Descargado 457 veces



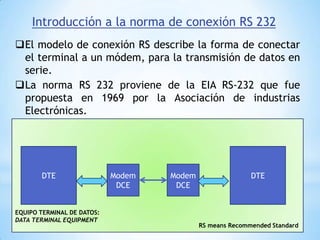
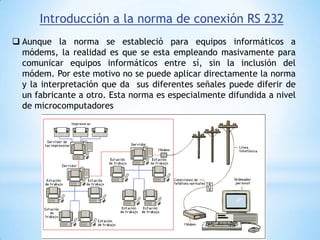
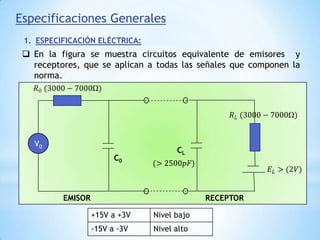

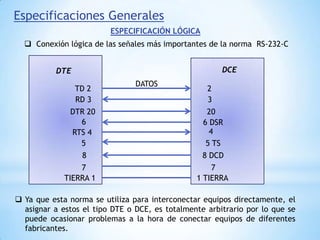
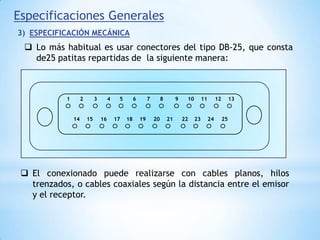
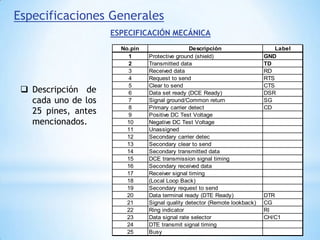
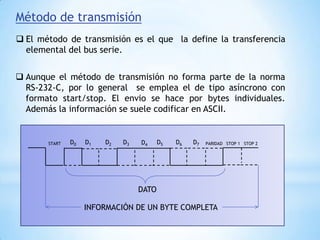







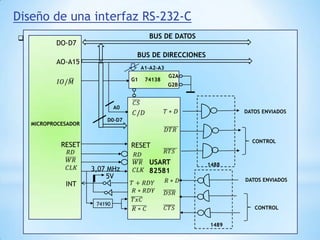







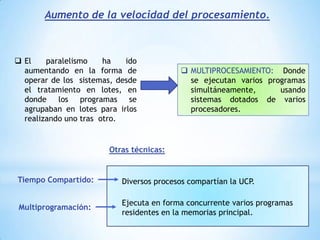
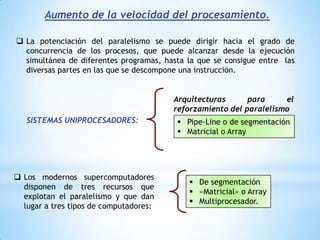

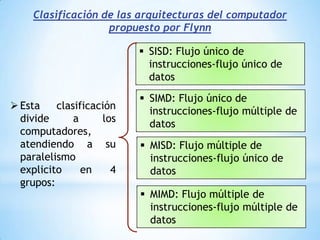
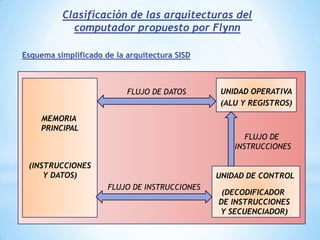


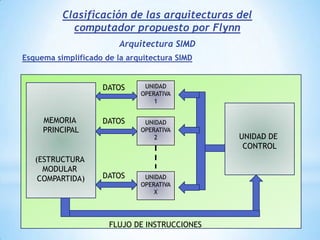

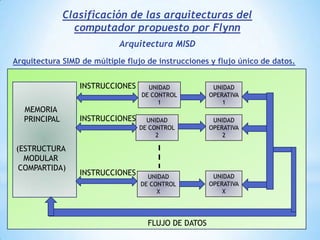
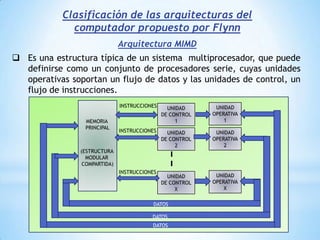





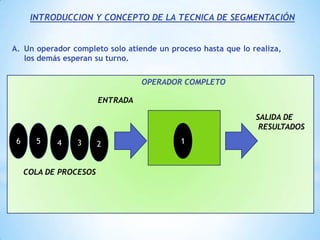
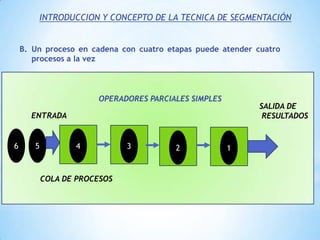

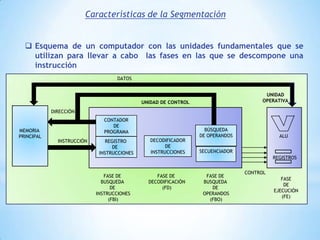
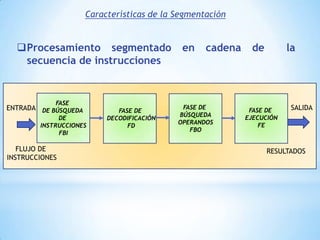

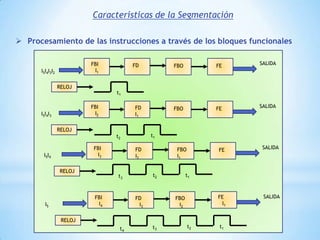



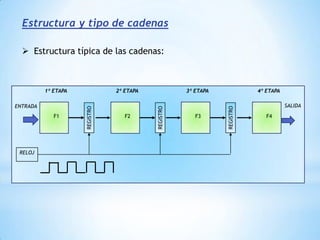
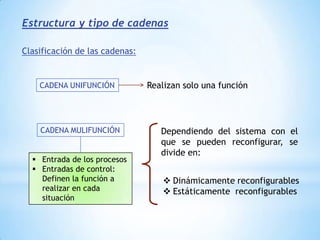

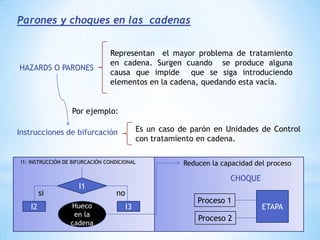


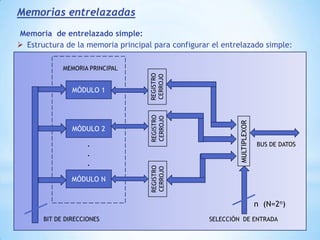
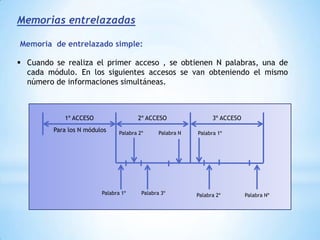


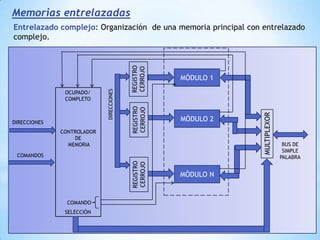




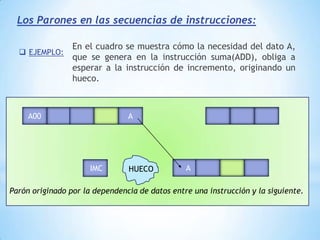
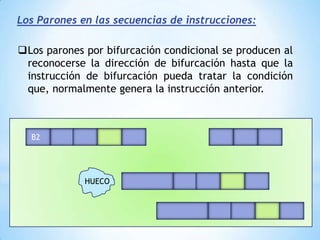










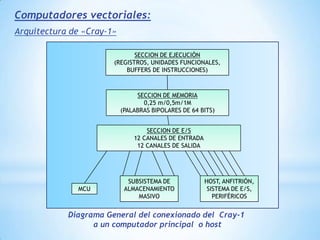

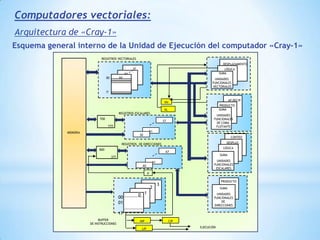






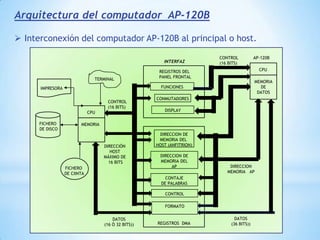
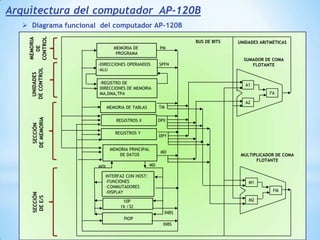



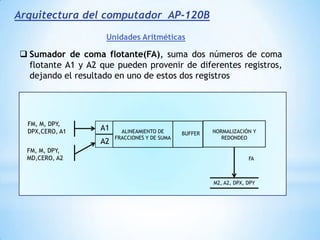
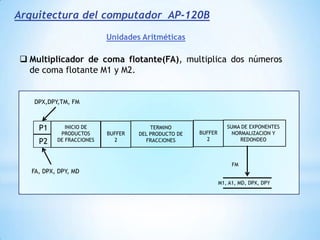



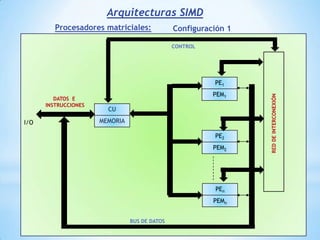
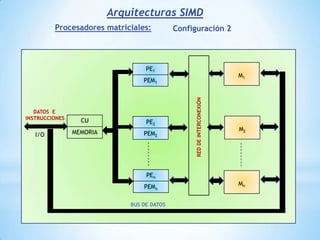


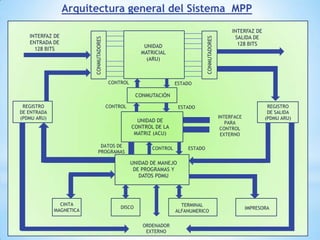



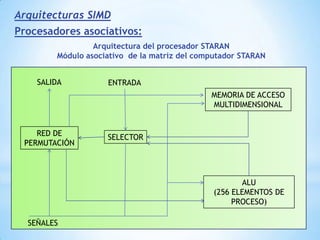

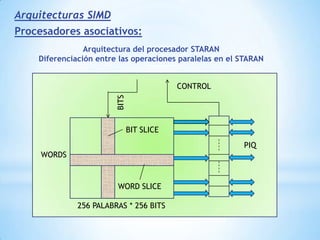
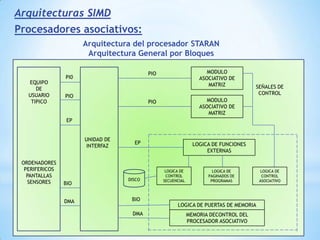



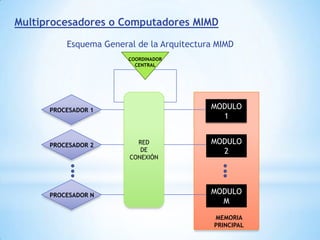


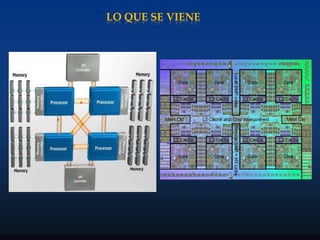

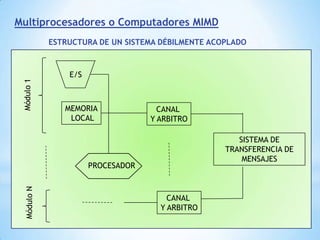
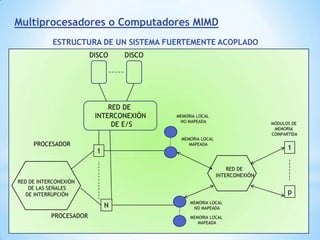

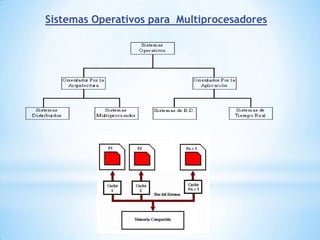
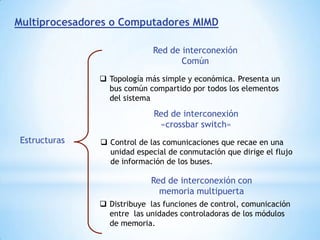
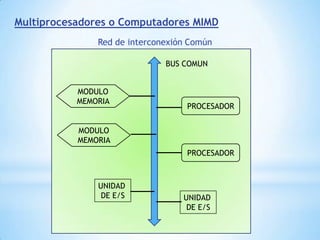
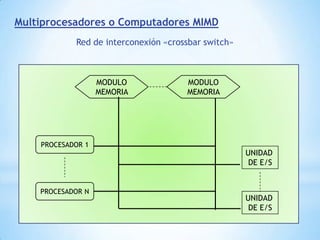
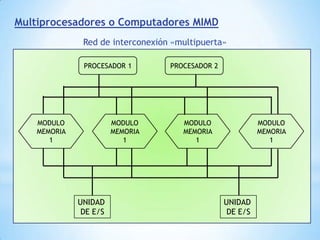

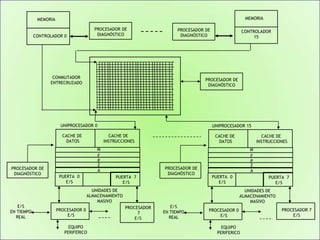
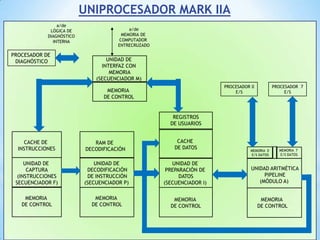
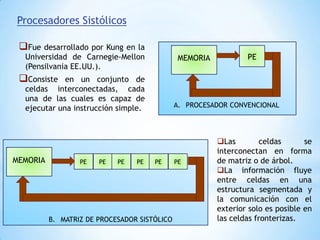
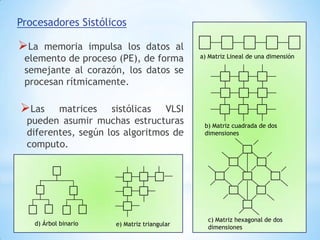






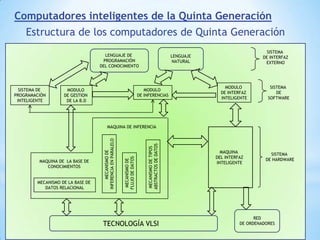

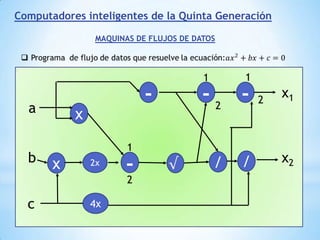
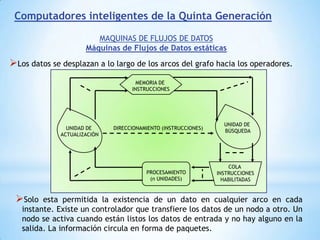
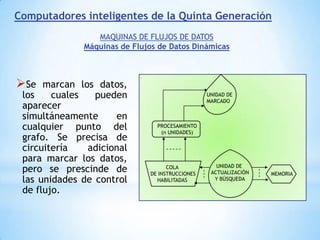










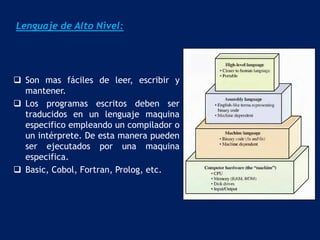
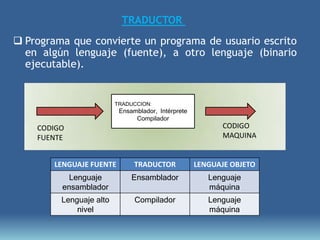



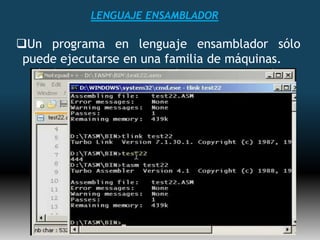

























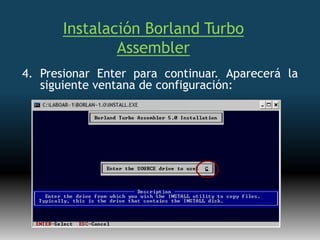
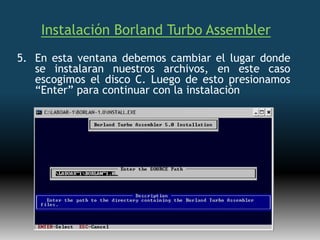
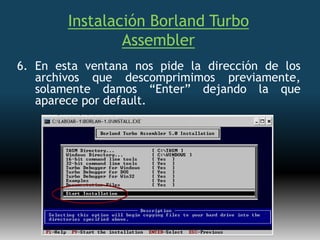
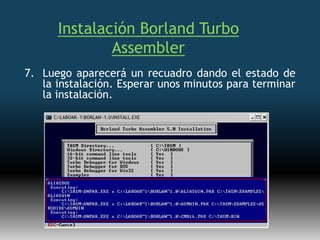






















Este documento describe formas de aumentar la velocidad y el paralelismo en computadores de alto rendimiento. Menciona que el procesamiento paralelo es necesario para aplicaciones que requieren grandes cantidades de datos, como procesamiento de imágenes en tiempo real. Luego detalla algunas estrategias como usar tecnologías más rápidas, reducir los niveles de puertas lógicas, aumentar la complejidad de circuitos combinatorios, mejorar el diseño de memorias y sustituir parte del sistema lógico por hardware dedicado.





























































![Puertoserial[1]](https://cdn.slidesharecdn.com/ss_thumbnails/puertoserial1-121008094445-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





