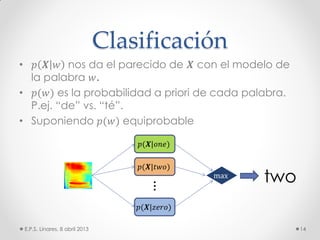
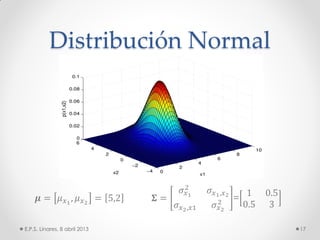
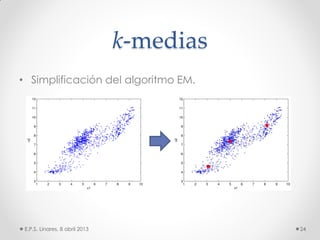
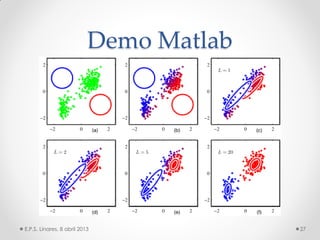
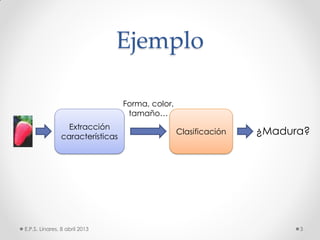
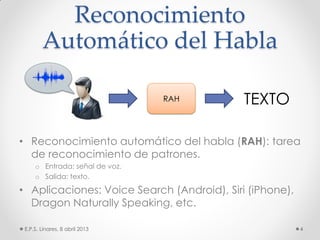
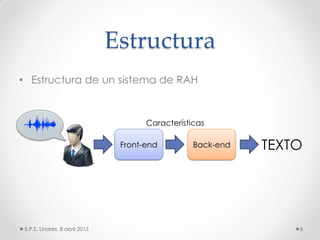
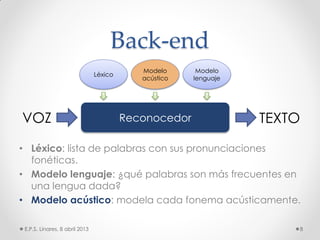
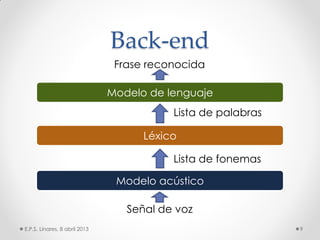
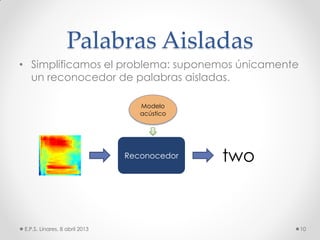
Este documento describe los modelos probabilísticos aplicados al reconocimiento automático del habla. Explica que el reconocimiento del habla es un problema de clasificación de patrones y describe los pasos comunes de extracción de características, diseño de clasificador y ajuste del clasificador. Luego, se enfoca en los modelos de mezcla de Gaussianas y ocultos de Markov para modelar acústicamente las palabras y aplicar reconocimiento de patrones temporales a la señal de voz.







![Notación
• Espectro de voz: 𝑿
• Índice en frecuencia:
𝑖 ∈ 1, 𝑛
• Índice temporal:
𝑡 ∈ [1, 𝑇]
• 𝒙 𝑡: vector columna 𝑡.
• 𝑥𝑡(𝑖): elemento 𝑖 de 𝒙 𝑡.
E.P.S. Linares, 8 abril 2013 12
𝑿
𝑇
𝑛
⋱](https://image.slidesharecdn.com/charlalinares-130909110511-/85/Modelos-Probabilisticos-Aplicacion-al-Reconocimiento-Automatico-del-Habla-13-320.jpg)