Descargado 17 veces






















































![62
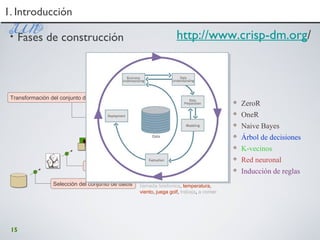
• Classify news stories as World, US, Business, SciTech, Sports,
Entertainment, Health, Other
• Add MeSH terms to Medline abstracts
• e.g.“Conscious Sedation” [E03.250]
• Classify business names by industry.
• Classify student essays as A,B,C,D, or F.
• Classify email as Spam, Other.
• Classify email to tech staff as Mac,Windows, ..., Other.
• Classify pdf files as ResearchPaper, Other
• Classify documents as WrittenByReagan, GhostWritten
• Classify movie reviews as Favorable,Unfavorable,Neutral.
• Classify technical papers as Interesting, Uninteresting.
1. Mineria de textos: requisitos1. Mineria de textos: requisitos](https://image.slidesharecdn.com/isummit-utpl-taller-101124154602-phpapp02/85/I-summit-utpl-taller-61-320.jpg)





















![84
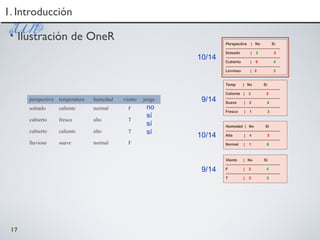
5. LSA con R5. LSA con R
> R = lsa(X, dims=dimcalc_share())> R (para ver
su contenido: $tk, $dk y $sk)
> U = R$tk> V = R$dk> S = R$sk
> Xmodif = as.textmatrix(R)
> cosine(Xmodif[,1], Xmodif[,2])>
cosine(Xmodif)](https://image.slidesharecdn.com/isummit-utpl-taller-101124154602-phpapp02/85/I-summit-utpl-taller-83-320.jpg)
![85
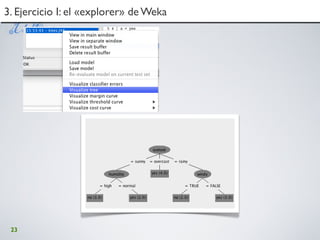
5.Visualización de LSA en R5.Visualización de LSA en R
read.csv("mots.csv", header=FALSE, sep=",")> mots
1], U[,2], col = "red")> textxy(U[,1], U[,2], t(mots), cx=0.5, d
1], V[,2], col = "blue")> textxy(V[,1], V[,2], 1:9, cx=0.5, dcol=](https://image.slidesharecdn.com/isummit-utpl-taller-101124154602-phpapp02/85/I-summit-utpl-taller-84-320.jpg)
![86
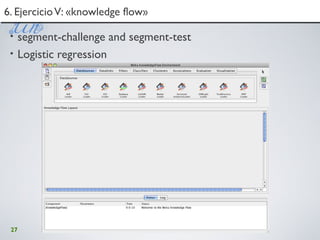
5.Visualización de LSA en R5.Visualización de LSA en R
U[,1], V[,1])> losY = append(U[,2], V[,2])> plot(losX, losY, co](https://image.slidesharecdn.com/isummit-utpl-taller-101124154602-phpapp02/85/I-summit-utpl-taller-85-320.jpg)










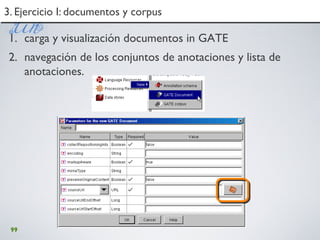



















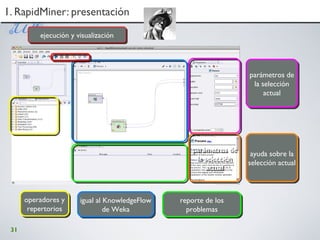
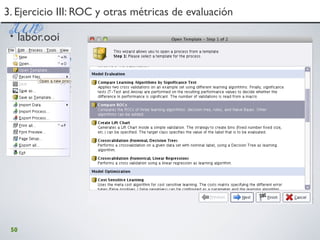
Este documento presenta un taller sobre minería de datos, textos y visualización que se llevará a cabo en 2010. El programa consta de cuatro partes que cubren herramientas como WEKA, RapidMiner, R y GATE. La primera parte se centra en WEKA y la minería de datos básica a través de ejercicios prácticos. La segunda parte explora RapidMiner y su interfaz visual. La tercera parte examina las posibilidades de R. La cuarta parte cubre el análisis de textos con GATE. El taller



































































