos: family.mother
• Otra alternativa es des-normalizar, replicar tus datos a través de varias colecciones
– Es una práctica que históricamente ya se ha usado en RDBMS por temas de rendimiento
– Introduce la complicación de tener que contrastar las restricciones de los datos (constraints) a nivel
de aplicación
– MongoDB también soporta DBRefs: http://docs.mongodb.org/manual/reference/database-
references/
Modelado de Datos en
MongoDB](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-57-2048.jpg)

![59
• Relaciones uno a muchos (1-N)
– Si una nave tiene mucho miembros de tripulación o una nave tiene muchos instructores
• ¿Tiene sentido empotrar la lista de toda la tripulación o de instructores dentro del documento
nave que tiene un límite de tamaño de 16 MB?
– Por tanto, en caso de relaciones 1-N suele ser a menudo conveniente enlazar
documentos entre colecciones y además hacerlo desde la colección que guarda muchos
valores a la colección que guarda sólo uno.
– PISTA. Para tomar una decisión hay que responder a la siguiente pregunta:
• ¿Estamos hablando de una relación 1-N o de 1-pocos?
– En el segundo caso un array dentro del documento podría ser una mejor opción
• Ejemplo:
db.starships.insert( { _id: 'ussenterprise1', name: 'USS
Enterprise', class: 'Galaxy', captain: { name : 'James
T. Kirk', age : 38}, instructors: [1, 2, 3]}
db.instructors.insert( { _id: 1, name : 'Tuvok',
candidates : [99, 100], starship: 'ussenterprise1'} );
Ejemplos de Relaciones de
Datos](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-59-2048.jpg)
![60
• Relaciones muchos a muchos (N-M)
– Considera la relación en la que un candidato puede tener varios instructores y viceversa
• Varios candidatos serán asignados a un instructor y un instructor será asignado a varios
candidatos para que los instruya
• En esta relación tendremos dos colecciones (candidates e instructors) y un enlace bi-
direccional, dado que cada candidato tiene una lista de instructores y por cada instructor hay
una lista de candidatos
• Si quisiéramos empotrar los candidatos dentro del documento instructor, sería necesario tener
un instructor antes de un candidato, no podrían existir uno sin el otro
• Ejemplo:
db.candidates.insert( { _id : 99, name : 'Harry Kim',
instructors : [1, 2]} );
db.instructors.insert( { _id : 1, name : 'Tuvok', candidates
: [99, 100], starship: 'ussenterprise1'} );
• Recuerda que es tu programa el que tendrá que garantizar la consistencia. Por
ejemplo, asegurando que existe un candidato cuyo _id es 100
Ejemplos de Relaciones de
Datos](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-60-2048.jpg)






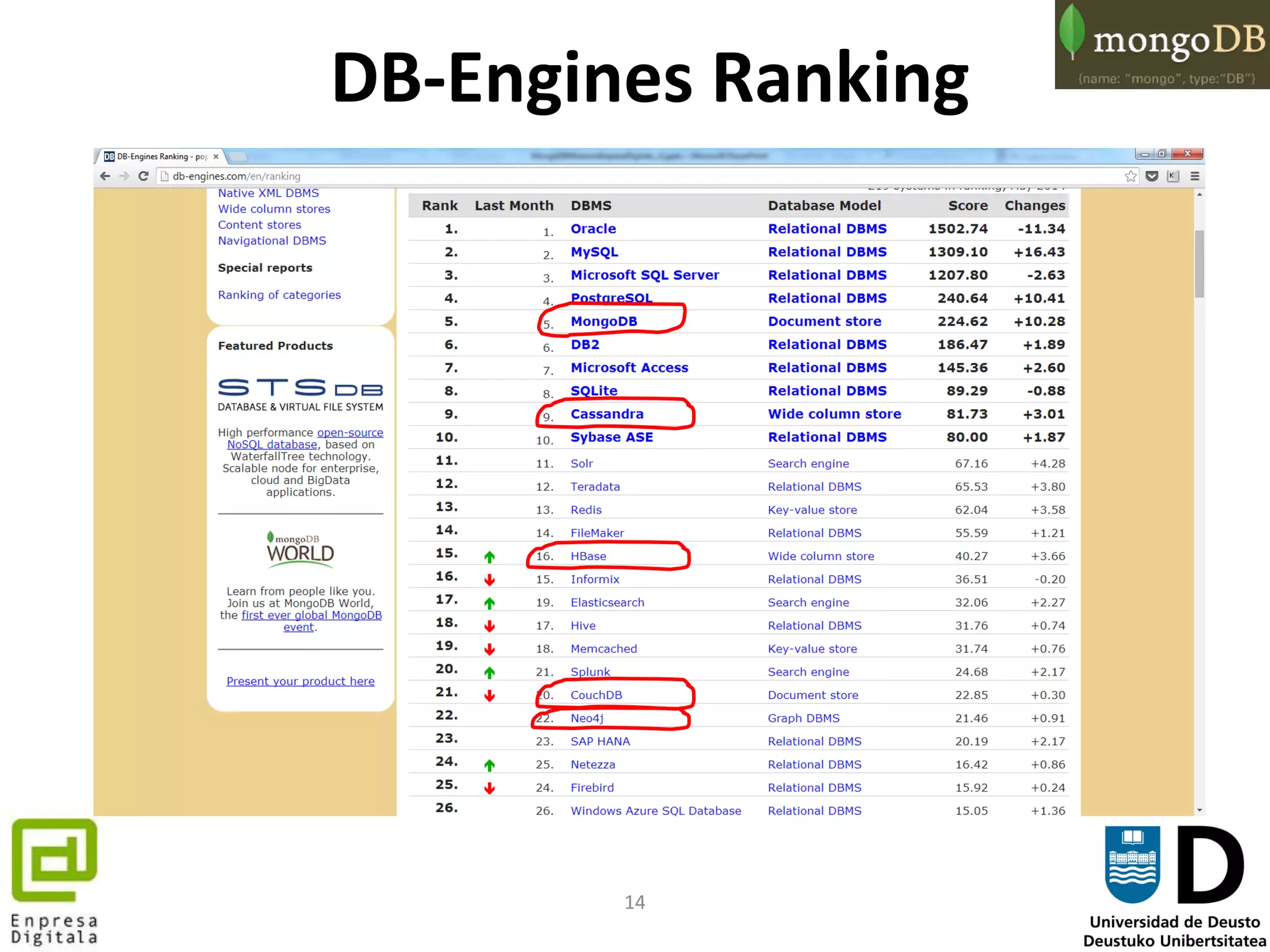
![68
Índices
• Si creamos un índice ese campo tendrá asociado un índice de tipo BtreeCursor,
optimizándose las operaciones sobre esos documentos
{
"cursor" : "BtreeCursor name_1", // los campos de consulta son indexados
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 1,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 1,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"name" : [
[
"Pilot",
"Pilot"
]
]
},
"server" : "dipinaXPS14z:27017"
}](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-68-2048.jpg)






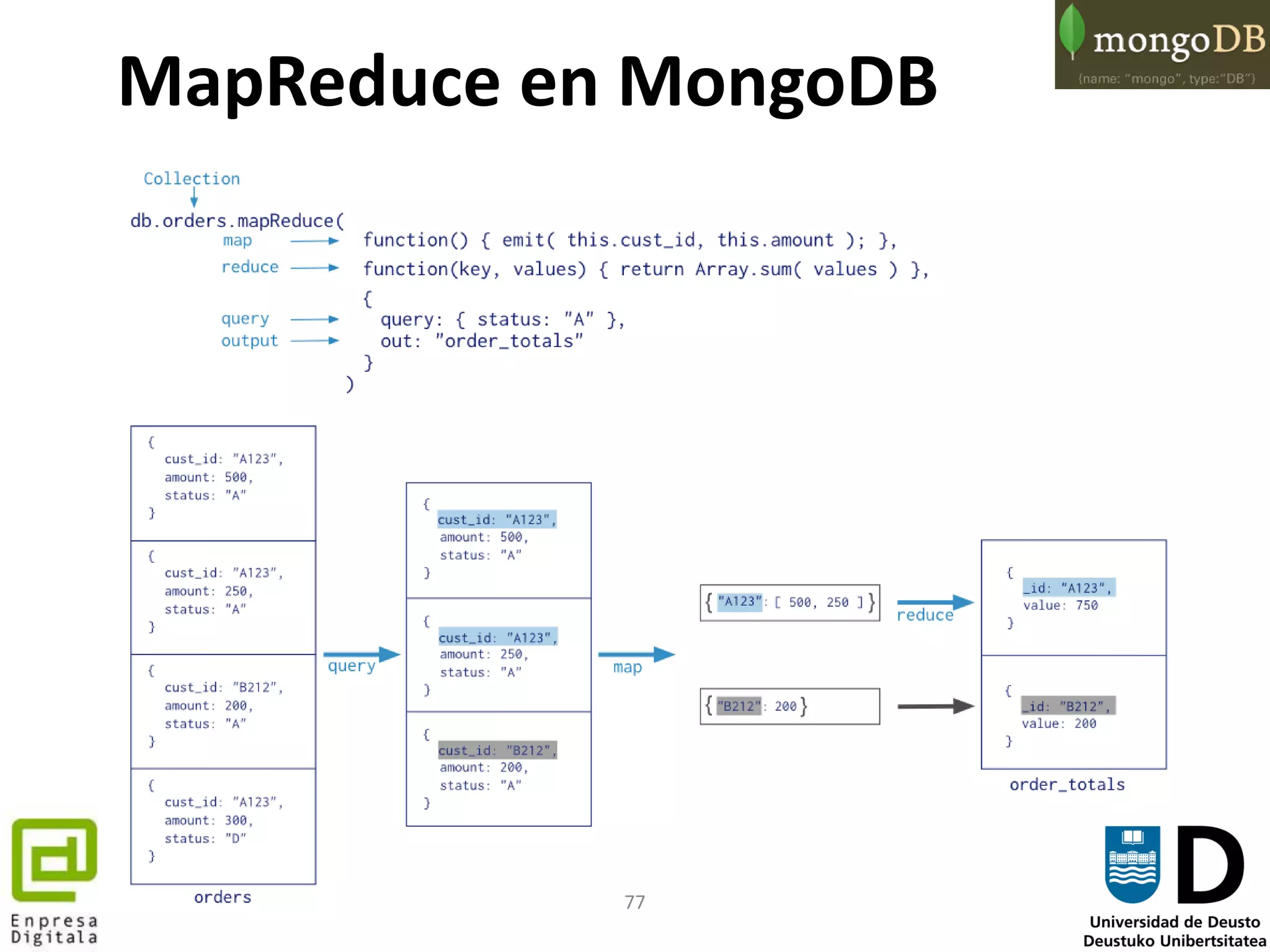
![78
• En este ejemplo vamos a contar el número de hits por día en una portal web
– Donde cada hit está representado con un log como:
resource date
index Jan 20 2010 4:30
index Jan 20 2010 5:30
...
– Generando tras el procesamiento la siguiente salida:
resource year month day count
index 2010 1 20 2
...
• Para la función map emitiremos pares compuestos por una clave compuesta
(resource, year, month, day) y un valor 1, generando dato como:
{resource: 'index', year: 2010, month: 0, day: 20} => [{count: 1},
{count: 1}]
• La función reduce recoge cada dato intermedio y genera un resultado final:
{resource: 'index', year: 2010, month: 0, day: 20} => {count: 3}
• Documentación en:
– http://docs.mongodb.org/manual/reference/method/db.collection.mapReduce/
Ejemplo de MapReduce](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-78-2048.jpg)
![79
• Creamos la colección de entrada con un conjunto de documentos:
db.hits.insert({resource: 'index', date: new Date(2010, 0, 20, 4, 30)});
db.hits.insert({resource: 'index', date: new Date(2010, 0, 20, 5, 30)});
...
• La función map:
var map = function() {
var key = {resource: this.resource, year: this.date.getFullYear(), month:
this.date.getMonth(), day: this.date.getDate()};
emit(key, {count: 1});
};
• La función reduce:
var reduce = function(key, values) {
var sum = 0;
values.forEach(function(value) {
sum += value['count'];
});
return {count: sum};
};
• Ejecutamos mapReduce():
db.hits.mapReduce(map, reduce, {out: {inline:1}})
Ejemplo de MapReduce](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-79-2048.jpg)


![84
Acumuladores sobre Grupos
Expression Description Example
$sum Sums up the defined value from all documents
in the collection
db.ships.aggregate([{$group : {_id : "$operator",
num_ships : {$sum : "$crew"}}}])
$avg Calculates the average of all given values from
all documents in the collection.
db.ships.aggregate([{$group : {_id : "$operator",
num_ships : {$avg : "$crew"}}}])
$min Gets the minimum of the corresponding values
from all documents in the collection.
db.ships.aggregate([{$group : {_id : "$operator",
num_ships : {$min : "$crew"}}}])
$max Gets the maximum of the corresponding values
from all documents in the collection.
db.ships.aggregate([{$group : {_id : "$operator",
num_ships : {$max : "$crew"}}}])
$push Pushes the value to an array in the resulting
document
db.ships.aggregate([{$group : {_id : "$operator",
classes : {$push: "$class"}}}])
$addToSet Pushes the value to an array in the
resulting document but does not create duplicates.
db.ships.aggregate([{$group : {_id : "$operator",
classes : {$addToSet : "$class"}}}])
$first Gets the first document from the source
documents according to the grouping. Typically this
makes only sense together with some previously
applied “$sort”-stage.
db.ships.aggregate([{$group : {_id : "$operator",
first_class : {$first : "$class"}}}])
$last Gets the last document from the source
documents according to the grouping. Typically this
makes only sense together with some previously
applied “$sort”-stage.
db.ships.aggregate([{$group : {_id : "$operator",
last_class : {$last : "$class"}}}])](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-84-2048.jpg)

















![106
1. Hacemos una conexión con la BBDD MongoDB
from pymongo import MongoClient
client = MongoClient()
• Podemos alternativamente hacer que el cliente mongo (MongoClient) se
conecte a otro puerto con el comando:
client = MongoClient('localhost', 27017)
• O alternativamente:
client = MongoClient('mongodb://localhost:27017/')
2. Accedemos a la BBDD, usando el estilo de acceso a atributos o a
diccionarios:
db = client.test_database
db = client['test-database']
3. Para acceder a una colección usamos código similar.
collection = db.test_collection
collection = db['test-collection']
PyMongo: Python y MongoDB](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-106-2048.jpg)
![107
4. Mientras que los datos en MongoDB se representan en JSON, su
equivalencia en pymongo son los diccionarios:
– El siguiente diccionario puede usarse para representar un post de un blog:
import datetime
post = {"author": "Mike", "text": "My first blog post!",
"tags": ["mongodb", "python", "pymongo"], "date":
datetime.datetime.utcnow()}
5. Para insertar datos en MondoDB usamos el método insert
posts = db.posts
post_id = posts.insert(post)
post_id
6. Podemos recuperar el listado de colecciones con el comando:
db.collection_names()
7. Para recuperar un solo documento usamos find_one()
posts.find_one()
PyMongo: Python y MongoDB](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-107-2048.jpg)
![108
8. El método find_one()también permite seleccionar elementos específicos que
cumplen un filtro, ej. documentos cuyo autor es “Mike”
posts.find_one({"author": "Mike"})
9. También podemos encontrar un post por _id que en nuestro ejemplo es de tipo
ObjectId.
posts.find_one({"_id": post_id})
post_id_as_str = str(post_id)
posts.find_one({"_id": post_id_as_str}) # No result
10. También se permiten inserciones en bloque con bulk inserts:
new_posts = [{"author": "Mike",
"text": "Another post!",
"tags": ["bulk", "insert"],
"date": datetime.datetime(2009, 11, 12, 11, 14)},
{"author": "Eliot",
"title": "MongoDB is fun",
"text": "and pretty easy too!",
"date": datetime.datetime(2009, 11, 10, 10, 45)}]
posts.insert(new_posts)
PyMongo: Python y MongoDB](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-108-2048.jpg)
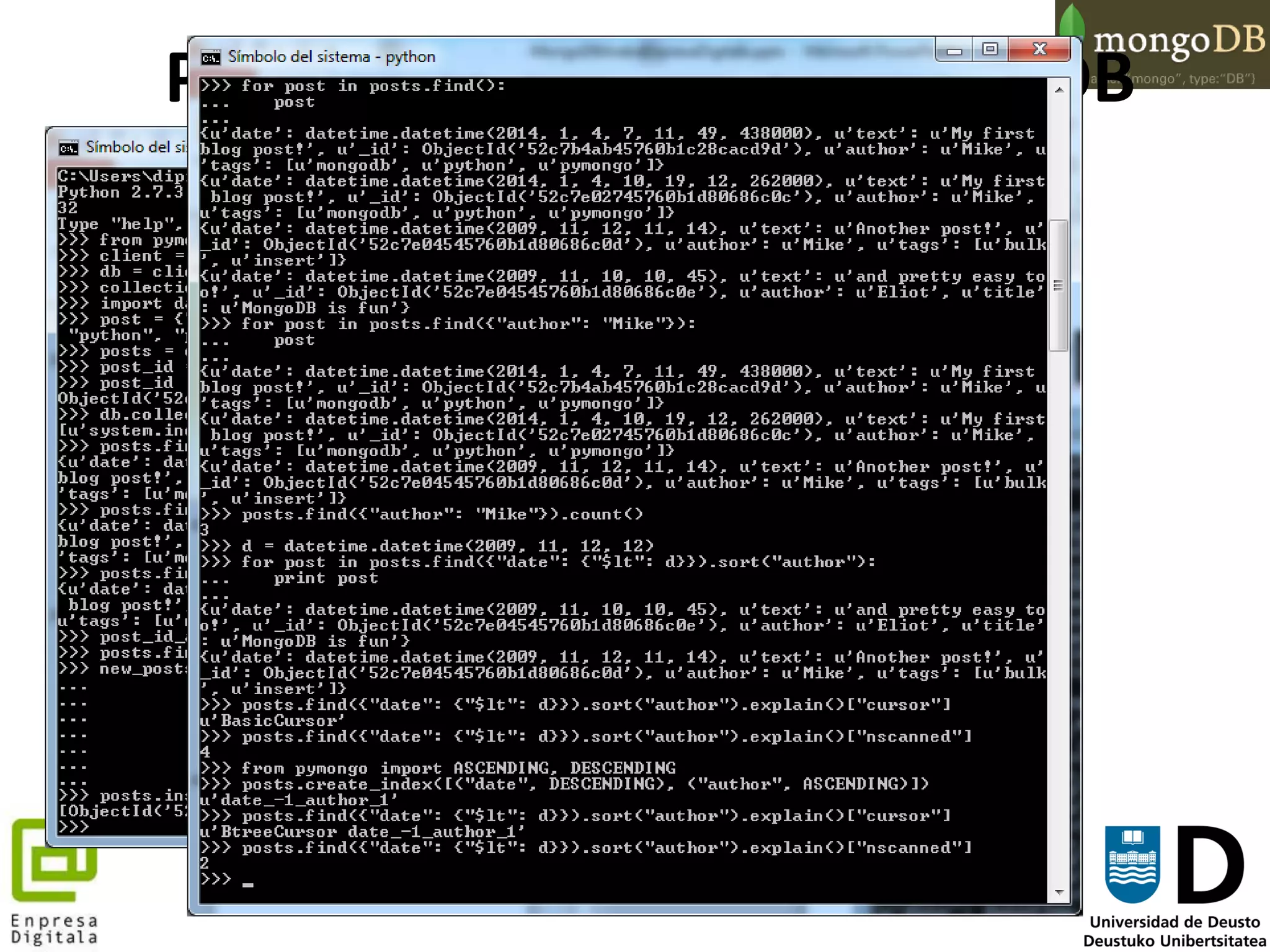
![109
11. Consultando más de un documento puede hacerse del siguiente modo:
for post in posts.find():
post
for post in posts.find({"author": "Mike"}):
post
11. Contando los posts:
posts.count()
posts.find({"author": "Mike"}).count()
11. Consultas de rangos:
d = datetime.datetime(2009, 11, 12, 12)
for post in posts.find({"date": {"$lt": d}}).sort("author"):
print post
11. Indexación:
posts.find({"date": {"$lt": d}}).sort("author").explain()["cursor"]
posts.find({"date": {"$lt": d}}).sort("author").explain()["nscanned"]
11. Creamos un índice compuesto para reducir la búsqueda:
from pymongo import ASCENDING, DESCENDING
posts.create_index([("date", DESCENDING), ("author", ASCENDING)])
posts.find({"date": {"$lt": d}}).sort("author").explain()["cursor"]
posts.find({"date": {"$lt": d}}).sort("author").explain()["nscanned"]
# Ahora la consulta está usando un BtreeCursor y sólo escanea los dos documentos
encontrados
PyMongo: Python y MongoDB](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-109-2048.jpg)




![117
• Ejemplo sencillo de código en node.js con driver nativo MongoDB:
// Retrieve
var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb",
function(err, db) {
if(err) { return console.dir(err); }
var collection = db.collection('test');
var docs = [{mykey:1}, {mykey:2}, {mykey:3}];
collection.insert(docs, {w:1}, function(err, result) {
collection.find().toArray(function(err, items) {});
var stream = collection.find({mykey:{$ne:2}}).stream();
stream.on("data", function(item) {});
stream.on("end", function() {});
collection.findOne({mykey:1}, function(err, item) {});
});
});
• Documentación:
– http://mongodb.github.io/node-mongodb-native/api-articles/nodekoarticle1.html
– https://github.com/christkv/node-mongodb-native
MongoDB y node.js](https://image.slidesharecdn.com/mongodbarabaenpresadigitala-140212091044-phpapp01/75/MongoDB-la-BBDD-NoSQL-mas-popular-del-mercado-117-2048.jpg)









Este documento presenta MongoDB, una base de datos NoSQL orientada a documentos. Explica las características principales de MongoDB, incluyendo consultas ad hoc, indexación, replicación, balanceo de carga y almacenamiento de archivos. También introduce conceptos clave de bases de datos NoSQL como eventual consistency, sharding y replication.























































































