Descargar como PDF, PPTX





![6
La realidad de las iniciativas “Self-Service”
• Recientes estudios muestran la efectividad real del las iniciativas Self-Service:
• Más de un 60% de las organizaciones puntúan su experiencia con las
iniciativas Self-Service como “medias” o “bajas” [InsideAnalysis].
• Acaban produciendo un mayor número de peticiones de datos a IT ya que la
comunidad de usuarios es ahora mayor [InsideAnalysis]
• La inconsistencia de los informes (“report chaos”) puede minar estas
iniciativas [Inside Analysis]
• Los usuarios de negocio y los científicos de datos utilizan más de un 80% de
su tiempo en tareas de descubrimiento, acceso e integración de datos
[Forbes]](https://image.slidesharecdn.com/slideswebinarselfserviceanalyticsuniversalsemanticmodeles-180712134949/85/Webinar-Self-service-Analytics-con-Virtualizacion-de-Datos-6-320.jpg)



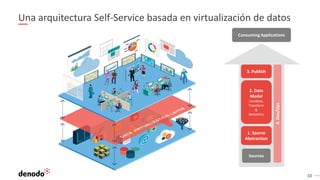
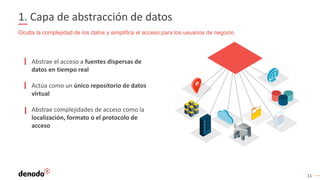




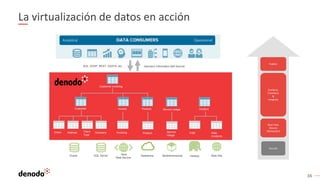

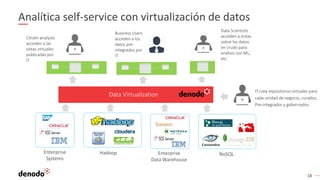






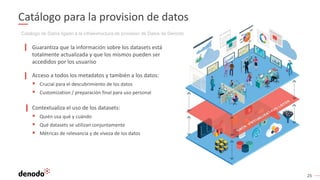




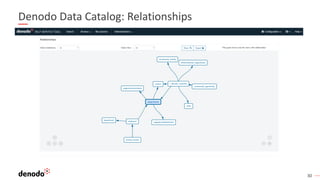





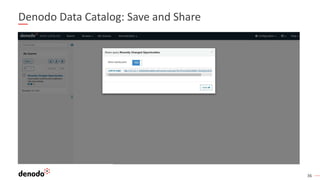









El documento describe cómo implementar analítica 'self-service' mediante virtualización de datos, destacando la promesa y realidad de estas iniciativas en organizaciones. Se enfatiza la importancia de crear repositorios de datos curados y gobernados por IT para evitar inconsistencias y optimizar el acceso a la información. Además, se presenta la arquitectura necesaria y el rol de los catálogos de datos en el descubrimiento y uso efectivo de información por parte de los usuarios de negocio.















































































