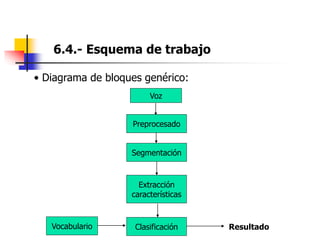
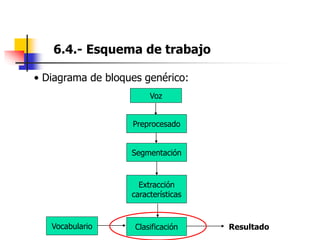
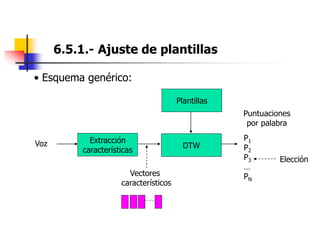
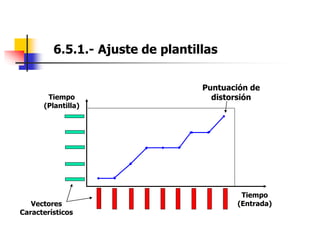
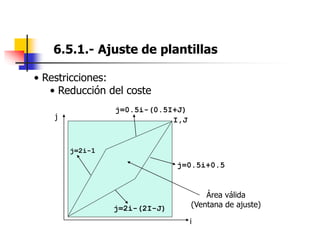
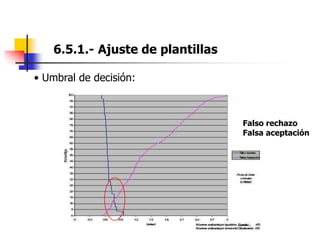
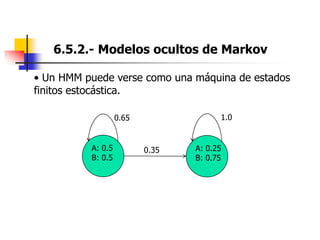
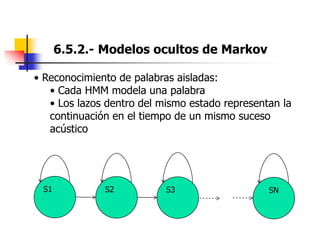
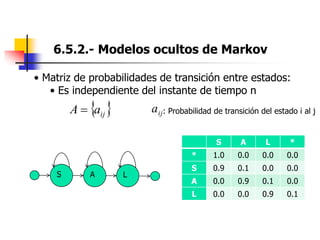
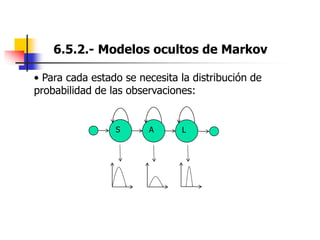
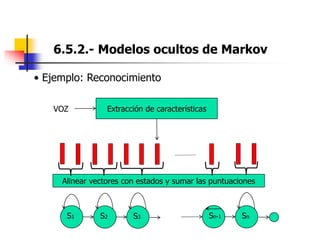
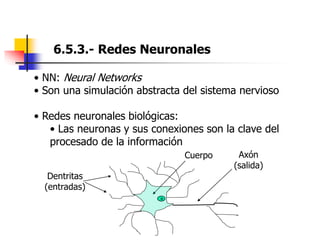
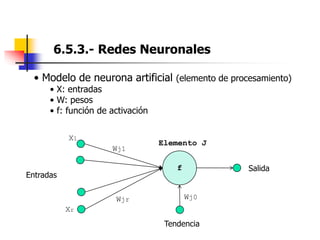
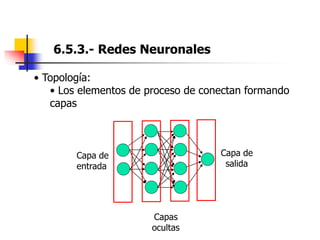
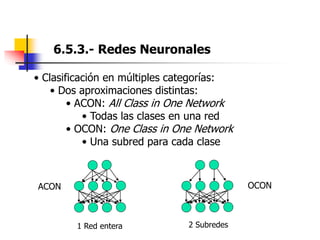
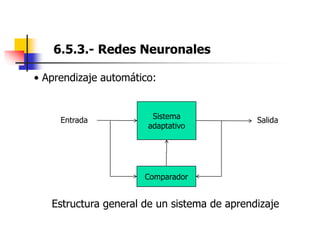
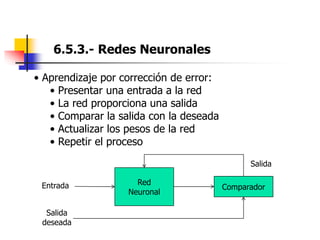
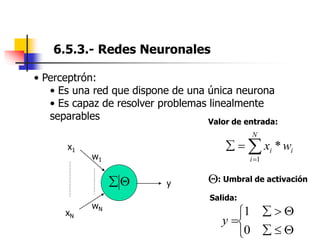
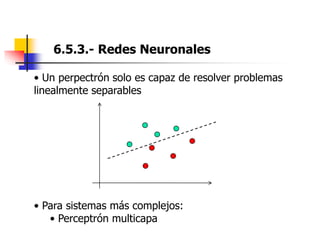
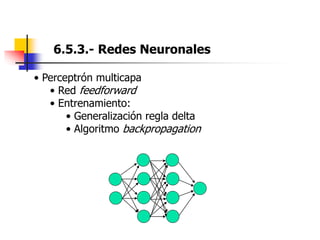
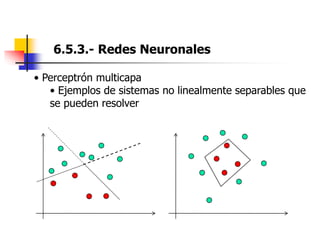
Este documento resume el tema del reconocimiento de voz en 6 secciones: introduce el tema y sus ventajas, describe los desafíos del reconocimiento de voz, clasifica los diferentes tipos de reconocedores de voz, explica el esquema general de trabajo de un reconocedor de voz, describe las principales técnicas de reconocimiento como ajuste de plantillas, modelos ocultos de Markov y redes neuronales, y concluye el tema.