Descargar para leer sin conexión



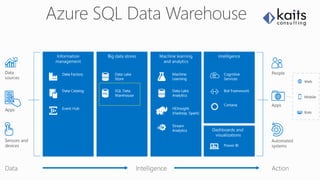

![Arquitectura de Azure SQL DW
Control
Node
Compute
Node
Compute
Node
Compute
Node
Compute
Node
SQL
DB
SQL
DB
SQL
DB
SQL
DB
Blob storage [WASB(S)]
Massively Parallel
Processing (MPP) Engine
Azure Infrastructure and
Storage
HDInsight
DMS
DMS DMS DMS DMS](https://image.slidesharecdn.com/azuredw-170531225306/85/Explorando-los-Sabores-con-Azure-DW-7-320.jpg)









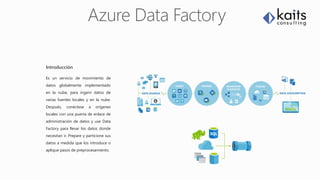





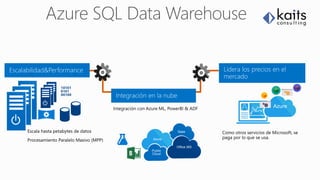
Este documento presenta una introducción a los servicios de Azure SQL Data Warehouse, incluyendo Polybase para acceder a datos relacionales y no relacionales usando T-SQL, Azure Data Factory para mover datos entre fuentes locales y en la nube, e Integration Services para realizar procesos ETL. También describe la arquitectura de Azure SQL DW y características como la escalabilidad, almacenamiento de datos, índices columnstore y limitaciones.













































![[Code Camp 2009] Cloud Computing - Explorando Windows Azure Services (Carlos ...](https://cdn.slidesharecdn.com/ss_thumbnails/codecamp2009cloudcomputing-explorandowindowsazureservicescarlospeixjosmarianolvarez-100119112422-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































