Descargar para leer sin conexión











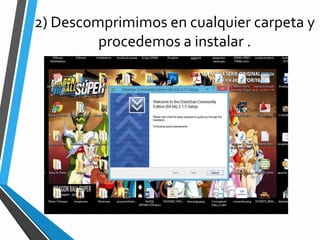

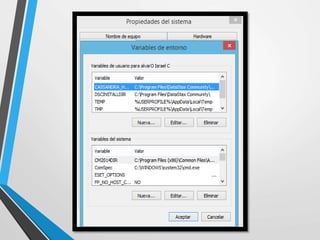
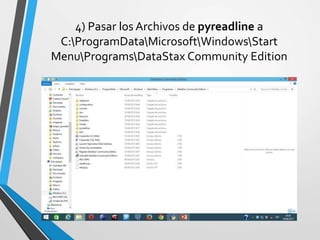
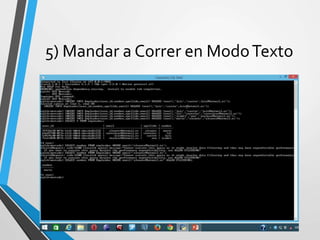
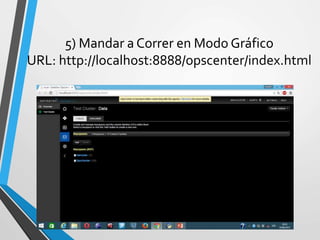

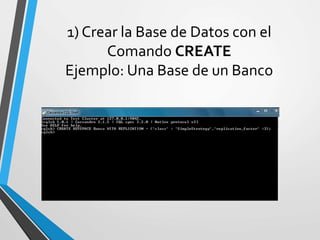

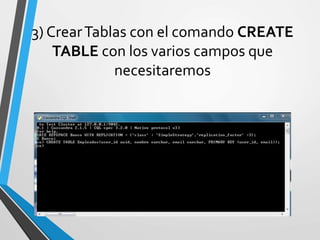
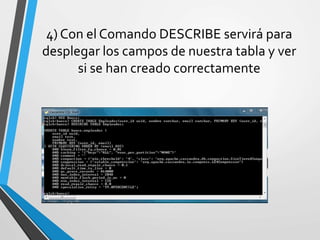

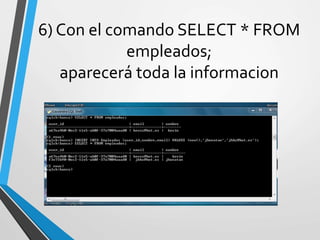

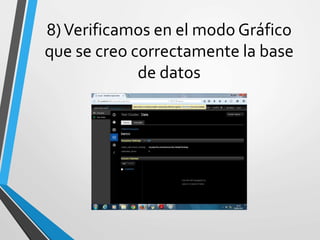


Este documento resume Apache Cassandra, una base de datos NoSQL distribuida y basada en clave-valor. Fue desarrollada originalmente por Facebook y liberada como código abierto en 2008. Desde entonces ha tenido varias versiones que han agregado funcionalidades como índices secundarios, lenguaje de consultas CQL y compatibilidad con SSD. Su objetivo principal es proporcionar escalabilidad lineal y alta disponibilidad distribuyendo datos entre nodos redundantes.


































































