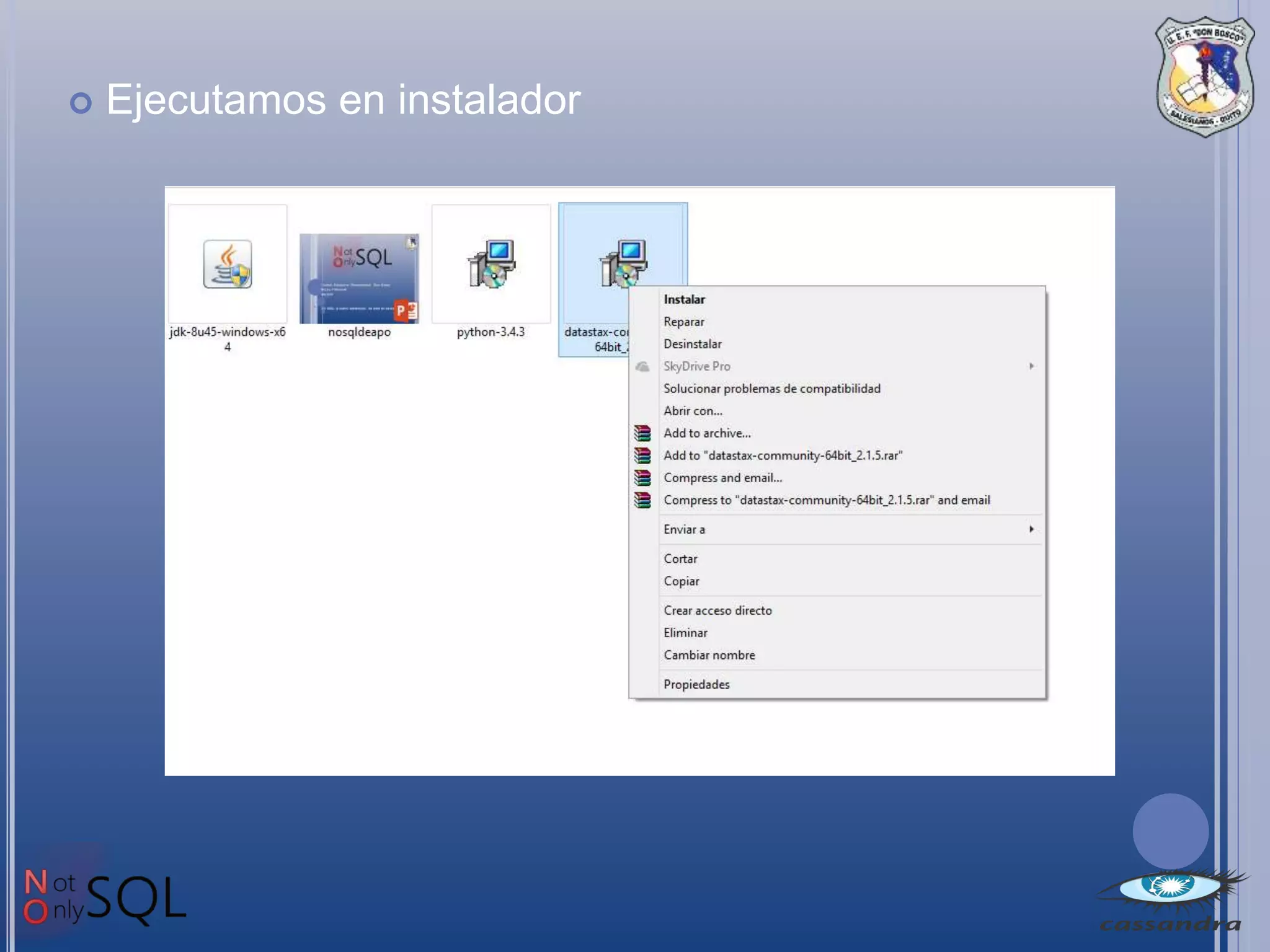
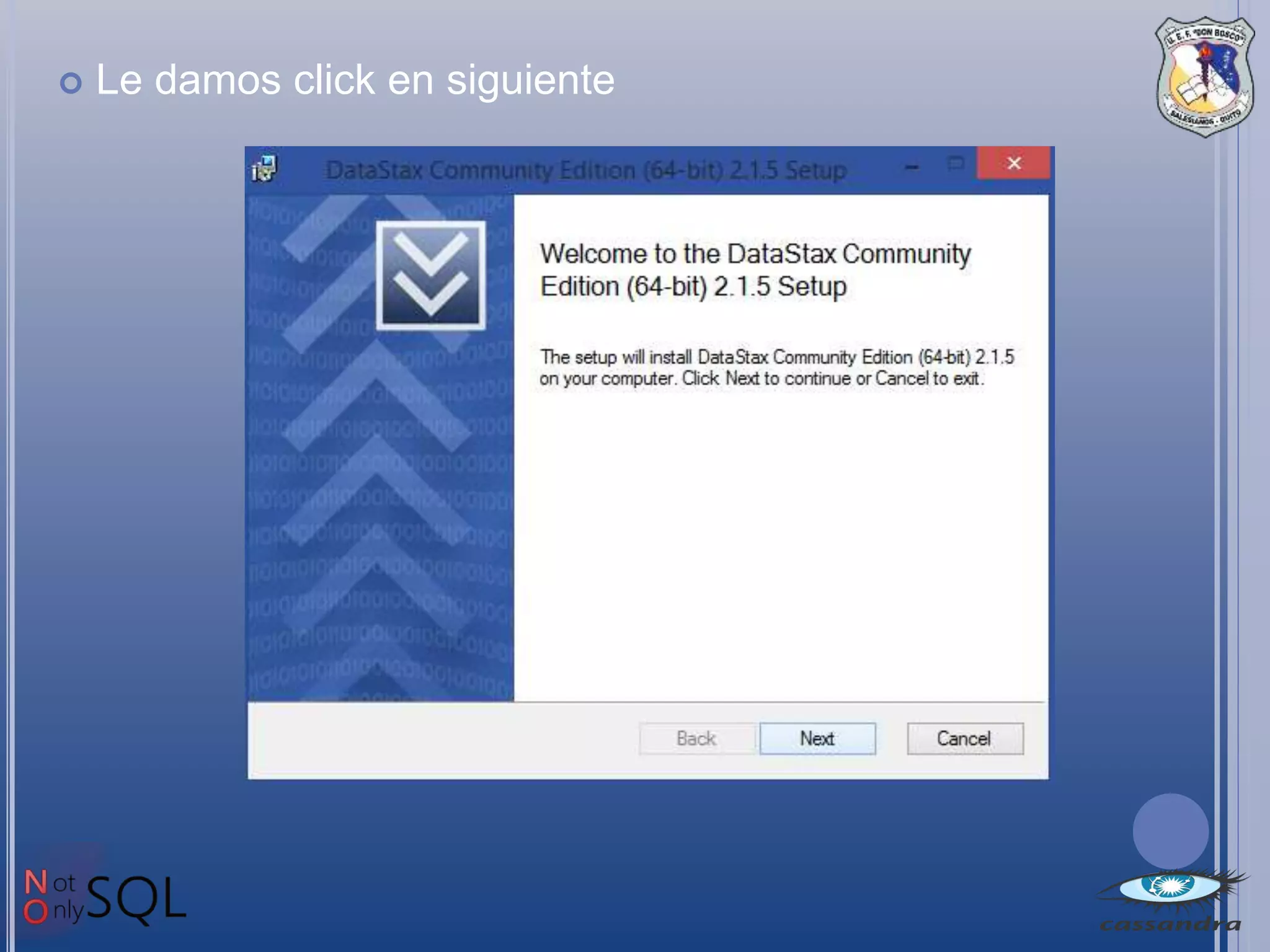
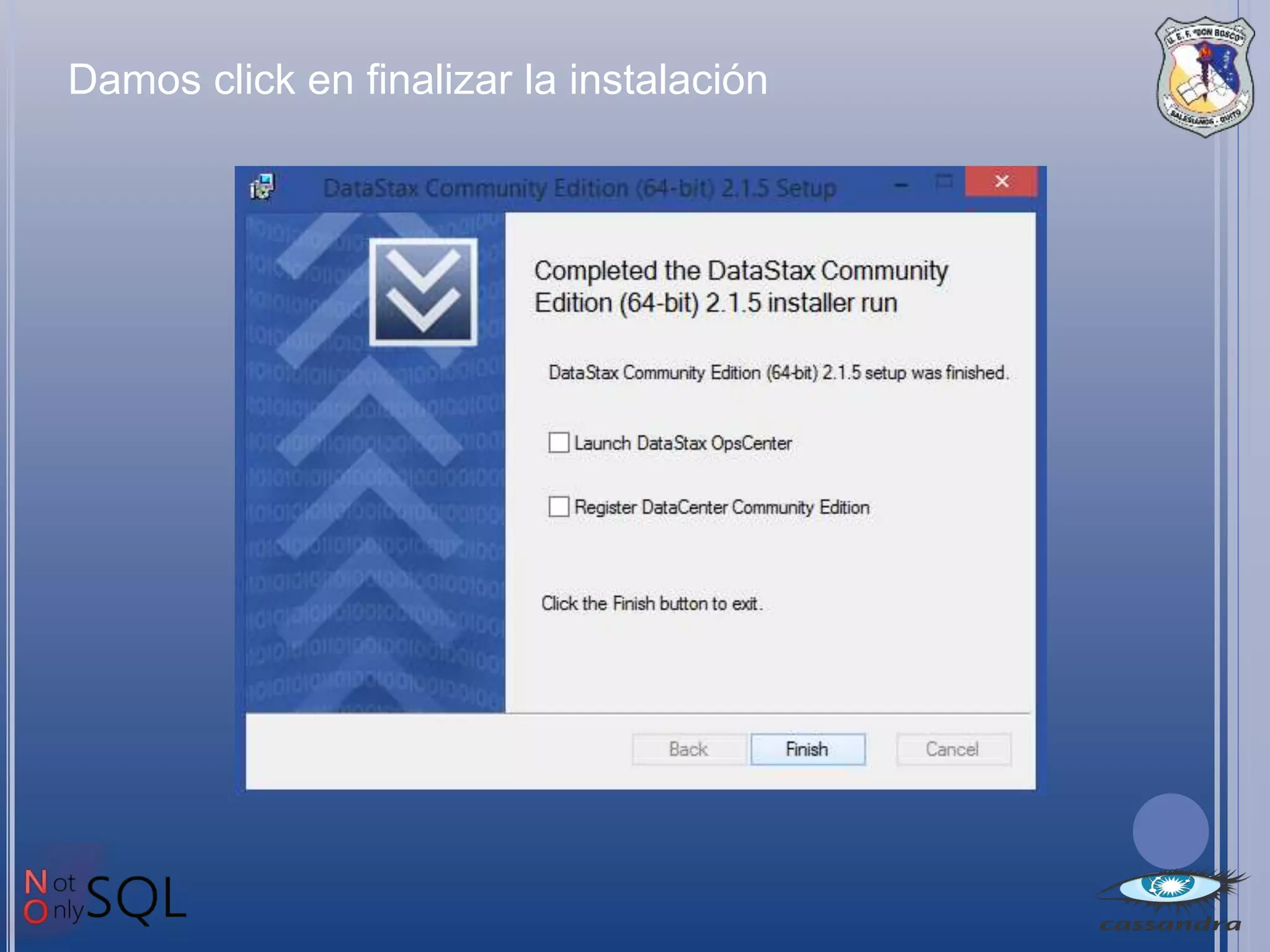
Este documento describe Apache Cassandra, una base de datos NoSQL distribuida y de código abierto. Explica que Cassandra almacena datos en forma distribuida para admitir grandes volúmenes de datos, y que su modelo de datos particiona filas en tablas con una clave de partición. También señala que Cassandra ofrece alta disponibilidad, tolerancia a fallos y escalabilidad a medida que se agregan nuevos nodos.