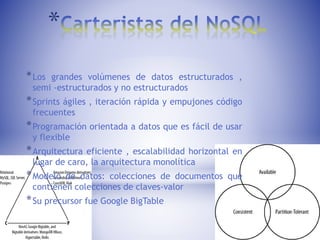
Cassandra es un sistema de gestión de base de datos distribuida de código abierto diseñado para manejar grandes cantidades de datos a través de muchos servidores de forma escalable y tolerante a fallos. Cassandra ofrece un modelo de datos de almacenamiento de filas particionadas con consistencia ajustable y soporte para replicación asíncrona entre centros de datos. Cassandra enfatiza la desnormalización a través de características como colecciones y no admite subconsultas u ordenamiento de resultados.