






















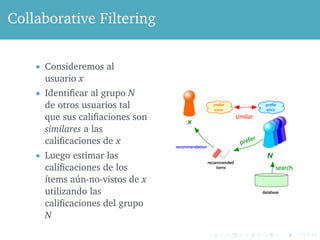










El documento aborda los sistemas de recomendación, una disciplina del data mining enfocada en sugerir productos o contenidos a usuarios basándose en sus intereses y calificaciones previas. Se explican diferentes tipos de sistemas, como los basados en contenido, filtrado colaborativo y sistemas híbridos, además de mencionar el concurso Netflix Prize como un caso relevante en la mejora de algoritmos de recomendación. También se discuten las ventajas y desventajas de cada enfoque y se presentan ejemplos de aplicaciones en múltiples dominios.




































