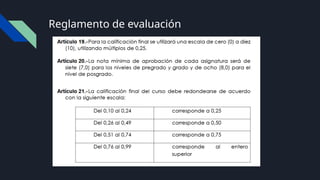
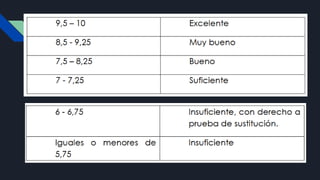
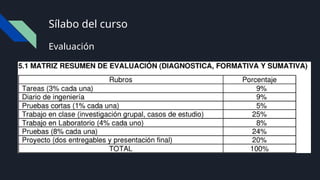
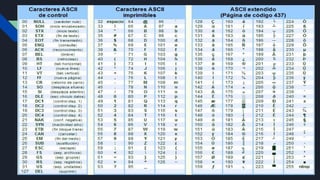
Tecnologías de información
LasTecnologías de la Información y las
Comunicaciones (TIC), son el conjunto de
recursos, herramientas, equipos, programas
informáticos, aplicaciones, redes y medios;
que permiten la compilación,
procesamiento, almacenamiento,
transmisión de información como: voz,
datos, texto, video e imágenes
17.
Diagnóstico inicial
1. Porqueelegimos la carrera( Como se llama y que significa
su nombre)
2. Que es una base de datos
3. Cual es la importancia
4. Han usado alguna base de datos antes.
18.
Regresemos en elTiempo
https://www.youtube.com/watch?v=V7qg1WGSdvc
Almacenamiento Físico
Es lautilización de dispositivos físicos, para guardar los archivos, los
cuales permiten.
Control total: No están sujetos a las políticas o términos de servicio de
terceros proveedores. Además, no se ven afectados por problemas de
conexión a Internet o interrupciones en los servicios en la nube.
Privacidad: N no tienen que preocuparse por el acceso no autorizado a
través de internet. Los datos almacenados en dispositivos físicos están a
salvo de posibles brechas de seguridad en la nube.
Acceso sin conexión: En situaciones en las que no se dispone de conexión a
internet, el almacenamiento físico permite un acceso inmediato a los
archivos. Esto es especialmente útil durante viajes o en zonas con una
conectividad limitada.
21.
Almacenamiento en laNube
Permite almacenar en espacios de terceros la información.
Acceso remoto: Pueden acceder a sus archivos desde cualquier dispositivo con conexión a
Internet.
Sincronización automática: Los servicios en la nube ofrecen la capacidad de sincronizar archivos
automáticamente en todos los dispositivos asociados. Cualquier cambio realizado en un archivo
se reflejará en todas las ubicaciones donde se haya iniciado sesión.
Seguridad de los datos: Los proveedores de almacenamiento en la nube generalmente
implementan medidas de seguridad sólidas para proteger los datos de los usuarios. Esto incluye
cifrado de extremo a extremo, autenticación de dos factores y copias de seguridad regulares.
Escalabilidad: De ocuparlo puede solicitar mayor espacio de almacenamiento al proveedor
Tranquilidad: Al contratar el servicio el proveedor se encarga de tareas de control, seguridad,
22.
Considera usted queserán reemplazados los
dispositivos físicos por almacenar en la nube
23.
● Diversidad denecesidades: los dispositivos de almacenamiento físico, son
útiles cuando se necesita un acceso rápido y offline a los datos. Por otro lado, la
nube es ideal para el acceso desde cualquier lugar con conexión a Internet y
para la colaboración en línea.
● Seguridad y privacidad: algunas personas y organizaciones pueden ser
reticentes a almacenar datos confidenciales o sensibles en la nube debido a
preocupaciones sobre la seguridad y la privacidad. Optan por dispositivos de
almacenamiento locales, donde tienen un mayor control sobre la seguridad de
sus datos.
24.
● Ancho debanda limitado: en áreas con conexiones a Internet lentas o
costosas, el almacenamiento en la nube puede no ser tan eficiente para la
transferencia de grandes cantidades de datos. En tales casos, los dispositivos
de almacenamiento físico son más prácticos para la copia de seguridad y la
transferencia de datos.
● Costos y límites de almacenamiento: los servicios de almacenamiento en la
nube suelen ofrecer una cantidad limitada de almacenamiento gratuito, pero
cobran por cantidades adicionales. Para usuarios y organizaciones con grandes
volúmenes de datos, los costos pueden aumentar, así que el almacenamiento
físico puede ser una alternativa más económica a largo plazo.
● Cumplimiento normativo: algunas industrias y regulaciones requieren que
ciertos datos se almacenan localmente y no en la nube debido a requisitos
específicos de cumplimiento normativo.
25.
¿Qué son losarchivos planos?
Un archivo plano es un tipo de archivo de almacenamiento de datos en
el que los datos se almacenan como texto sin formato, a menudo en
una estructura similar a una tabla con filas y columnas. Cada fila
representa un solo registro, mientras que las columnas representan
campos o atributos de los datos. Los formatos más comunes para
archivos sin formato son valores separados por comas (CSV), valores
separados por tabuladores (TSV) y archivos de texto sin formato. Los
archivos planos se utilizan ampliamente por su simplicidad, facilidad de
lectura humana y compatibilidad con varias plataformas y aplicaciones.
26.
Usos de ArchivosPlanos
Permiten el intercambio y procesamiento de datos debido a su estructura simple,
legibilidad humana y facilidad de manipulación en diferentes plataformas y aplicaciones.
Por ejemplo , los archivos planos se emplean comúnmente en operaciones de
importación y exportación de datos, donde las aplicaciones o sistemas con diversos
mecanismos de almacenamiento de datos necesitan comunicarse o transferir datos.
Un ejemplo es el uso de archivos CSV para importar contactos de un cliente de correo
electrónico a otro o para cargar datos externos en sistemas de administración de bases
de datos.
27.
Tipos de archivosplanos
Valores separados por comas (CSV) : los archivos CSV usan comas como delimitadores de campo y se
encuentran entre los formatos de archivo planos más utilizados. Son fáciles de leer y compatibles con numerosas
aplicaciones, como Microsoft Excel, Google Sheets y varios lenguajes de programación
Valores separados por tabuladores (TSV) : los archivos TSV utilizan tabulaciones como delimitadores de campo,
lo que ofrece una estructura similar a los archivos CSV pero con una legibilidad mejorada, especialmente para los
datos que contienen comas.
Archivo XML . El XML (Extensible Markup Language) es un lenguaje diseñado para representar datos
estructurados en formato legible por humanos.
Archivos de pares clave-valor : estos archivos planos almacenan datos como una colección de pares clave-valor,
a menudo delimitados por un signo igual o dos puntos.
JSON Lines (JSONL) : aunque no es estrictamente un archivo plano, JSON Lines es un formato delimitado por
líneas en el que cada línea representa un objeto JSON.
28.
Archivo de datosrelacional
Las bases de datos relacionales se construyen sobre los principios del modelo
relacional, usando tablas para representar entidades y relaciones entre ellas.
Ofrecen funciones avanzadas, como capacidades de consulta, indexación,
restricciones de integridad de datos y soporte de transacciones.
Son adecuadas para situaciones que requieren relaciones de datos complejas, alta
escalabilidad o manipulación sólida de datos. Por ejemplo, un sitio web de
comercio electrónico podría utilizar una base de datos relacional para administrar
el inventario de productos, los pedidos de los clientes y las cuentas de los
usuarios, manejando de manera eficiente las complejas relaciones entre estas
entidades.
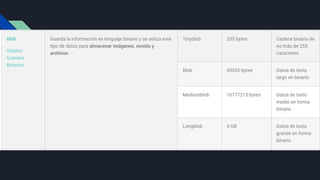
Archivos Binarios
Un archivobinario contiene datos codificados en formato binario.
Comprende una secuencia de bytes no está destinado a ser
interpretado como texto. Los archivos binarios están diseñados
para ser leídos por computadoras en lugar de humanos y pueden
representar imágenes, audio, video, programas ejecutables y otros
tipos de datos.
31.
Son esenciales parael almacenamiento, procesamiento y
transmisión eficiente de grandes volúmenes de datos. Debido
a que los sistemas informáticos pueden procesarlos
fácilmente, los archivos binarios aceleran el funcionamiento
de aplicaciones que dependen del acceso y manipulación
rápidos de datos, como juegos de computadora, sistemas en
tiempo real y computación de alto rendimiento tareas.
32.
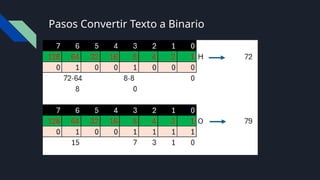
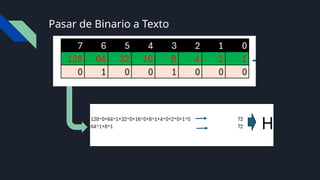
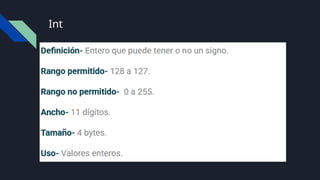
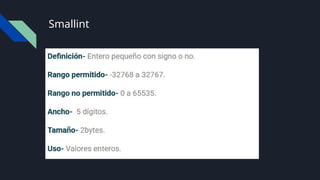
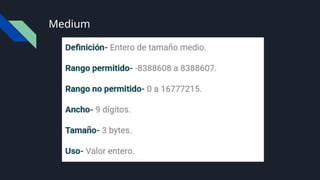
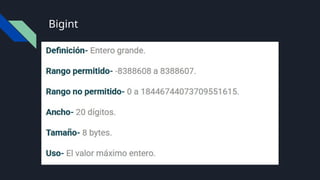
Bit y Byte
Bit:Es la unidad mas pequeña de la informática y puede
almacenar 0 y 1
Byte: 1 byte son 8 bits, por lo que 1 byte puede llegar a
representar 28
(256) estados diferentes.
UTN = 0000101001110101 101101010
UTN= 01010101
01010100 01001110
Informática=
I 01001001
n 01101110
f 01100110
o 01101111
r 01110010
m 01101101
á 1010000
t 01110100
i 01101001
c 01100011
a 0110001
1. Acceso secuencial
Eneste método, las operaciones de lectura o escritura se realizan de forma
consecutiva, es decir, sobre el registro que está físicamente contiguo al
último utilizado. Este tipo de acceso es típico de los primeros dispositivos de
almacenamiento, como:
● Tarjetas perforadas.
● Cintas perforadas.
● Cintas magnéticas.
Ejemplo: Imagínate una lista de pedidos almacenada en un archivo. Si
quieres acceder al pedido número 50, debes leer los primeros 49 antes de
llegar a él. Este método es eficiente cuando necesitas procesar todos los
registros en orden.
43.
2. Acceso directo
Losregistros pueden ser leídos o escritos directamente en la posición física
que ocupan dentro del archivo, sin necesidad de recorrer todos los
anteriores. Este tipo de acceso se utiliza en tecnologías como:
● Discos duros.
● Unidades de estado sólido (SSD).
Ejemplo: Tienes un archivo que almacena productos en un almacén. Si
sabes que el producto con código «PRD00567» está en la posición 100,
puedes ir directamente a esa posición sin revisar los registros anteriores.
44.
3. Acceso poríndice
Este método utiliza un índice para organizar las claves de los registros en el
archivo. El índice es como un «mapa» que indica dónde se encuentra físicamente
cada registro en el almacenamiento.
● Cómo funciona:
○ Se crea una lista ordenada con las claves del archivo.
○ Cada clave está asociada con la dirección real del registro.
○ Para acceder a un registro, primero se busca la clave en el índice, lo que
permite localizar rápidamente su posición en el archivo.
Ejemplo: Piensa en un archivo de clientes donde cada cliente tiene un número único
(NIF). El índice puede estar ordenado alfabéticamente por NIF, y al buscar
«12345678X», el índice te lleva directamente al registro correspondiente, sin
necesidad de recorrer otros clientes
45.
Tipos de Basede datos
Una base de datos es una colección organizada y estructurada
de información que se puede acceder y gestionar fácilmente.
Los datos se administran a través de un sistema de gestión de
base de datos (DataBase Management System o DBMS).
46.
Dato
Un dato nospermite describir un objeto. A dicho objeto se le puede
llamar entidad, como por ejemplo una casa en la que viven
personas. La casa es la entidad y la cantidad de personas que
viven en ella es un dato, que en este caso es numérico.
Hay diversos tipos de datos en las bases de datos: caracteres,
numéricos, imágenes, fechas, monedas, texto, bit, decimales y
varchar y su elección adecuada depende del tipo de dato. Es
esencial comparar un dato con otros para que adquiera significado
y poder identificar
47.
Tipos de Basesde datos
Elabore en grupos de 3 una investigación sobre cuales son las principales softwares
para el manejo de base de datos y los principales usos y las tendencias que tienen las
bases de datos relacionales y no relacionales en la actualidad, de ejemplos de empresas
grandes que hagan uso de ellas.
Además Investigue a Nivel Nacional cuales son los perfiles profesionales que requiere el
mercado laboral de un profesional Administrador de Base de datos
Tiempo 45 minutos.
48.
Trabajo en Claseinvestigación 30 min
La administración de Base de Datos en la Actualidad
Elabore en grupos de 3 una investigación donde se explique el papel que juega las
bases de datos en la actualidad. Aspectos a tomar en cuenta.
● Definición de Base Datos
● Los avances tecnológicos que ha surigido en la administración de una base
datos
● Responsabilidades de un Administrador de Base de Datos
● Principales software para la administración de base de datos
● Tendencias actuales en Base de datos relacionales y no relacionales y que
son cada una
● Ejemplo de Empresas Internacionales y sus software de gestión de base de
datos
● Perfiles profesionales para optar por un puesto de Administrador de Base
de datos en puestos Costarricenses
49.
Tipos de basesde datos
Las diferentes categorías de bases de datos no son
necesariamente excluyentes unas con otras, siendo su más grande
diferenciación entre las relacionales y las no relacionales
50.
Bases de datosrelacionales
Como su nombre lo indica, utilizan el modelo relacional y siempre
es mejor usarlas cuando los datos que vas a utilizar son
consistentes y ya tienen una estructura planificada.
● Las bases de datos relacionales funcionan bien con datos
estructurados.
● Las organizaciones que tienen muchos datos no estructurados
o semiestructurados no deberían considerar una base de
datos relacional.
51.
Bases de datosNoSQL o no relacionales
A diferencia de las bases de datos relacionales, los datos de una base de
datos NO-SQL (Not Only SQL) son más flexibles en cuanto a consistencia
de datos y se han convertido en una opción que intenta solucionar algunas
limitaciones que tiene el modelo relacional. Este tipo de base de datos es
excelente para las organizaciones que buscan almacenar datos no
estructurados o semiestructurados.
Una de las ventajas de las bases de datos NoSQL es que los
desarrolladores pueden realizar cambios en la base de datos sobre la
marcha, sin que ello afecte a las aplicaciones que la utilizan.
52.
RELACIONALES
Ejemplos:
● MySQL
● MicrosoftSQL Server
● Oracle Database
● PostgreSQL
● IBM Db2
NO RELACIONALES
Ejemplos:
● MongoDB
● Redis
● Apache Cassandra
● Apache CouchDB
● CouchBase
53.
RESUMEN BASE DATOSRELACIONAL Y NO
RELACIONAL
https://www.youtube.com/watch?v=xkMDTulV8r4
Las empresas queno priorizan una administración adecuada
suelen enfrentar problemas de rendimiento, como tiempos de
respuesta lentos y procesos ineficientes, lo que se traduce en una
mala experiencia del usuario y una pérdida de productividad.
Además, una administración deficiente aumenta el riesgo de
fallos críticos, que pueden incluir pérdida de datos, tiempos de
inactividad prolongados y vulnerabilidades de seguridad, todo lo
cual impacta directamente en la rentabilidad de la empresa.
56.
Administración de basesde datos
● Protege el flujo de trabajo y los datos del negocio.
● Asegurar la disponibilidad, integridad y seguridad de los
datos,
● Implementando ajustes
● Optimizaciones constantes para mantener los sistemas
ágiles y estables.
57.
Big data
Conjuntos dedatos extremadamente grandes y complejos que no pueden gestionarse ni
analizarse fácilmente con las herramientas tradicionales de procesamiento de datos, en
particular las hojas de cálculo. Incluyen datos estructurados, como una base de datos de
inventario o una lista de transacciones financieras; datos no estructurados, como
publicaciones sociales o videos; y conjuntos de datos mixtos, como los que se utilizan para
entrenar grandes modelos de lenguaje para la IA.
58.
¿Cuáles son lascinco "V" de Big Data?
● Volumen. Para procesar grandes volúmenes de datos no estructurados de
baja densidad, sean de valor desconocido, como feeds de datos de X (antes
llamado Twitter), flujos de clics de una página web o aplicación para
móviles, o equipo con sensores. Para algunas organizaciones sean decenas
de terabytes 0 cientos de petabytes.
● Velocidad. El ritmo al que se reciben los datos y (posiblemente) al que se
aplica alguna acción. La mayor velocidad de los datos normalmente se
transmite directamente a la memoria, en vez de escribirse en un disco.
Algunos productos inteligentes habilitados para Internet funcionan en tiempo
real o prácticamente en tiempo real y requieren una evaluación y actuación
en tiempo real.
59.
¿Cuáles son lascinco "V" de Big Data?
● Variedad. La variedad hace referencia a los diversos tipos de datos
disponibles. Los datos convencionales eran estructurados y podían
organizarse claramente en una base de datos relacional. Con el auge
del big data, los datos se presentan en nuevos tipos de datos no
estructurados. Los tipos de datos no estructurados y
semiestructurados, como el texto, audio o video, requieren un
preprocesamiento adicional para poder obtener significado y habilitar
los metadatos.
● Veracidad. Está ligada a otros conceptos funcionales, como la calidad
y la integridad de los datos, dirigen la organización hacia un repositorio
de datos de alta calidad, precisos y confiables para potenciar las
percepciones y las decisiones.
60.
¿Cuáles son lascinco "V" de Big Data?
● Valor. Los datos tienen un valor interno en los negocios. Sin embargo,
no tienen ninguna utilidad hasta que dicho valor se descubre. Debido a
que el big data reúne tanto la amplitud como la profundidad de las
estadísticas, en algún lugar de toda esa información se encuentran
estadísticas que pueden beneficiar a tu organización. Este valor puede
ser interno, como procesos operativos que podrían optimizarse, o
externo, como sugerencias de perfiles de clientes que pueden
maximizar el compromiso.
61.
¿Cuál consideran quees la mayor vulnerabilidad
el manejo y almacenamiento de información?
63.
Atomicidad
Garantiza que todoslos pasos de una sola transacción de base de
datos se completen o se reviertan a su estado original
64.
Modelo Transaccional ACIDy BASE
ACID priorizan la coherencia sobre la disponibilidad: toda la transacción
falla si se produce un error en cualquier paso de la transacción.
BASE priorizan la disponibilidad por sobre de la coherencia. En lugar de
registrar un error en la transacción, los usuarios pueden acceder a
datos inconsistentes de manera temporal. La coherencia de datos se
logra, pero no de forma inmediata.
65.
Conjetura de Brewer(también llamada teorema CAP) establece
que cualquier almacén de datos distribuido solo puede proporcionar
dos de las tres garantías siguientes:
● Coherencia: cada operación de lectura recibe los datos
actualizados más recientes o un error.
● Disponibilidad: cada solicitud de base de datos recibe una
respuesta satisfactoria, sin garantizar que contenga los datos
actualizados más recientes.
● Tolerancia a las particiones: el sistema sigue funcionando a
pesar de los mensajes perdidos o retrasados entre los nodos
distribuidos.
66.
Por ejemplo
Un clienteagrega un artículo a un carrito en un sitio web de comercio electrónico, todos los demás
clientes deberían ver caer los niveles de disponibilidad del producto. Si el cliente agrega el último
artículo al carrito, todos los demás usuarios deberían ver el artículo como agotado. En caso de que
fallase alguna operación dentro de una transacción, los diseñadores de bases de datos deben tomar
una decisión. La base de datos puede realizar una de las siguientes acciones:
1. Cancelar la transacción y devolver un error, lo que reduce la disponibilidad pero garantiza la
coherencia. El cliente no puede agregar el artículo a su carrito u otros clientes no pueden
cargar los detalles de todos los productos hasta que agregar al carrito funcione con éxito.
2. Continuar con la operación y, por lo tanto, proporcionar disponibilidad, pero arriesgando
inconsistencias. El cliente agrega un artículo al carrito, pero otros clientes ven niveles de
disponibilidad incorrectos, al menos de manera temporal.
En algunos casos de uso, la coherencia es fundamental y se prefieren las bases de datos ACID. No
obstante, hay otros casos de uso en los que no es crítica. Por ejemplo, cuando acepta una solicitud
de amistad en las redes sociales, no importa si otros usuarios ven por un momento un número
incorrecto de amigos en su perfil. Sin embargo, no querrá perder el acceso a su feed de redes
sociales mientras se ordenan los datos. Es en estos escenarios cuando BASE adquiere importancia.
68.
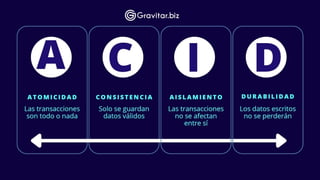
ACID
ACID representa laspalabras atomicidad, consistencia, aislamiento y durabilidad.
Atomicidad
La atomicidad garantiza que todos los pasos de una sola transacción de base de
datos se completen o se reviertan a su estado original.
Por ejemplo, en un sistema de reservas, tanto la tarea de reservar asientos como la
de actualizar los detalles del cliente, deben completarse en una sola transacción. No
puede reservar asientos para un perfil de cliente incompleto. No se modifican los
datos si se produce un error en alguna parte de la transacción.
69.
ACID
ACID representa laspalabras atomicidad, consistencia, aislamiento y durabilidad.
Coherencia
La coherencia garantiza que los datos cumplan con las restricciones de integridad y
las reglas empresariales predefinidas. Incluso si varios usuarios realizan
operaciones similares en simultáneo, los datos siguen siendo coherentes para
todos.
Por ejemplo, la coherencia asegura que, al transferir fondos de una cuenta a otra, el
balance total antes y después de la transacción siga siendo el mismo. Si la cuenta A
tiene USD 200 y la cuenta B tiene USD 400, el balance total es de USD 600.
Después de que se transfieran USD 100 de A a B, A tiene USD 100 y B tiene USD
500. El balance total sigue siendo de USD 600.
70.
ACID
ACID representa laspalabras atomicidad, consistencia, aislamiento y durabilidad.
Aislamiento
El aislamiento garantiza que una nueva transacción, que accede a un registro en
particular, espere hasta que finalice la transacción anterior antes de comenzar a
funcionar. Asegura que las transacciones simultáneas no interfieran entre sí,
manteniendo la ilusión de que se ejecutan en serie.
Ejemplo es un sistema de gestión de inventario multiusuario. Si un usuario actualiza
la cantidad de un producto, otro usuario que acceda a la misma información verá
una vista consistente y aislada de los datos, que no se verá afectada por la
actualización en curso hasta que se confirme.
Durabilidad
71.
ACID
ACID representa laspalabras atomicidad, consistencia, aislamiento y durabilidad.
Durabilidad
La durabilidad garantiza que la base de datos mantenga todos los registros
confirmados, incluso si se produce un error en el sistema. Asegura que todos los
cambios sean permanentes y no se vean afectados por las fallas posteriores del
sistema cuando se confirmen las transacciones de ACID.
Por ejemplo, en una aplicación de mensajería, cuando un usuario envía un mensaje
y recibe una confirmación de entrega correcta, la propiedad de durabilidad garantiza
que el mensaje nunca se pierda. Esto sigue siendo así incluso si la aplicación o el
servidor fallan.
72.
BASE
BASE significa coherenciaeventual flexible básicamente disponible. El
acrónimo destaca que BASE es lo opuesto a ACID, al igual que sus
equivalentes químicos.
Básicamente disponible
Básicamente disponible hace referencia a la accesibilidad simultánea de la base
de datos por parte de los usuarios en todo momento. Un usuario no necesita
esperar a que otros finalicen la transacción para actualizar el registro.
Por ejemplo, durante un aumento repentino del tráfico en una plataforma de
comercio electrónico, el sistema puede priorizar la entrega de listados de
productos y la aceptación de pedidos. Incluso si se produce un ligero retraso en
la actualización de las cantidades en el inventario, los usuarios siguen retirando
artículos.
73.
BASE
Flexible
Flexible hace referenciaa la noción de que los datos pueden tener estados
transitorios o temporales que pueden cambiar con el tiempo, incluso sin
entradas o disparadores externos. Describe el estado de transición del
registro cuando varias aplicaciones lo actualizan en simultáneo. El valor del
registro se finaliza solo después de que se hayan completado todas las
transacciones.
Por ejemplo, si los usuarios editan una publicación en redes sociales, es
posible que el cambio no sea visible para otros usuarios de forma
inmediata. Sin embargo la publicación se actualiza por sí sola más adelante
(reflejando el cambio anterior) aunque ningún usuario la haya activado.
74.
BASE
Coherencia eventual
Coherencia eventualhace referencia a que el registro alcanzará la
coherencia cuando se hayan completado todas las actualizaciones
simultáneas. En este punto, las aplicaciones que consulten el registro verán
el mismo valor.
Por ejemplo, considere un sistema de edición de documentos distribuido en
el que varios usuarios puedan editar un documento en simultáneo. Si los
usuarios A y B editan la misma sección del documento en paralelo, sus
copias locales pueden diferir temporalmente hasta que los cambios se
propaguen y se sincronicen. Sin embargo, con el tiempo, el sistema
garantiza la coherencia eventual al propagar y combinar los cambios
realizados por los diferentes usuarios.
75.
Cuándo usar: ACIDen comparación con BASE
ACID es la opción ideal para aplicaciones empresariales que requieren coherencia de datos,
fiabilidad y previsibilidad. Por ejemplo, los bancos utilizan una base de datos ACID para almacenar
las transacciones de los clientes porque la integridad de los datos es la máxima prioridad. Mientras
tanto, las bases de datos BASE son una mejor opción para el procesamiento analítico en línea de
datos menos estructurados y de gran volumen. Por ejemplo, los sitios web de ecommerce utilizan
bases de datos BASE para actualizar los precios de los productos, que cambian con frecuencia. En
este caso, la precisión de los precios es menos vital que permitir que todos los clientes accedan en
tiempo real al precio del producto
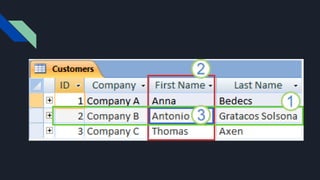
Campos y Registros
1.Un registro: contiene datos específicos, como información acerca de un determinado
empleado o un producto.
2. Un campo: contiene datos sobre un aspecto del asunto de la tabla, como el nombre
o la dirección de correo electrónico.
3. Un valor de campo: cada registro tiene un valor de campo. Por ejemplo, Contoso,
Ltd. o alguien@ejemplo.com.
81.
Campos obligatorios yopcionales
Un dato es obligatorio cuando se requiere
para que un registro o evento sea aceptado.
Por otro lado, un dato es opcional cuando no
es necesario para que se acepte un registro o
evento
82.
MySQL es unsistema de gestión de bases de datos (DBMS, por sus
siglas en inglés) de código abierto desarrollado por Oracle. Se ha ganado
su lugar en el mundo digital como una base de datos relacional que permite
almacenar, organizar y recuperar datos de manera eficiente
Usada en muchos servidores y hosting
Integrado en Servidores XAMPP y WAMP
83.
Son Tecnologías debases de datos de código abierto.
MySQL es la base de datos de código abierto más utilizada. Además, es la base de
datos relacional principal para muchos sitios web, aplicaciones y productos comerciales
populares.
MariaDB es una versión modificada de MySQL. MariaDB fue creada por el equipo de
desarrollo original de MySQL debido a problemas de licencia y distribución después de
que Oracle Corporation adquiriera MySQL. Desde la adquisición, MySQL y MariaDB han
evolucionado de manera diferente.
Los usuarios de MySQL puedan cambiar a MariaDB sin problemas.
84.
SERVIDORES
Equipo informático quebrinda recursos, programas, datos o servicios
a otros dispositivos o usuarios a través de una red. Los servidores
actúan como intermediarios, procesando las solicitudes y enviando
respuestas.
Los servidores pueden realizar diversas funciones, como:
● Almacenar datos
● Alojamiento de páginas web
● Gestión de bases de datos
● Compartir archivos
● Ejecutar aplicaciones específicas
● Gestionar el flujo de correo electrónico
85.
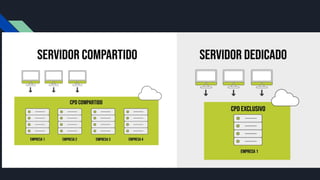
La principal diferenciaentre un servidor dedicado y uno
compartido
El primero todos los recursos están disponibles para un solo cliente,
mientras que en el segundo los recursos se comparten entre varios
usuarios.
Los servidores dedicados son más seguros, ofrecen mayor rendimiento y
flexibilidad, y permiten mayor control y personalización. Sin embargo,
suelen ser más costosos que los servidores compartidos.
Los servidores compartidos son una opción económica que se
recomienda para pequeñas empresas o sitios web personales
Crear usuario concontraseña
1. Ir a las secciones "Bases de Datos" y "Cuentas de
Usuarios".
2. En la pestaña "Bases de Datos", nombrar la base
de datos y asignarle un cotejamiento.
3. Hacer clic en "Crear".
Camel case
En Camelcase debes empezar con la
primera letra minúscula y la primera letra de
cada nueva palabra subsecuente en
mayúscula:
● cosasParaHacer
● edadDelAmigo
● valorFinal
Pascal case
También conocido como "upper camel
case" o "capital case", Pascal case
combina palabras poniéndolas todas con
la primera letra en mayúscula:
● CosasParaHacer
● EdadDelAmigo
● ValorFinal
92.
Snake case
En Snakecase, conocido también como
"underscore case", se utiliza guión bajo
(underscore) en lugar de espacio para
separar las palabras. Cuando snake case
está en mayúsculas, se le conoce como
"screaming snake case":
● cosas_para_hacer
● edad_del_amigo
● valor_final
● PRIMER_NOMBRE
● LISTA_INICIAL
Kebab case
En Kebab case se utiliza el guión para
combinar las palabras. Cuando el Kebab
case está en mayúsculas, se llama
"screaming kebab case":
● cosas-para-hacer
● edad-del-amigo
● valor-final
● PRIMER-NOMBRE
● LISTA-INICIAL