Descargar como PDF, PPTX


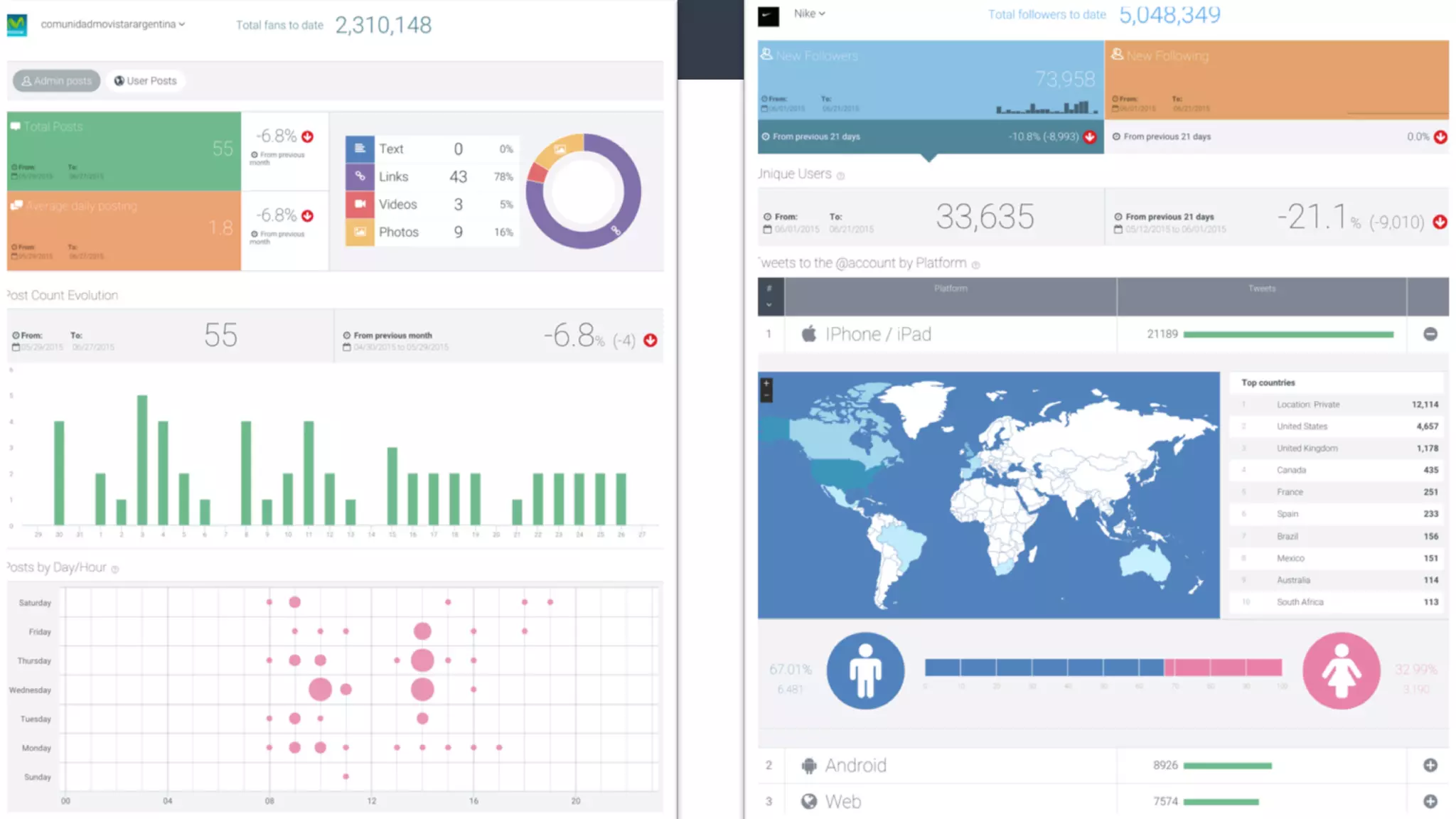
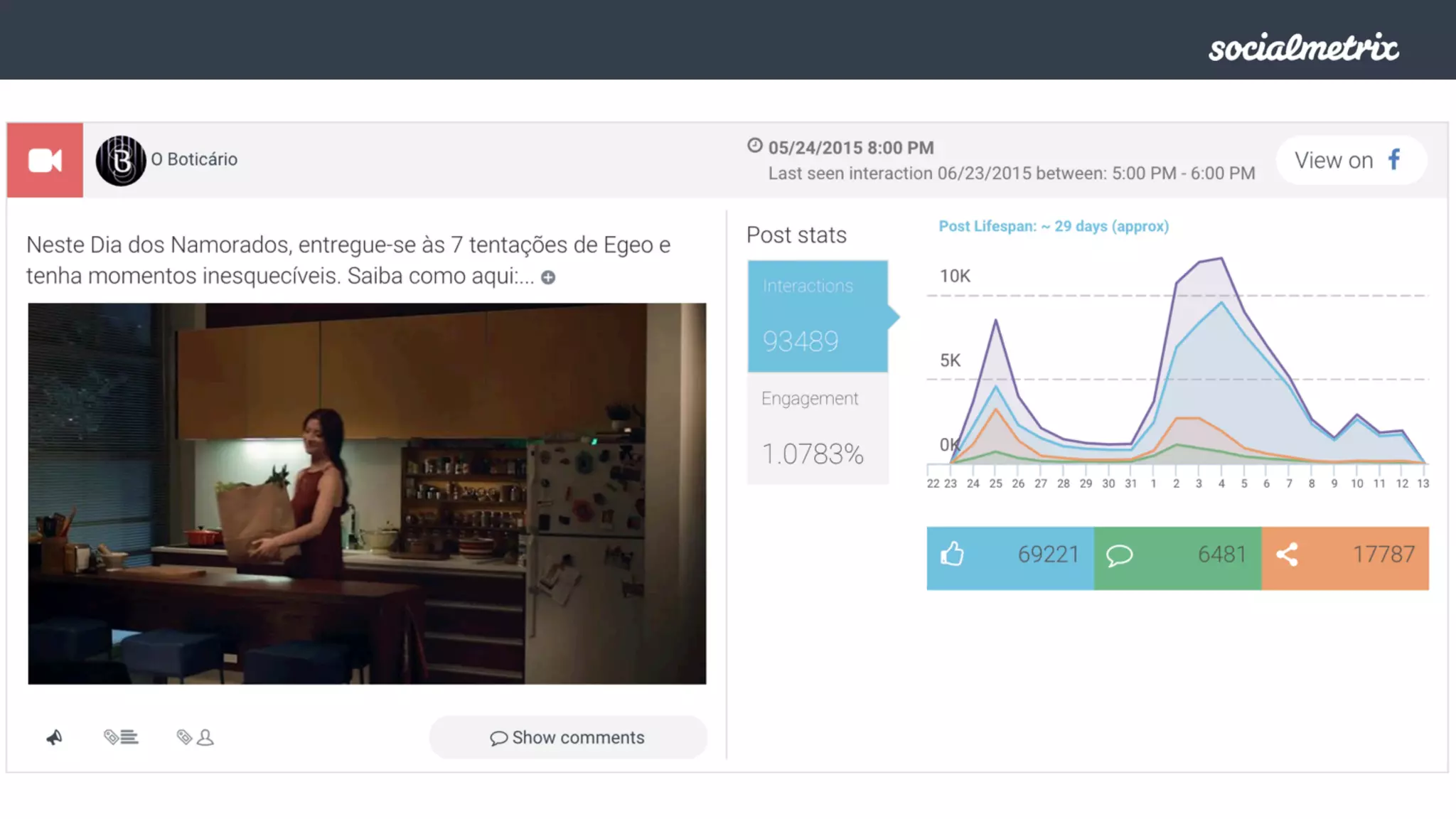



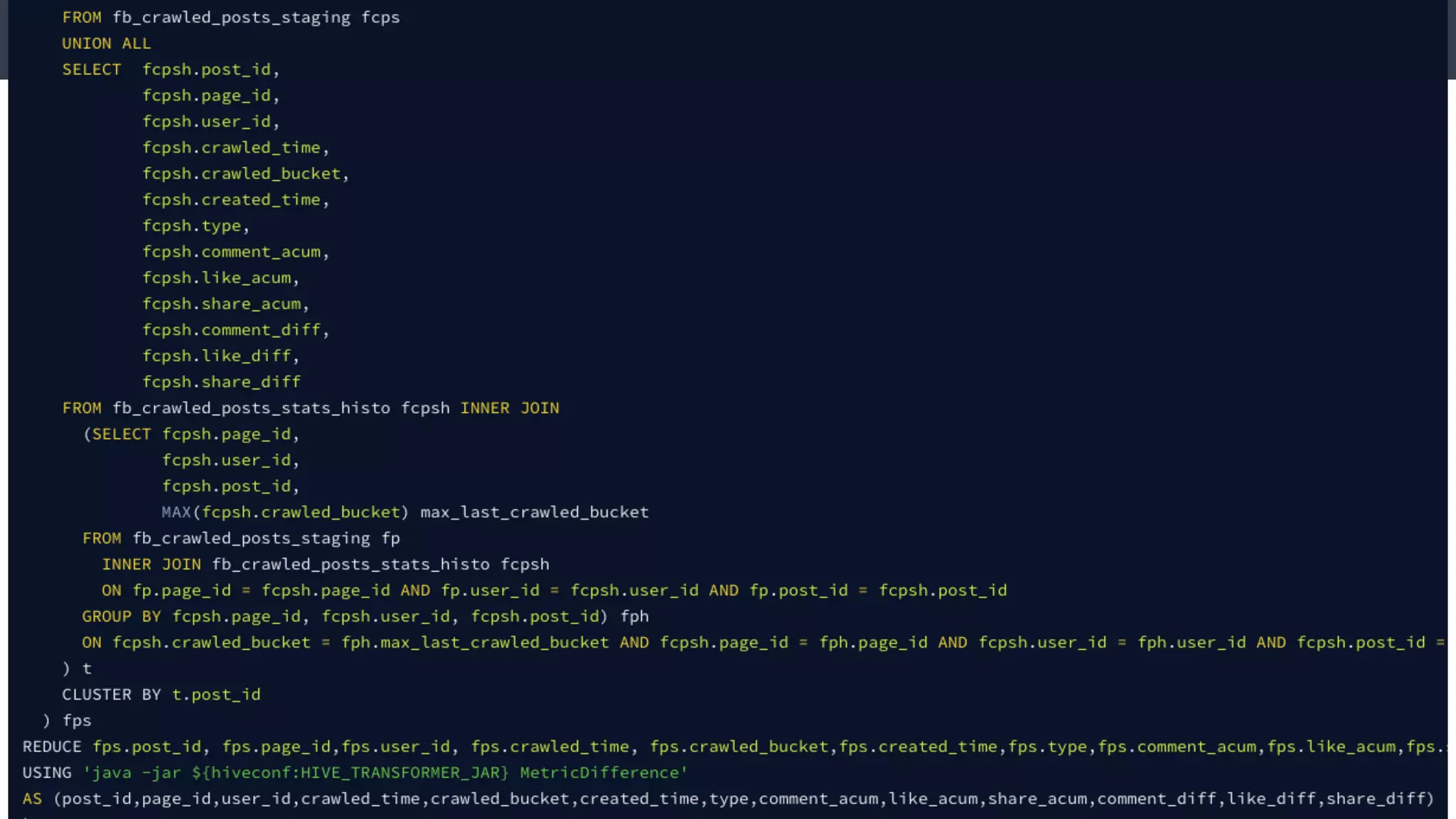







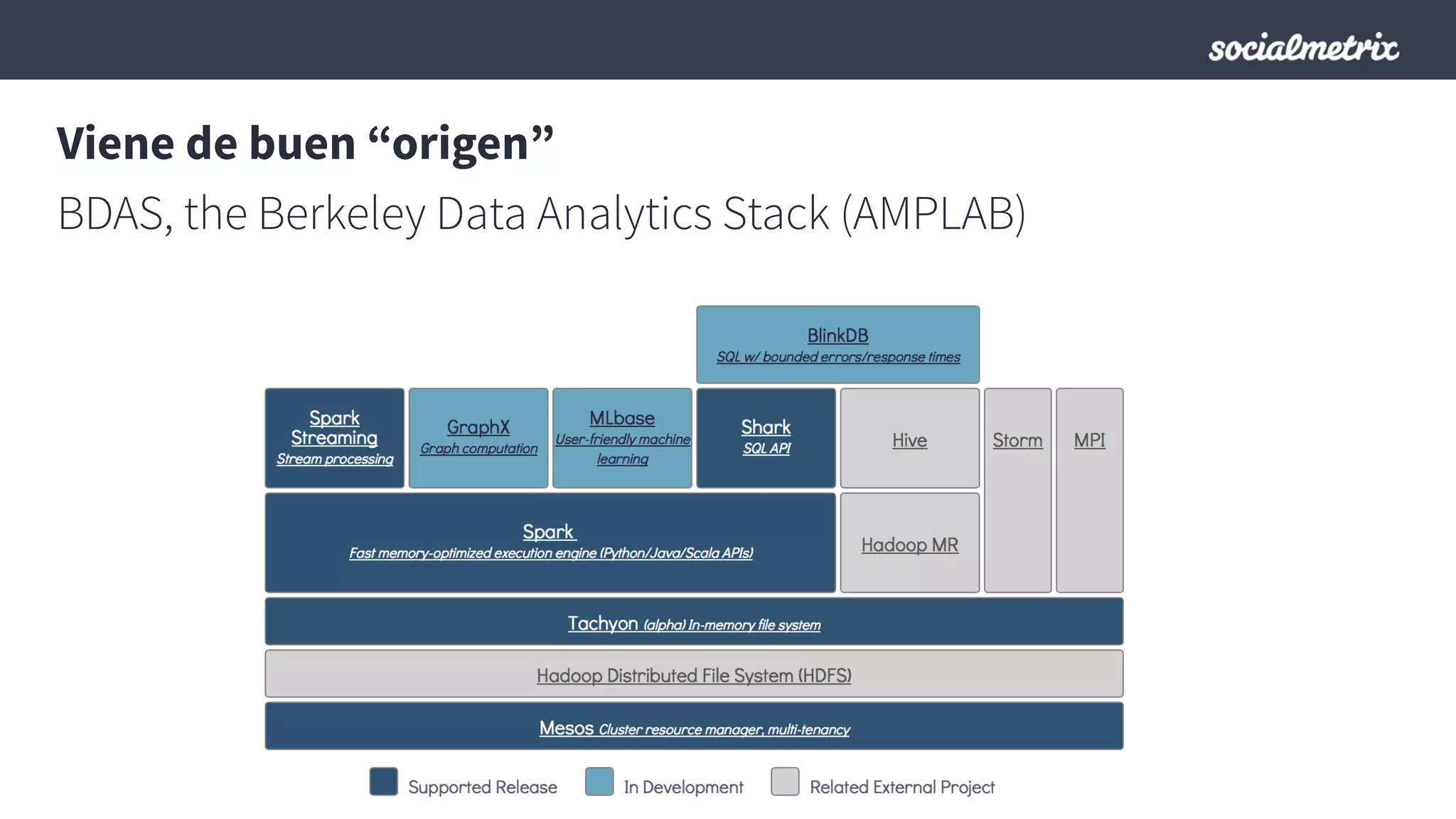
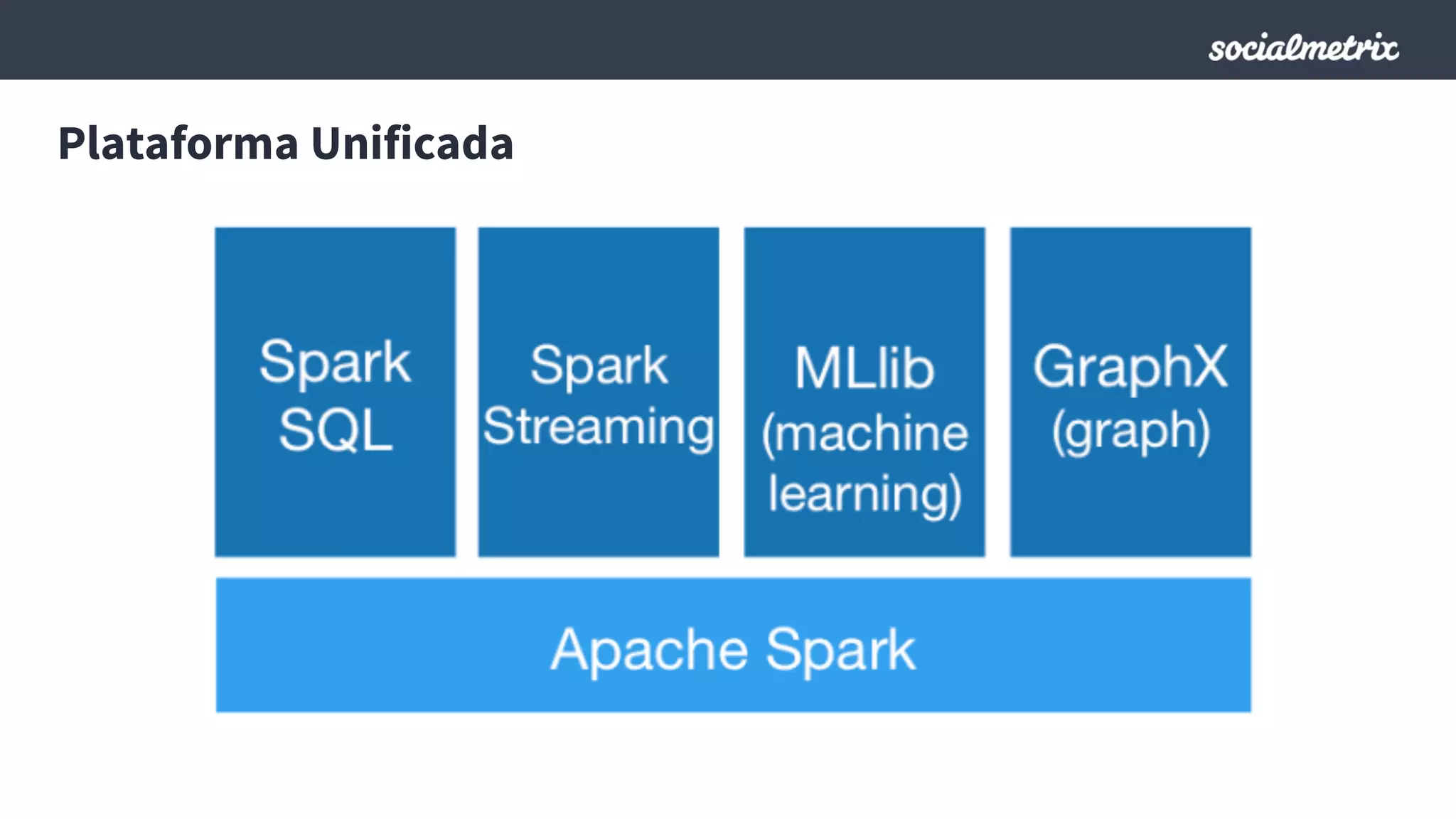

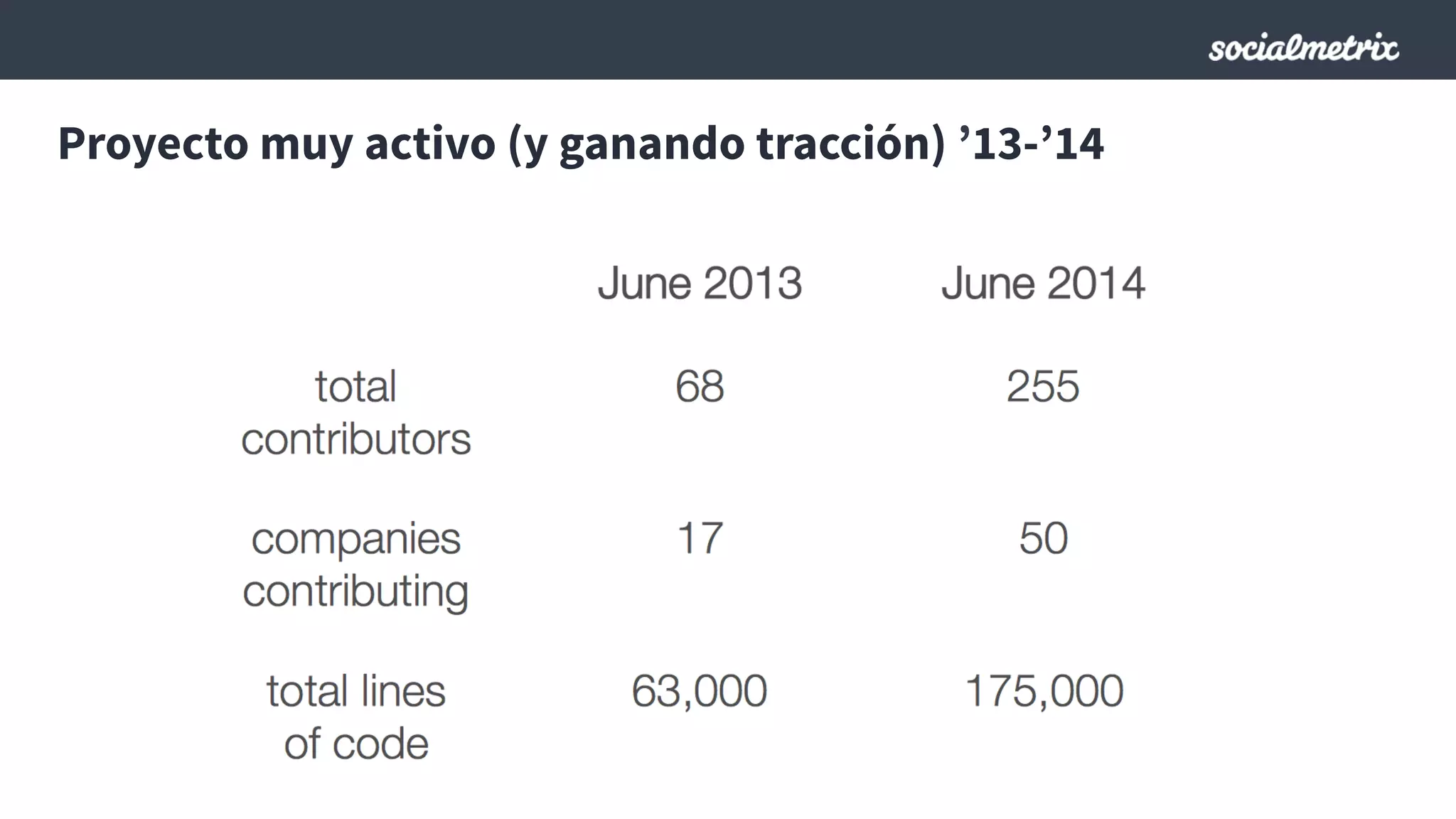
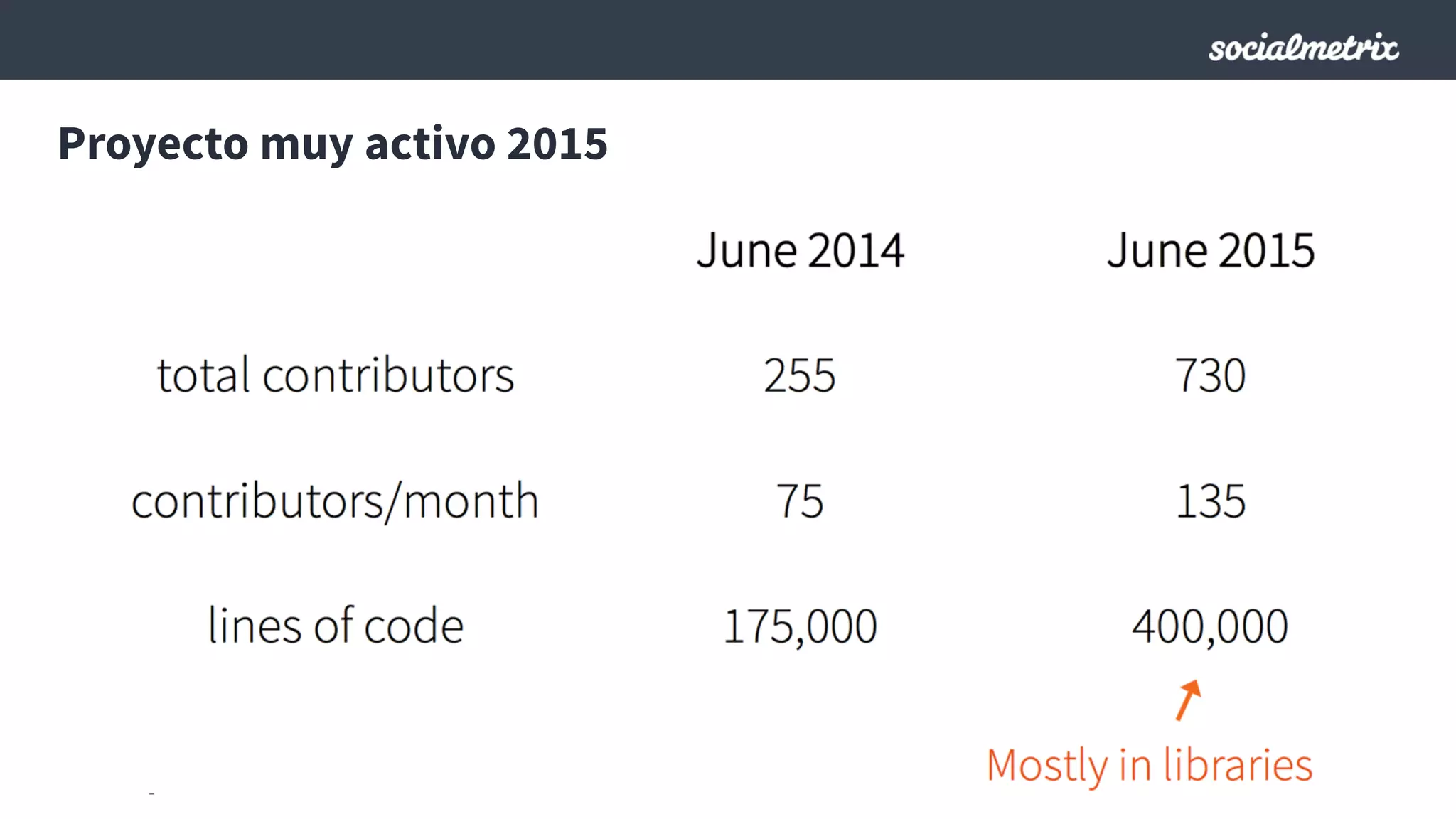
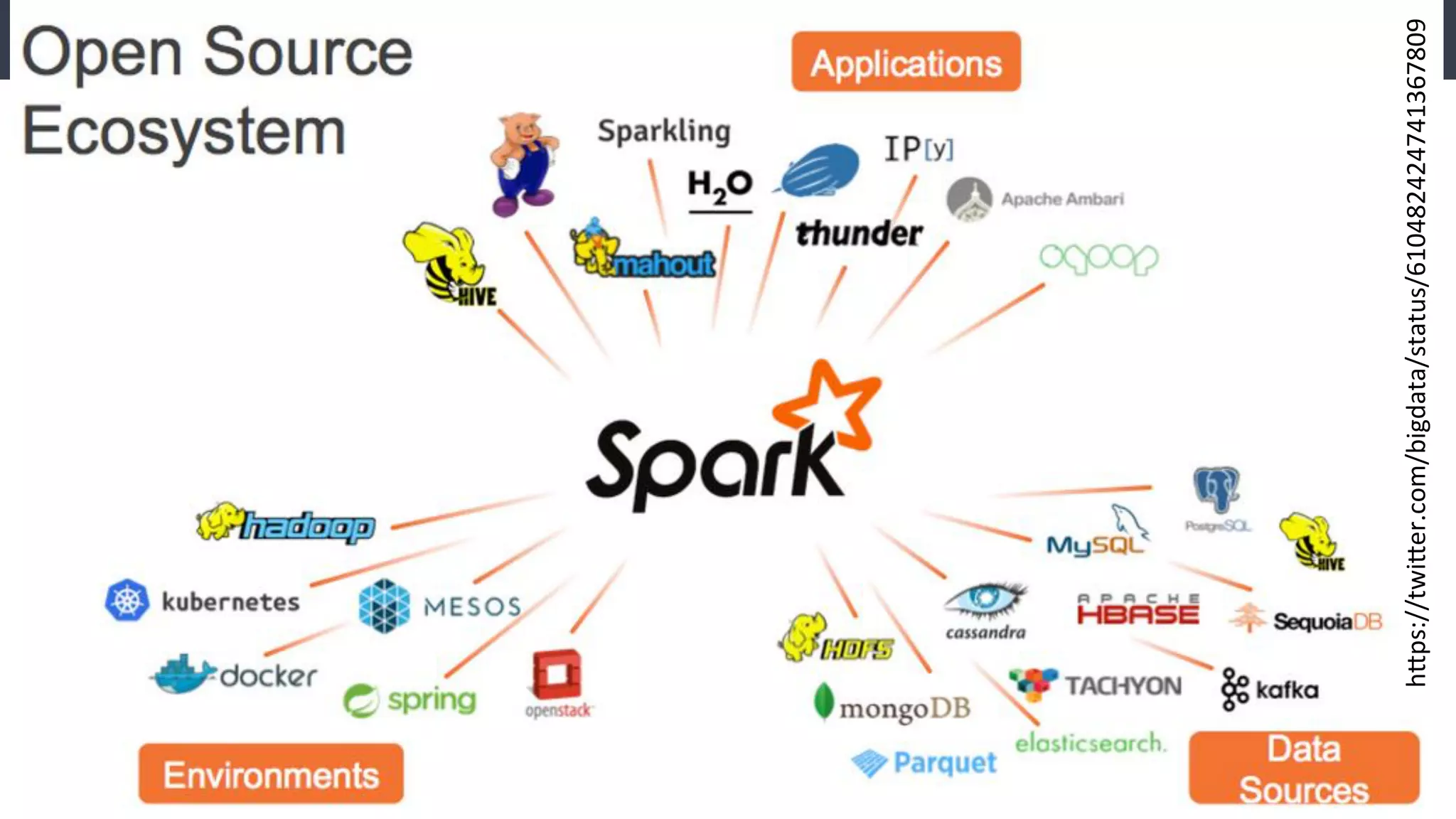
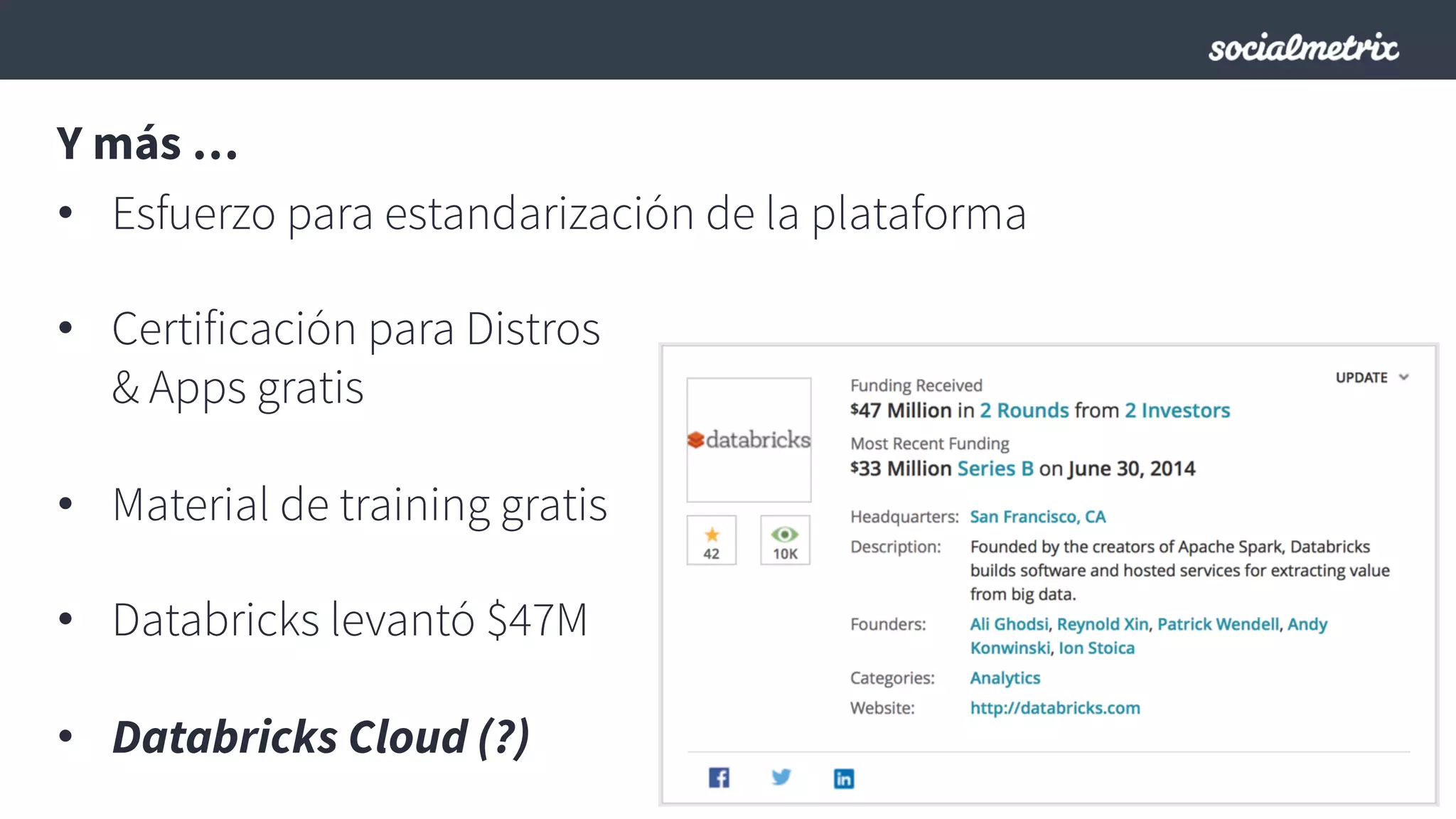

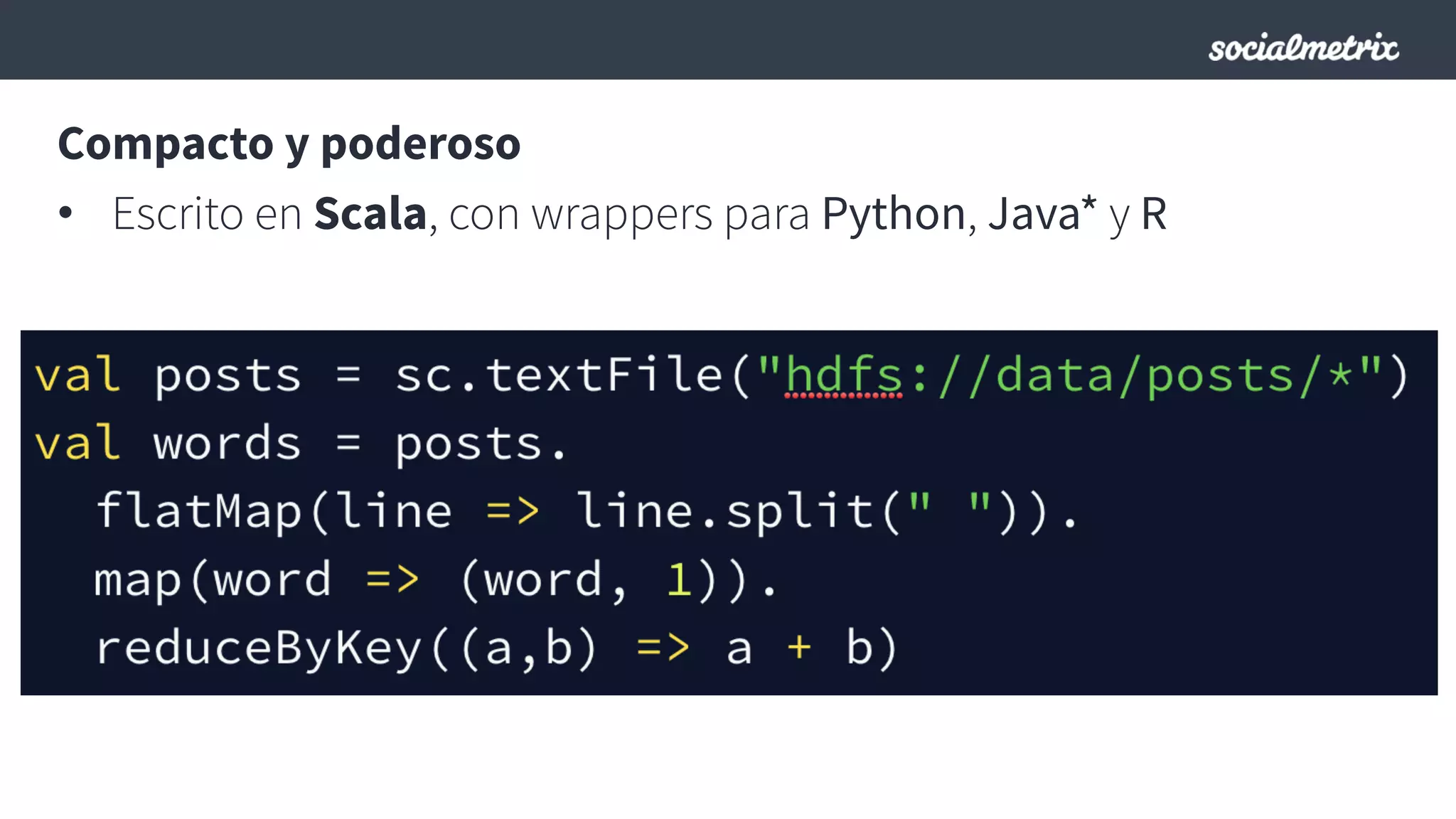

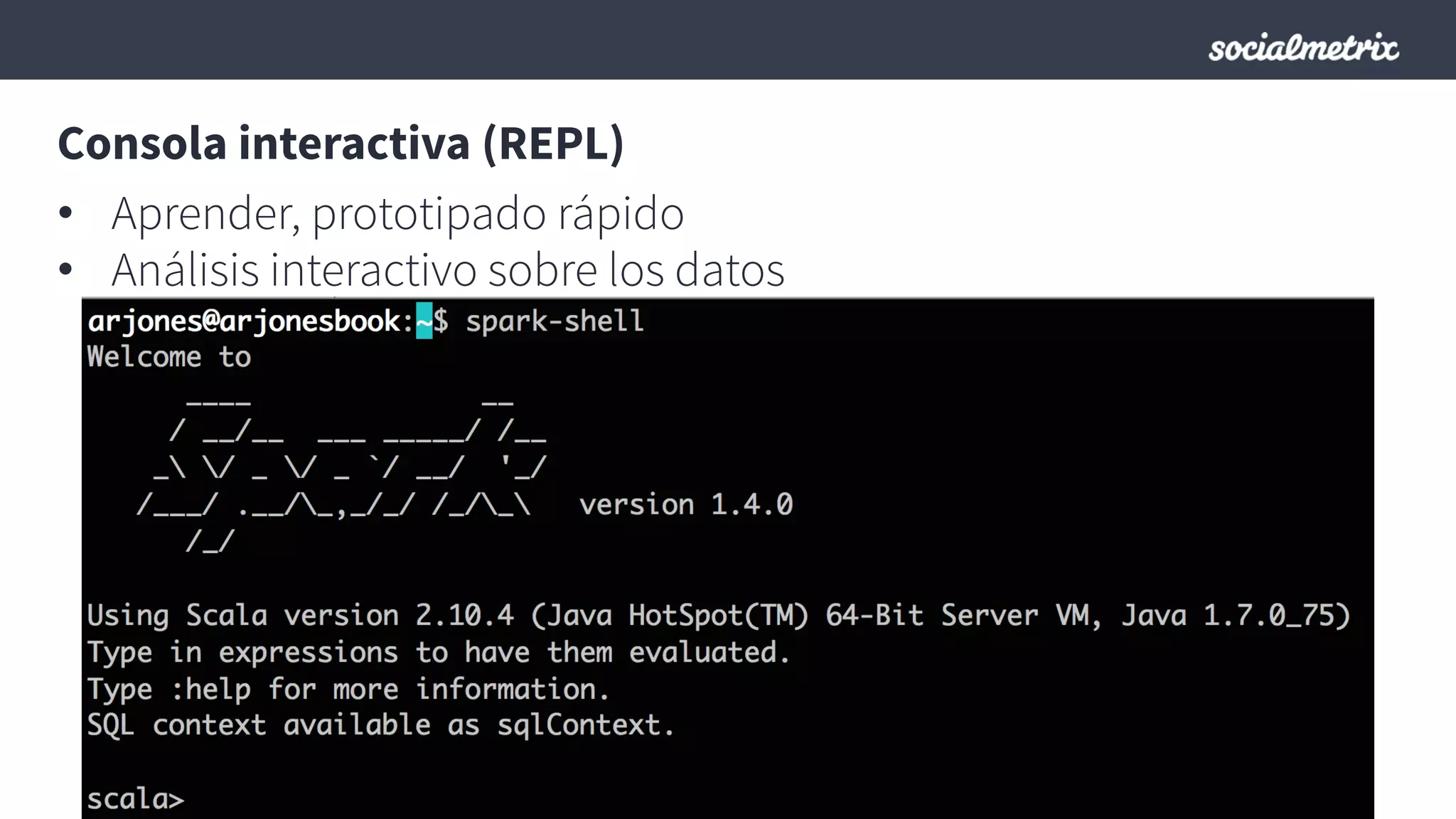

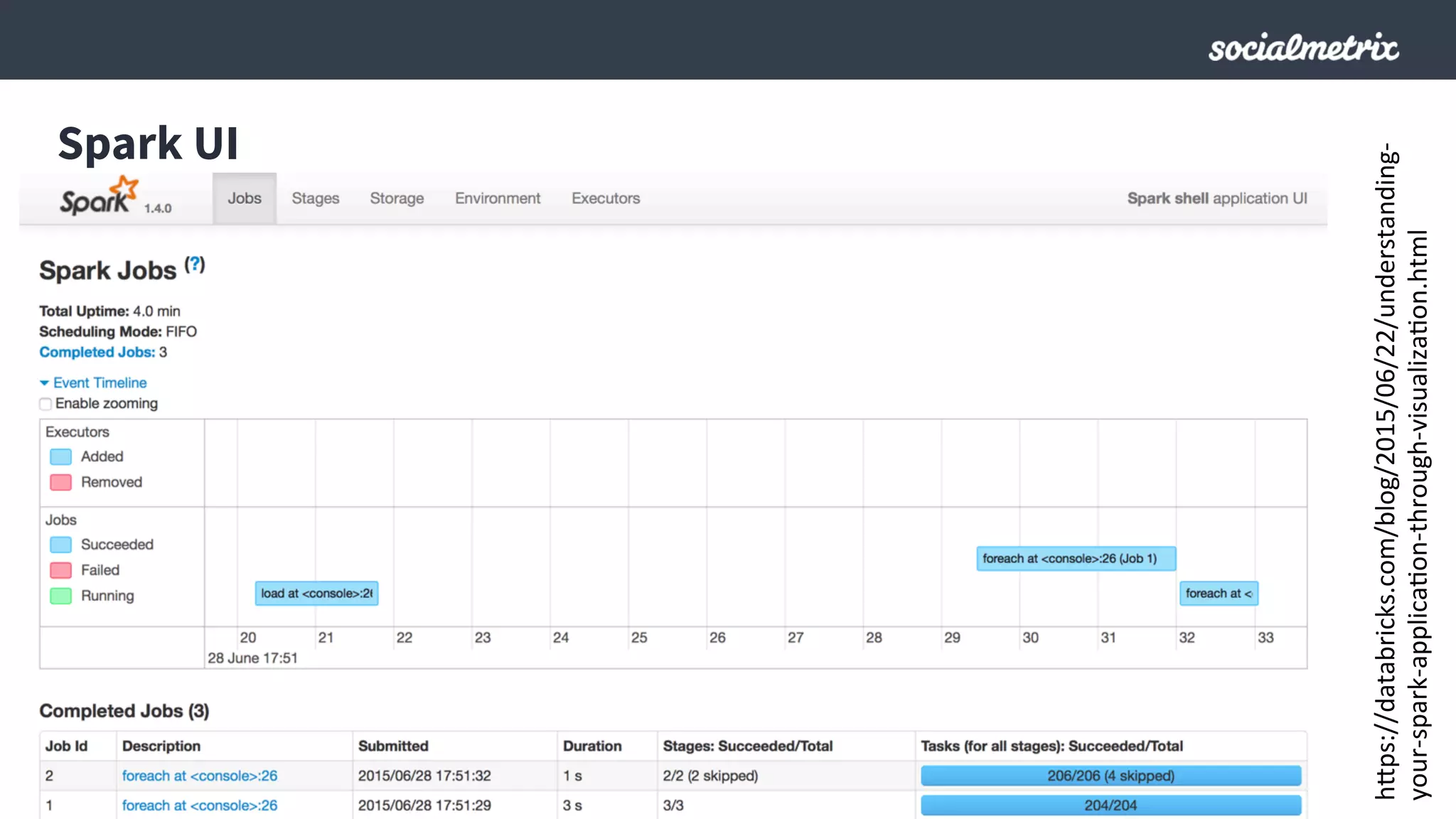

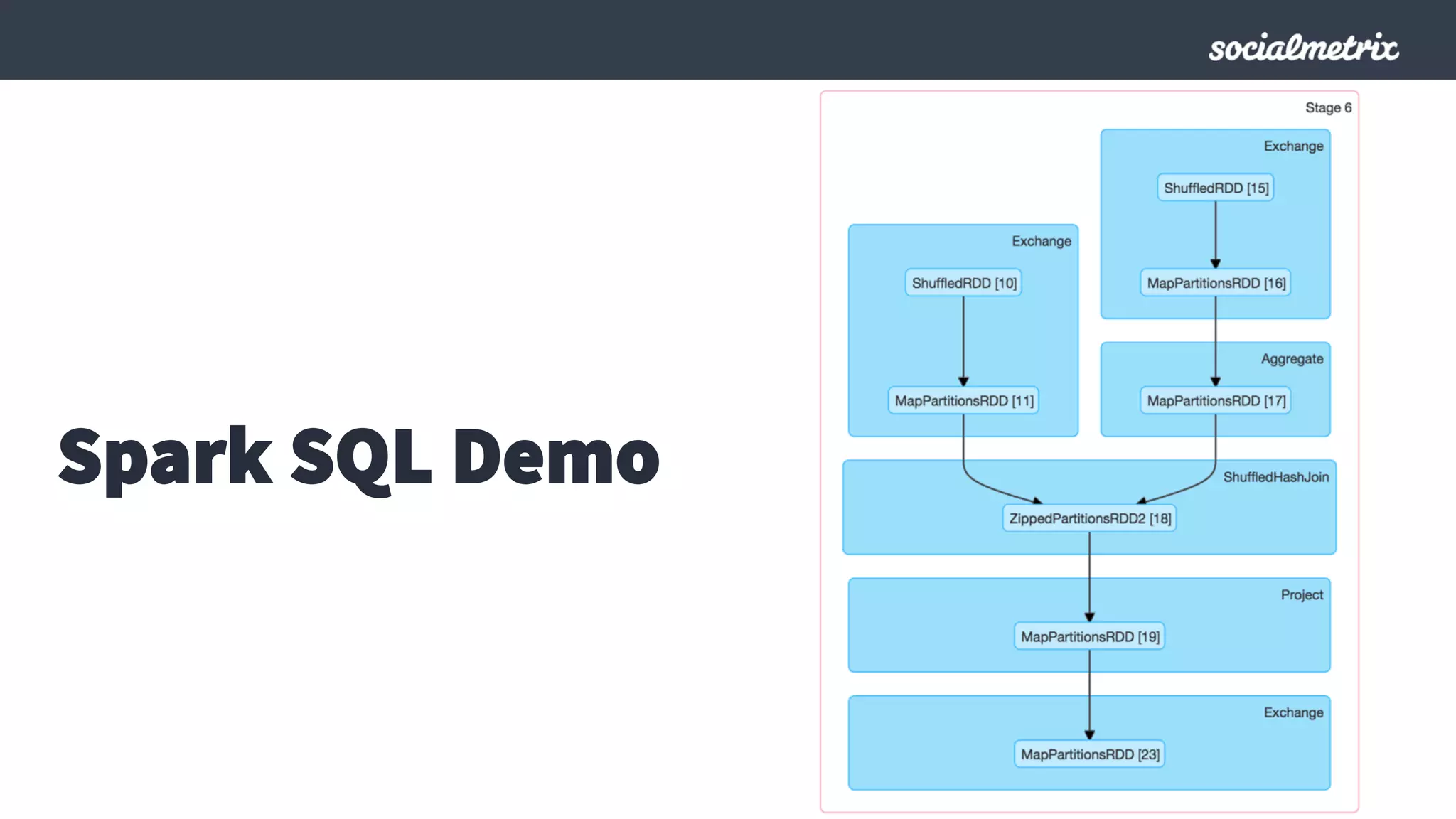
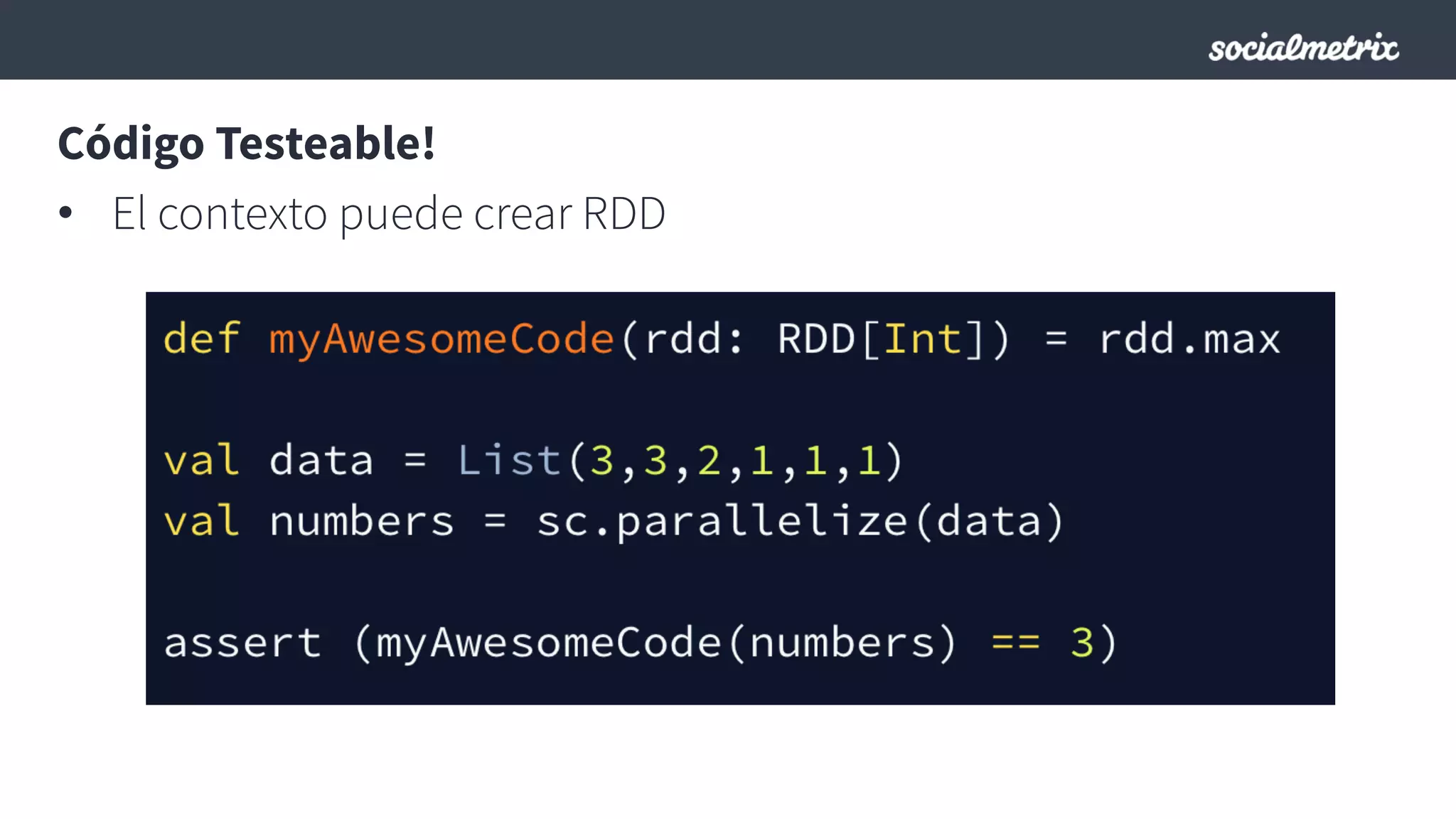

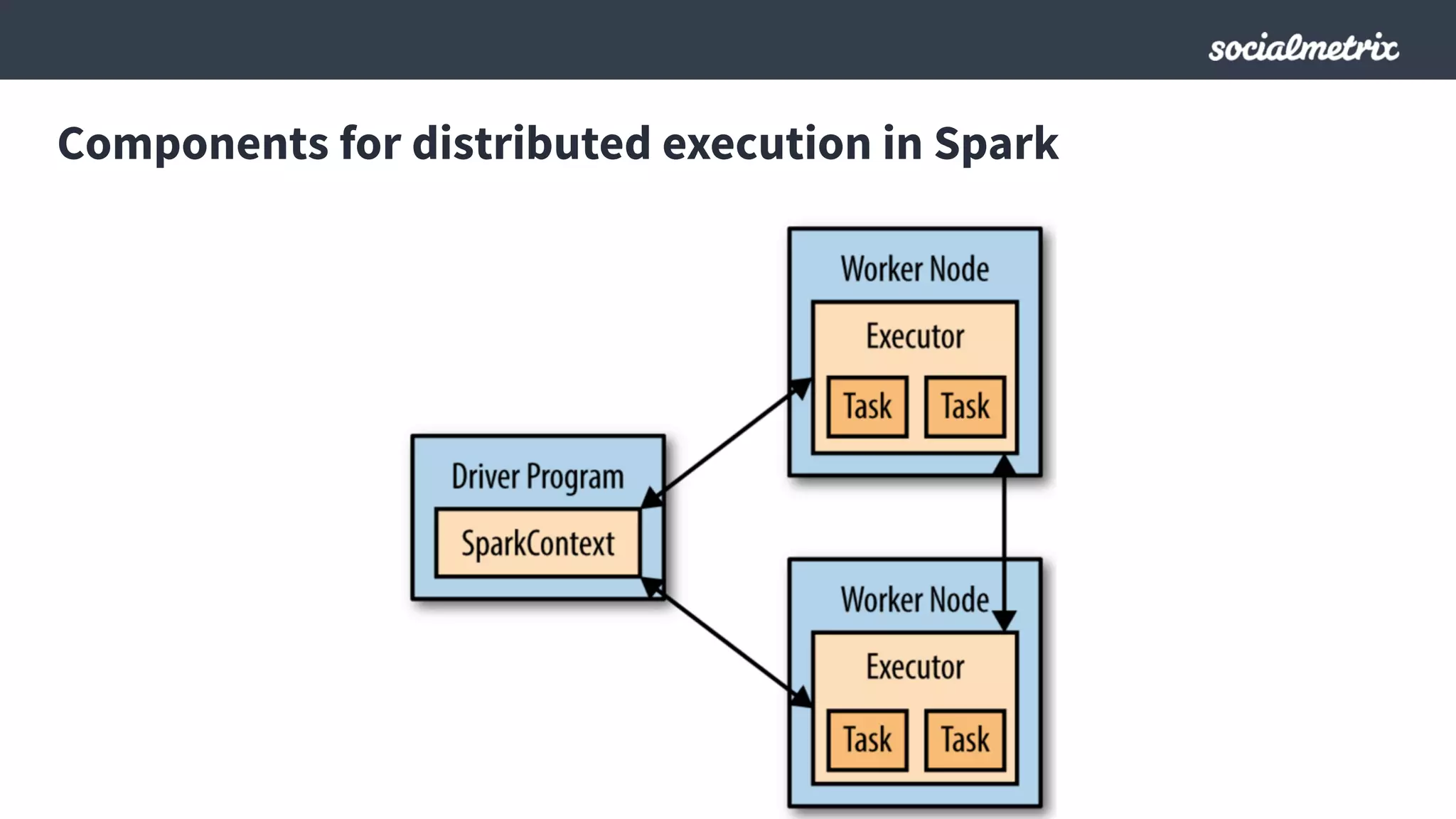

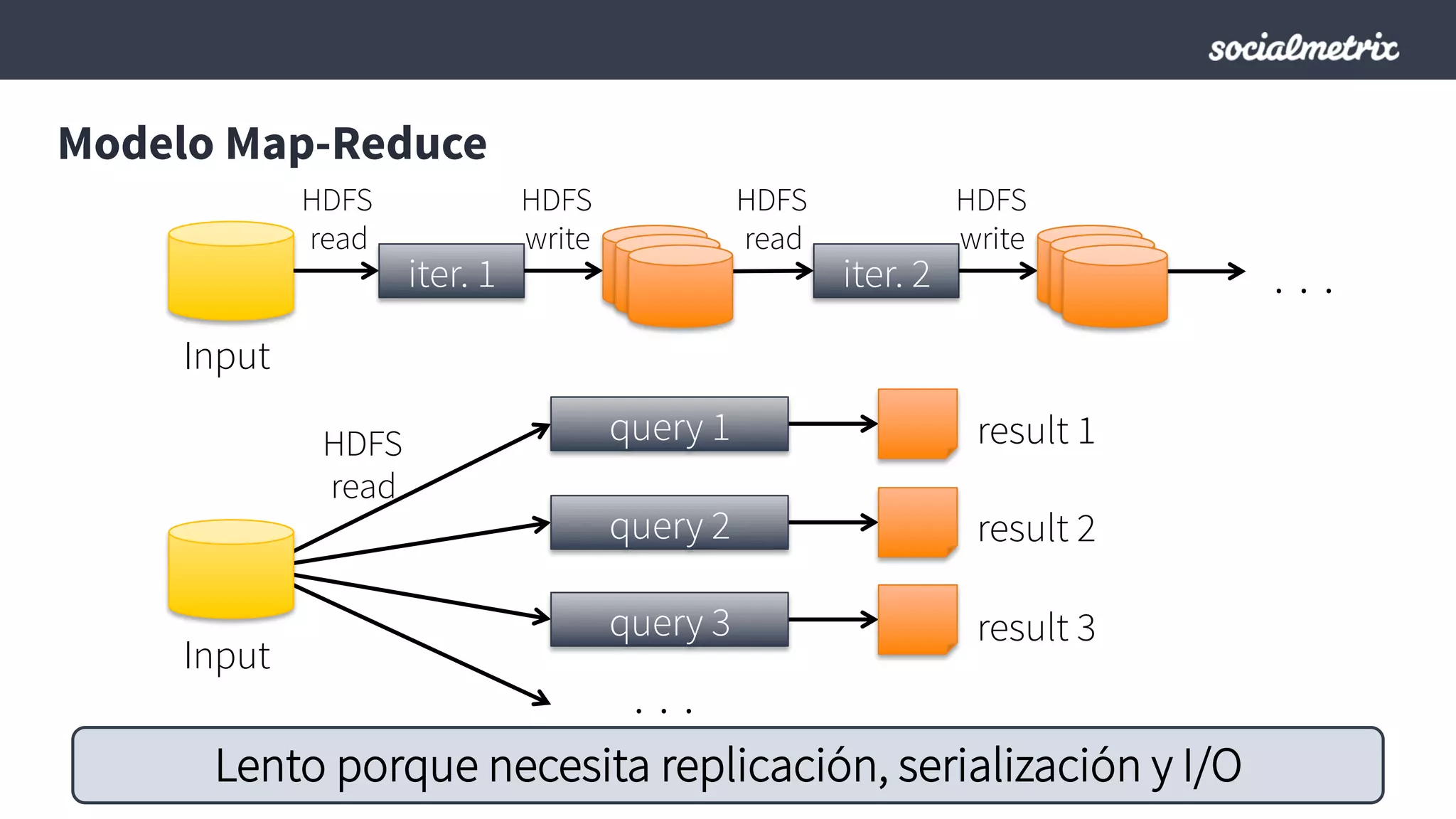
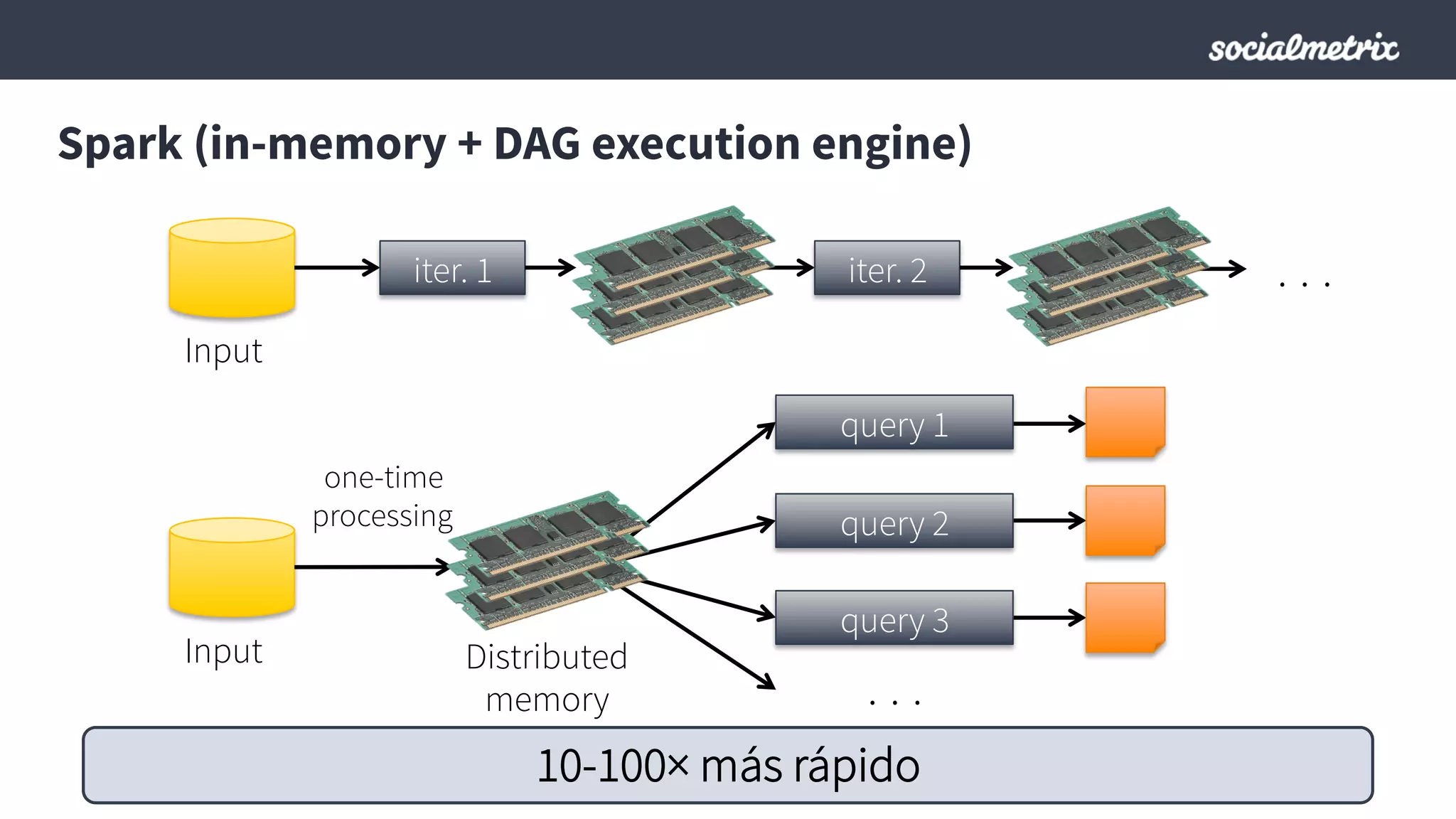
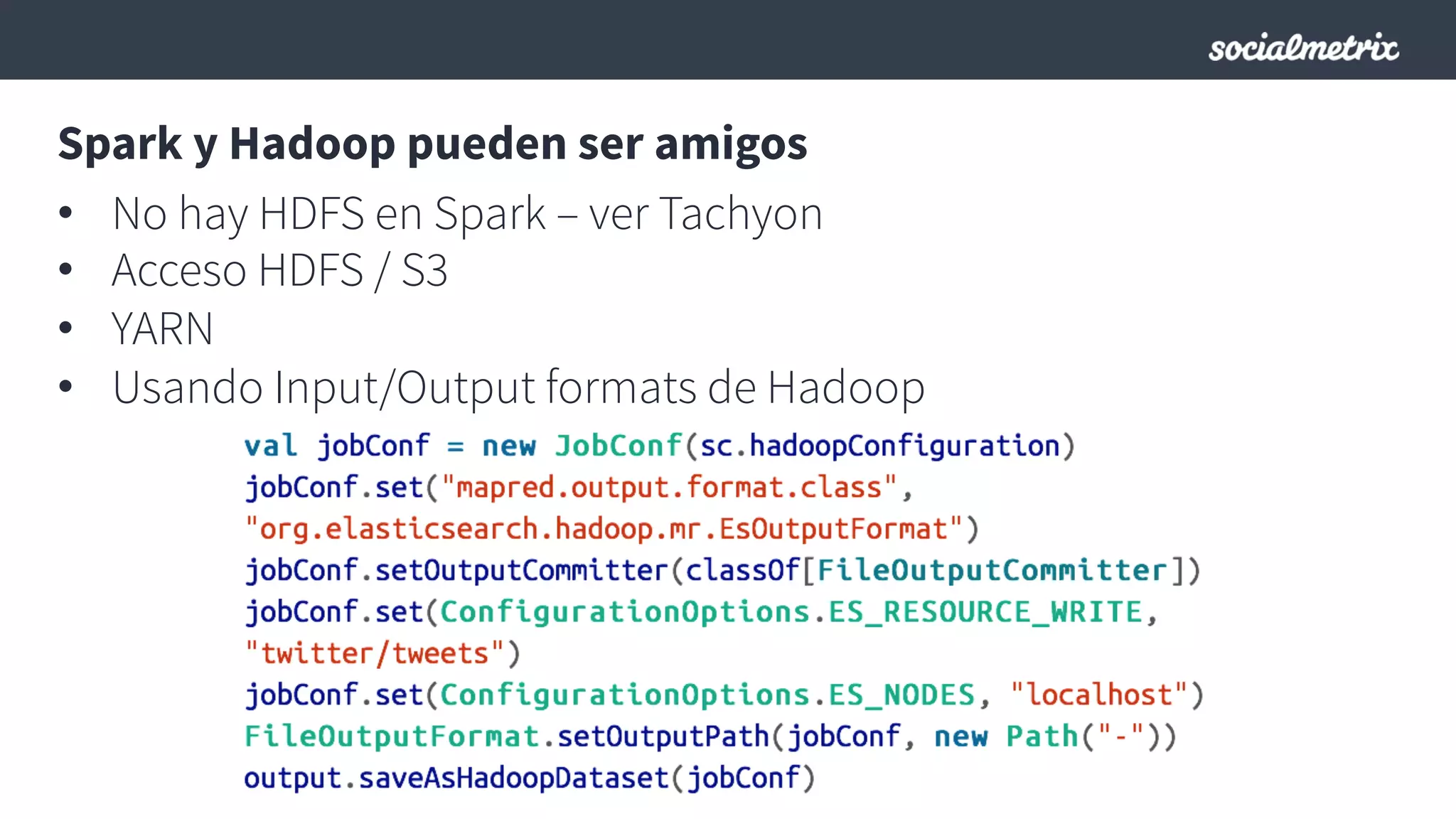







Este documento compara Hadoop y Spark, argumentando que Spark es una mejor opción debido a su capacidad de procesamiento de datos in-memory, su interfaz más expresiva y su naturaleza de plataforma unificada que permite procesamiento por lotes y en tiempo real con un solo código. El documento también discute algunos desafíos de Spark como trabajos largos y problemas de serialización.




























































