Descargar como PDF, PPTX

















































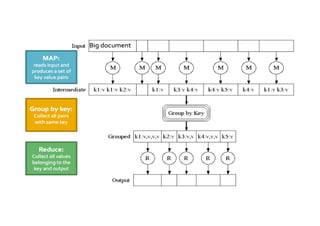








El documento aborda conceptos clave sobre data mining y big data, destacando la importancia de entender la diferencia entre correlación y causalidad, así como los límites estadísticos en el análisis de grandes volúmenes de datos. Se discuten las características de big data, incluyendo su volumen, velocidad, variedad y veracidad, así como la disciplina de la ciencia de datos y el papel fundamental de los data scientists. También se examinan casos de uso de big data en diversas áreas, como gestión de riesgo, análisis de sentiment, y personalización del cliente.





























































