Cassandra es un gestor de base de datos no relacional, desarrollado por la Apache Software Foundation, conocido por su capacidad para manejar grandes volúmenes de datos en múltiples servidores. Originado por un proyecto de Facebook, combina el modelo de datos de Bigtable de Google con una arquitectura distribuida, lo que permite alta disponibilidad y escalabilidad. Su diseño incluye una estructura de almacenamiento basada en 'columns', 'column families' y 'keyspaces', y es utilizado por grandes organizaciones debido a su rendimiento, flexibilidad y tolerancia a fallos.
En este documento
Desarrollado con IA
Un gestor de base de datos no relacional, código abierto, manejando más de 300 TB de datos en 400 máquinas.
Cassandra nació de un proyecto de Facebook y se liberó como Open Source, a diferencia de Google que solo compartió su modelo BigTable.
BigTable aborda las limitaciones de bases de datos tradicionales, ofreciendo un mecanismo no relacional y multidimensional para sistemas distribuidos.
Presenta las diferencias del modelo relacional, enfatizando la necesidad de rendimiento y acceso instantáneo a grandes volúmenes de información.
Cassandra es un sistema distribuido formado por múltiples nodos que gestionan datos y su arquitectura tiene fortalezas y debilidades.
Utiliza un algoritmo hash para distribuir datos entre nodos, con características distintivas como la ausencia de transacciones y claves inmutables.
Define los conceptos básicos como columnas, families y keyspace, enfatizando la inmutabilidad para mejorar el rendimiento en multithreading.
Introducción a SuperColumnas y Column Families, y cómo se agrupan en un clúster que actúa como una sola unidad vista por los clientes.
Cassandra combina los modelos de BigTable y Dynamo, ofreciendo escalabilidad, tolerancia a fallos y rendimiento destacado en operaciones de lectura/escritura.
Se mencionan diferentes implementaciones de consulta que se pueden realizar.
Cassandra soporta múltiples clientes en diversas tecnologías como Python, Java, y PHP, facilitando su utilización en diferentes entornos.
Apache
¿Qué es?
Es ungestor de base de datos no relacional (NOSQL), multiplataforma de código
abierto escrita y desarrollado por Apache Software Foundation.
De acuerdo a su sitio web http://cassandra.apache.org/, la configuración de Cassandra
involucra a mas de 300 TB de datos sobre mas de 400 maquinas lo que lo hace hoy por
hoy uno de los productos mas sólidos y populares del mercado
2.
¿Cómo nace Cassandra?
•
Cassandrase originó mediante un proyecto del equipo de ingenieros de Facebook
que posteriormente han abierto con licencia Open source y colocado dentro de la
incubadora de los proyectos de Apache. Lo mismo ha hecho Google, pero a
diferencia de Facebook no ha sido tan considerado con la comunidad de
desarrolladores que sustenta el software libre. No ha liberado su implementación,
únicamente ha dado a conocer su modelo de datos: BigTable.
3.
¿ Que esBigTable?
Google creó BigTable porque los sistemas de bases de datos
tradicionales no tenían ni tienen, la capacidad de crear
sistemas lo suficientemente grandes. Además, estos
sistemas de bases de datos relacionales, como SQL
Server, Oracle o MySQL fueron pensados y diseñados para
que se ejecutasen en un solo servidor con mucha potencia.
Por ello, no encajarían en las estructuras distribuidas den
miles de servidores.
Google BigTable es un mecanismo no relacional, un
almacenamiento de datos
distribuida y multidimensional basado en las tecnologías de almacenamiento
de propiedad de Google para la mayoría de aplicaciones en línea y back-end
de la empresa / productos. Proporciona arquitectura de datos escalable para
infraestructuras de bases de datos muy grandes.
BigTable se utiliza principalmente en los productos de propiedad de Google,
aunque algunos disponible en Internet en el Google App Engine y
aplicaciones de otros fabricantes de bases de datos.
4.
- Modelo dedatos Cuando nos hablan de base de datos lo primero que se nos viene a la mente son
definiciones como “tablas”, “claves primarias”, “claves foráneas”, “relaciones”, etc.
Cuando tratamos de pasar de un modelo entidad - relación al modelo relacional,
pensamos en normalización, en evitar duplicidad de datos, etc. Pero como lo
demuestra a través de la historia no todas las aplicaciones tienen la mismas
necesidades. Y es que existe un teorema (CAP Teorema de Brewer) que explica
que no podemos tener todo (Consistencia, Alta disponibilidad y Tolerancia a fallos)
y que hemos de elegir dos. Y no todas las aplicaciones tienen las mismas
necesidades. En algunos casos, nuestras aplicaciones necesitan almacenar gran
cantidad de información que ha de ser accedida de manera casi instántanea y
estar disponible 24x7. En este caso la forma de plantearse el modelo de datos es
diferente. En un modelo relacional típico, uno crea un esquema de datos
normalizado que permite solicitar cualquier consulta y añade índices a las tablas
que permitan acelerar dichas consultas. En este nuevo esquema de datos, uno ha
de plantearse primero que consultas va a realizar y crea el esquema en base a
conseguir el máximo rendimiento en los accesos a esa información y si es
necesario duplicar los datos para conseguir mejor rendimiento. Se podría decir
que casi crea un "mapa" de datos apropiado para cada consulta que se vaya a
realizar.
6.
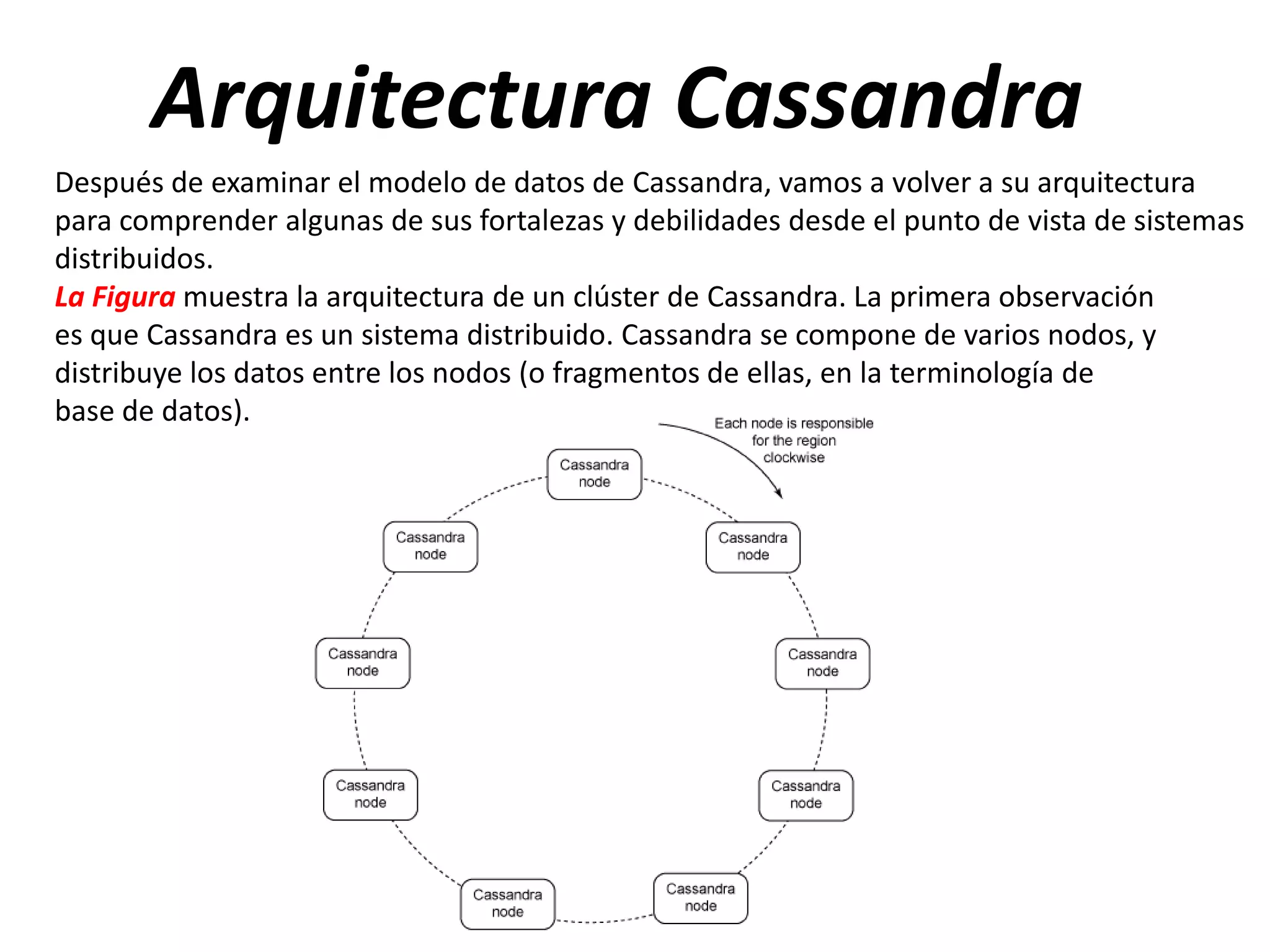
Arquitectura Cassandra
Después deexaminar el modelo de datos de Cassandra, vamos a volver a su arquitectura
para comprender algunas de sus fortalezas y debilidades desde el punto de vista de sistemas
distribuidos.
La Figura muestra la arquitectura de un clúster de Cassandra. La primera observación
es que Cassandra es un sistema distribuido. Cassandra se compone de varios nodos, y
distribuye los datos entre los nodos (o fragmentos de ellas, en la terminología de
base de datos).
7.
En términos simples,Cassandra utiliza un algoritmo hash para calcular el hash de las claves
de cada elemento de datos almacenado en Cassandra (por ejemplo, el nombre de la
columna Id. de fila). El rango de hash o todos los posibles valores de hash (también
conocido como espacio de claves) se divide entre los nodos en el cluster
Cassandra. Entonces Cassandra asigna a cada elemento de datos en el nodo y el nodo se
encarga de almacenar y gestionar el elemento de datos. El papel de "Cassandra - Un
sistema de almacenamiento estructurado descentralizada.
Posibles sorpresas con Cassandra
Tenga en cuenta estas diferencias cuando se pasa de una base de datos relacional para
Cassandra.
•
•
•
•
No hay transacciones, sin uniones
No hay claves foráneas y claves son inmutables
Keys tienen que ser únicos
La búsqueda se complica
Solo como algunas menciones.
8.
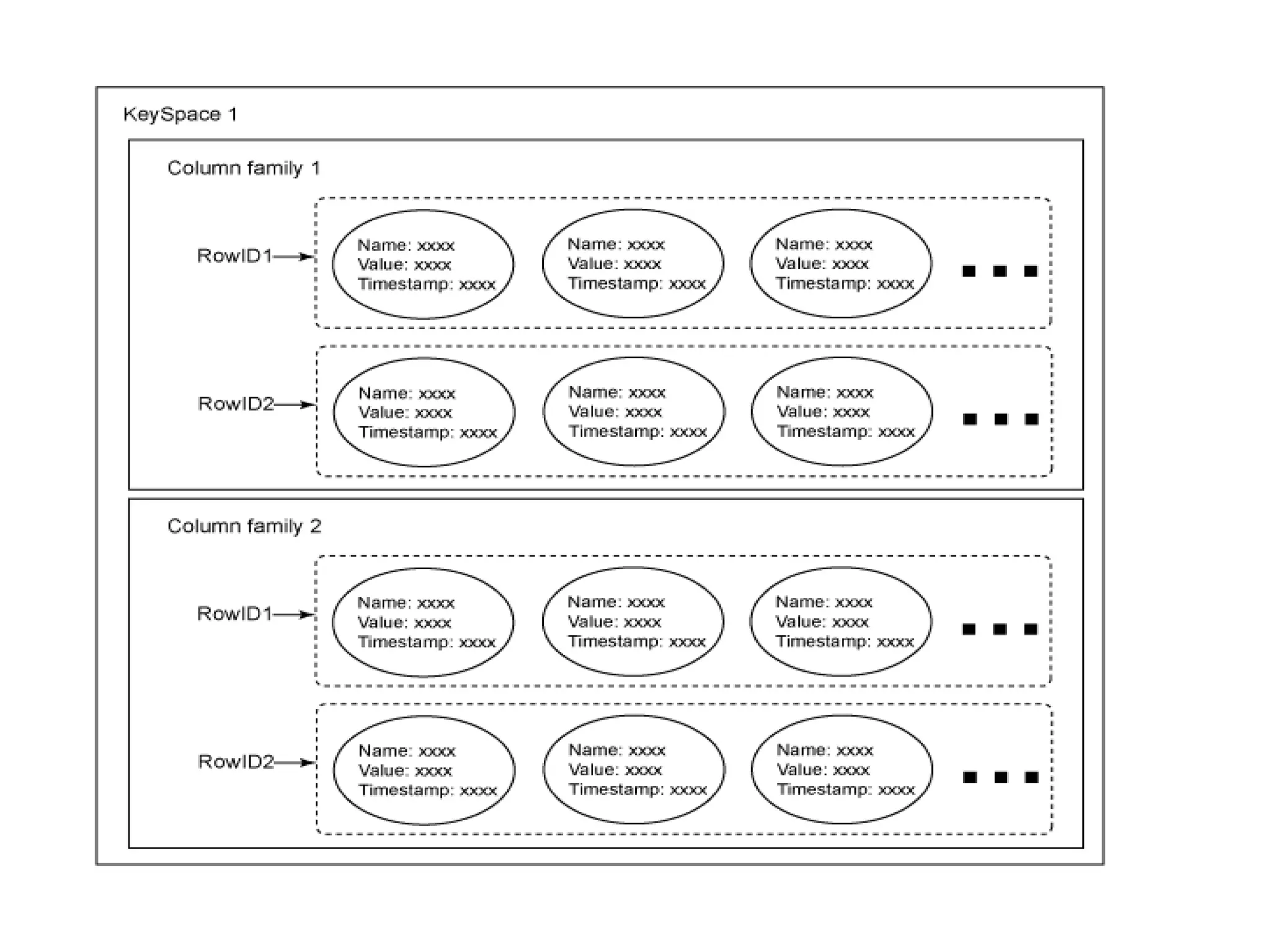
Terminología de Cassandra
Column.Es la unidad mas básica en el modelo de datos de
Cassandra. Una column es un triplete de un key (un nombre) un value
(un valor) y un timestamp. Los valores son todos suministrados por el
cliente. El tipo de dato del key y el value son matrices de bytes de Java,
el tipo de dato del timestamp es un long primitive.
column son inmutables para evitar problemas de multithreading.
Las
column se organizan dentro de las columns families.
Las
column se ordenan por un tipo, que pueden ser uno de los
Las
siguientes:
AsciiType
BytesType
LongType
TimeUUIDType
UTF8Type
9.
SuperColumn. Es unacolumn cuyos values son una o más columns,
que en este contexto se llamaran subcolumns. Las subcolumns están
ordenadas, y el numero de columnas que se puede definir es ilimitada.
Las Super columns, a diferencias de las columns, no tienen un
timestamp definido.
Column Family. Es mas o menos análogo a una tabla en un modelo
relacional. Se trata de un contenedor para una colección ordenada de
columns. Cada column family se almacena en un archivo separado
Keyspace. Es el contenedor para las column family. Es mas o menos
análogo a una base de datos en un modelo relacional, usado en
Cassandra para separar aplicaciones. Un keyspace es una colección
ordenada de columns family.
Clúster. Conjunto de máquinas que dan soporte a Cassandra y son
vistas por los clientes como una única máquina.
10.
¿Porque apostar porCassandra?
Cassandra se basa en gran medida de BigTable (modelo de datos) y Dynamo
(arquitectura), dos de las más conocidas y potentes bases de datos actuales. Esto por
sí solo puede ser suficiente para considerarlo, entre otras cosas como:
• Orientada a columnas.
• Esta hecha en java.
• Permite modificar la consistencia de los datos.
• Se puede hacer uso de CQL(Cassandra Query Language)
• Bajo una licencia Apache
• Es mantenida por la organización Apache.
• La usan grandes organizaciones como Facebook o Twitter.
• Tiene herramientas para administrar los nodos de forma gráfica.
• Es fácil de instalar en un principio.
• Solución en cluster enfocada a la escalabilidad.
• Tolerancia a fallos, cualquier nodo del cluster puede ser fácilmente sustituido.
• Descentralización de datos.
• Una comparación en tiempos de lectura y escritura de cientos de veces inferior, en
pruebas realizadas con un alto volumen de datos.
• Sencillo modelo de datos similar a una hash table.
Clientes/APIs
Cassandra tiene clientespara diferentes tecnologías
Python
Java
Node.js
Clojure
.NET
Ruby
PHP
Perl
Go
Haskell
C++
el caso de Java una alternativa interesante es Kundera, basada
En
en el paradigma JPA 2.0.