Descargado 337 veces



























Este documento presenta varias optimizaciones avanzadas para SQL Server, incluyendo configuraciones de NUMA, hilos, máscaras de afinidad de E/S, grado máximo de paralelismo y configuración de memoria. También cubre configuraciones avanzadas de base de datos como registros de transacciones, optimización de correlación de fecha y parametrización. Finalmente, presenta patrones para desarrolladores sobre el uso de parámetros de tabla y mejoras en el uso de funciones en SQL Server.
Presentación de Enrique Catala Bañuls, ingeniero informático y mentor en SolidQ. Experiencia con Microsoft y SQL Server.
Temas a tratar en la presentación: configuraciones avanzadas de SQL Server y bases de datos, patrones para desarrolladores.
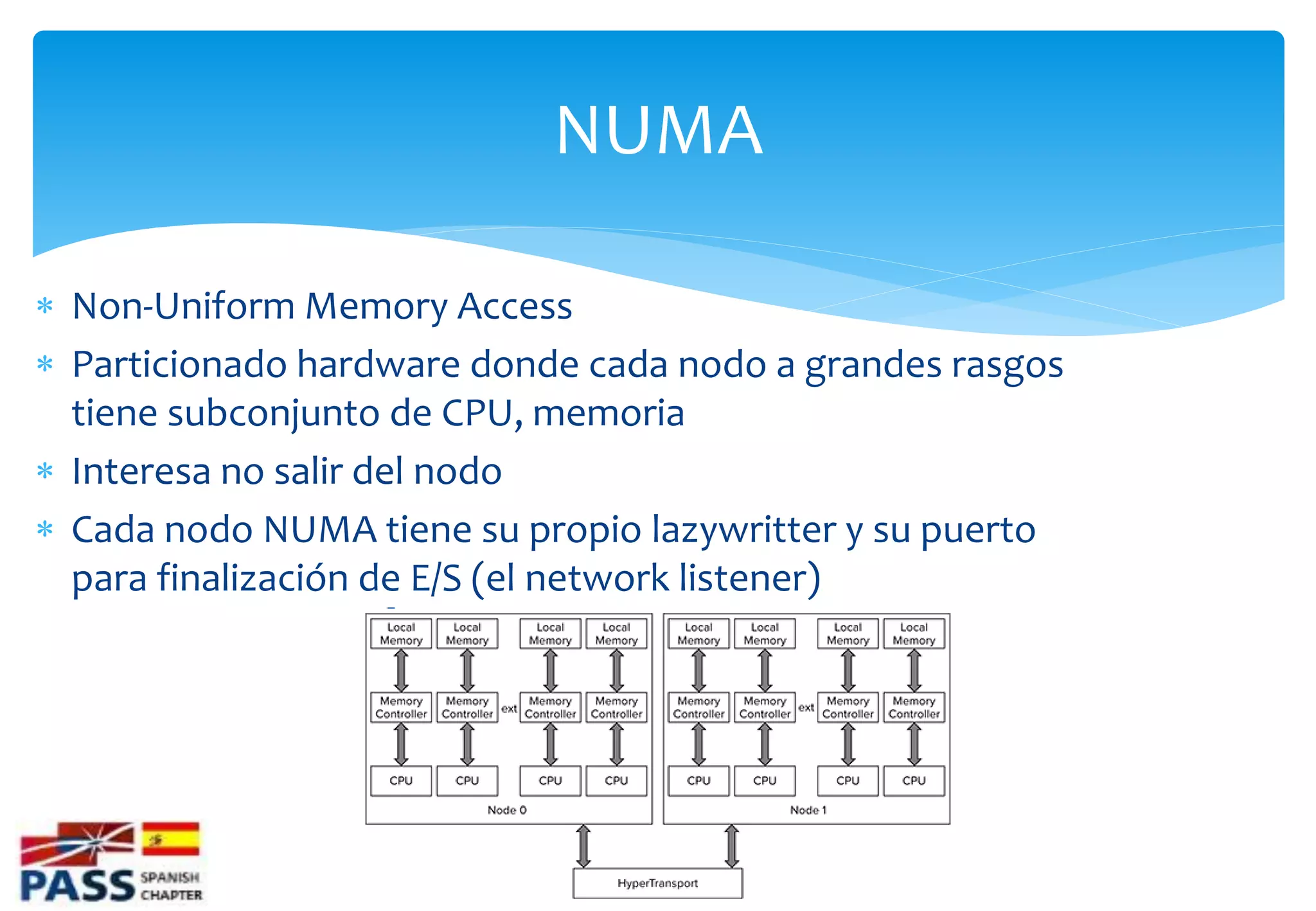
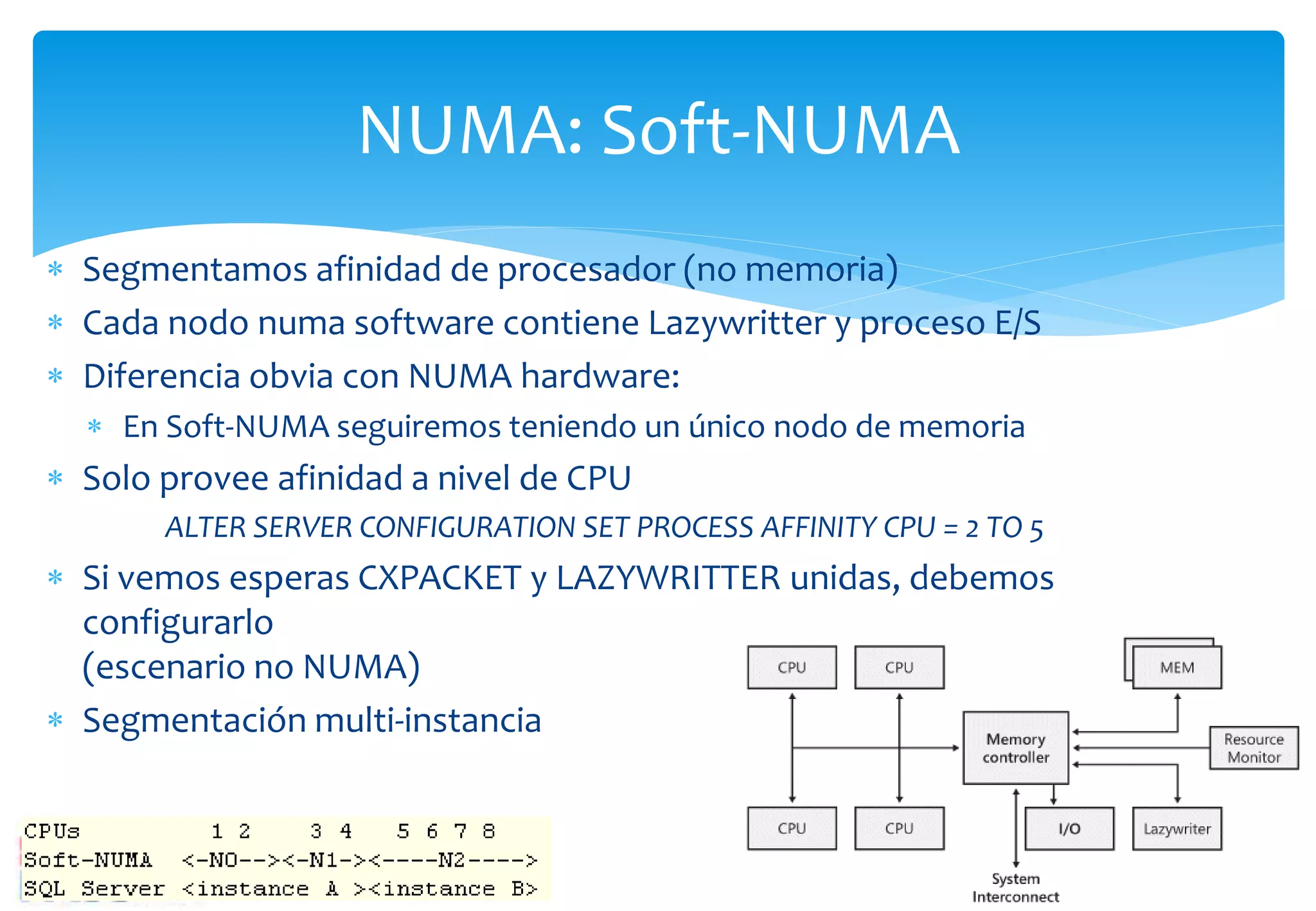
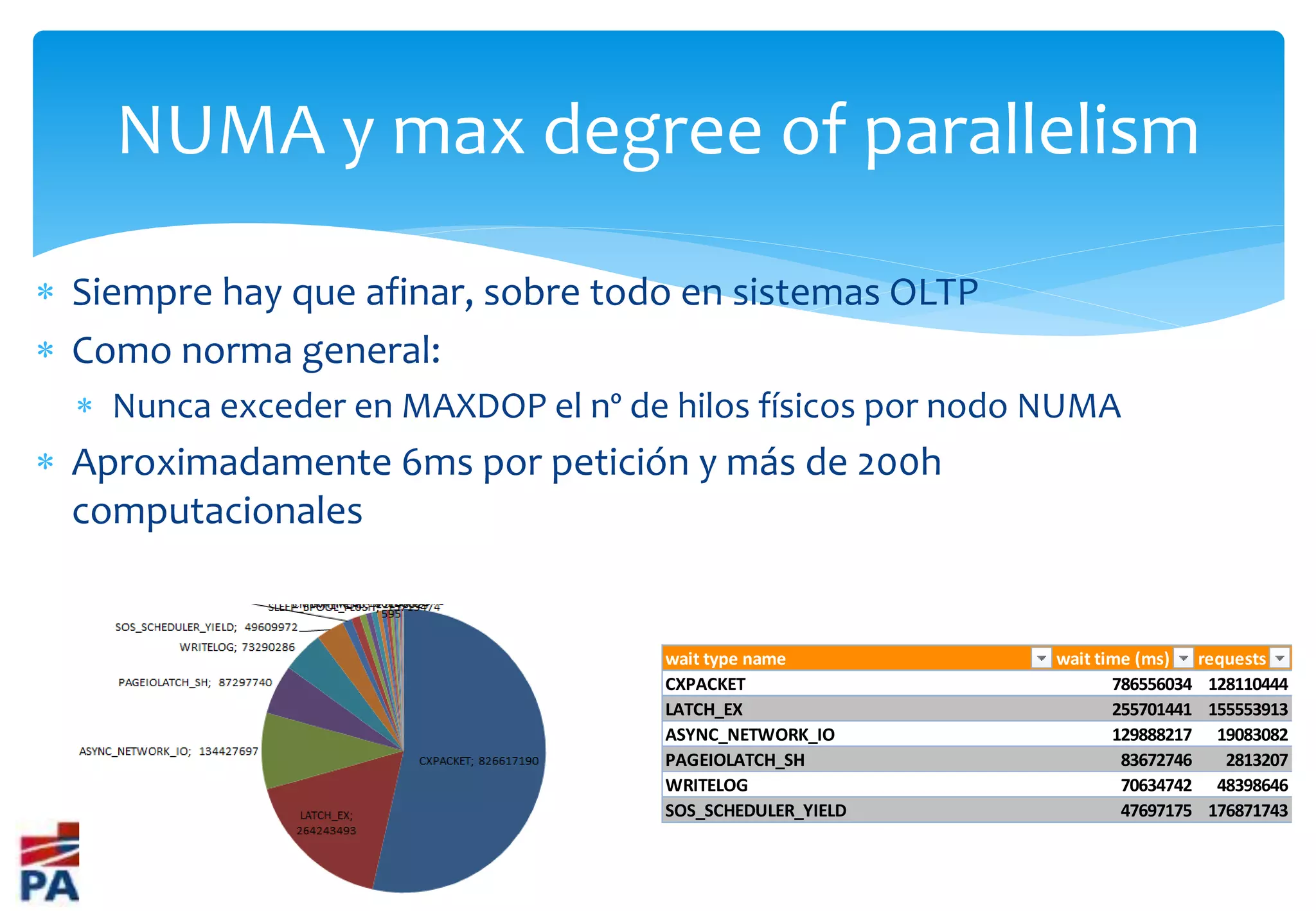
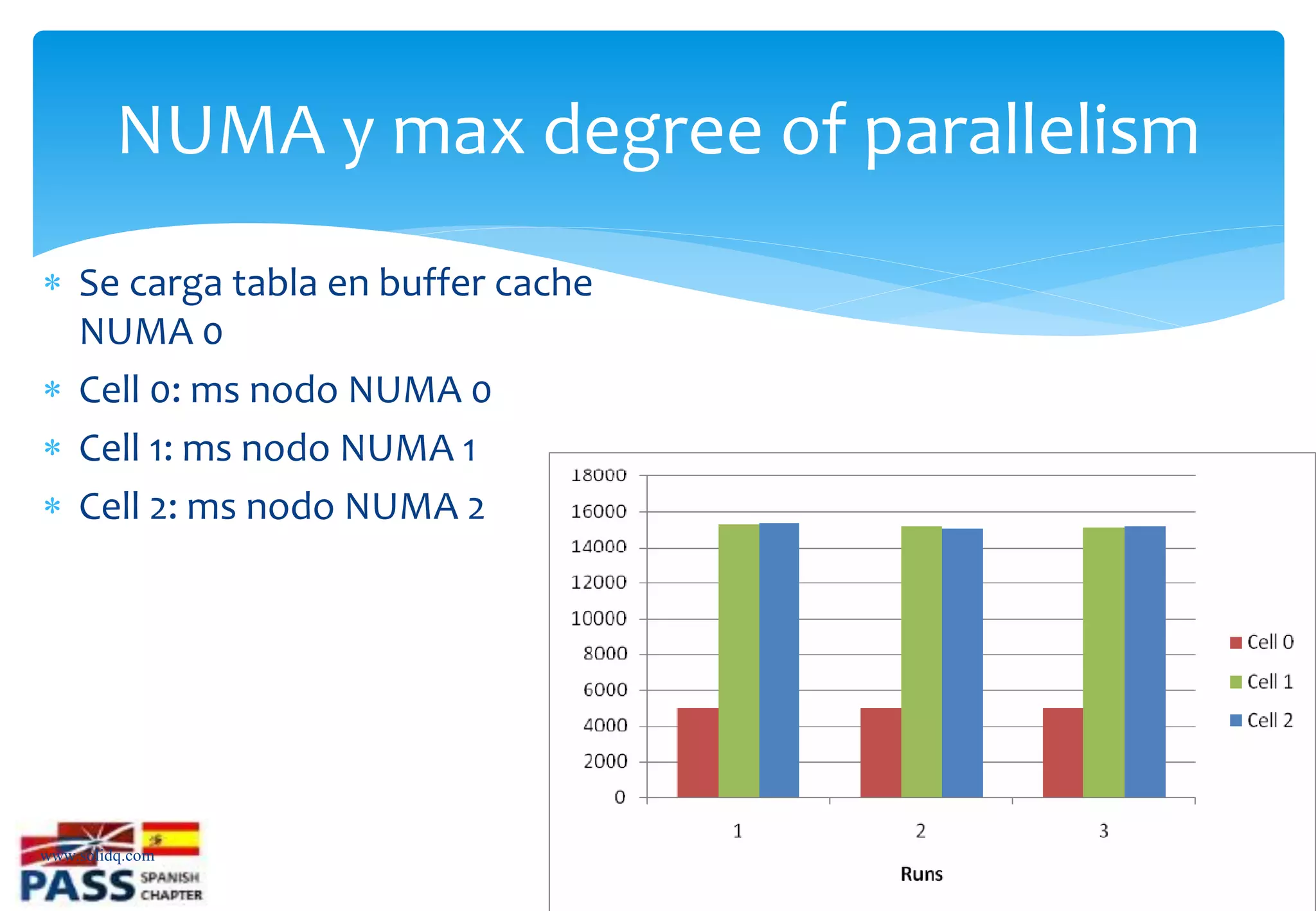
Introducción a NUMA, su configuración y beneficios para la escalabilidad y reducción de latencia.
Explicación del scheduler en SQL Server, diferenciando entre hilos y fibras, y su impacto en el rendimiento.
Discusión sobre la optimización de operaciones E/S en SQL Server mediante la máscara de afinidad y su configuración.
Mejores prácticas para la configuración de la base de datos Tempdb, incluyendo la cantidad de archivos y su tamaño.
Análisis del log de transacciones, prácticas recomendadas para optimizar su rendimiento y almacenamiento.
Cómo utilizar la optimización de correlación de fechas para mejorar consultas en reporting y data warehousing.
Exploración de técnicas de parametrización para mejorar el rendimiento en consultas ad-hoc y su configuración.
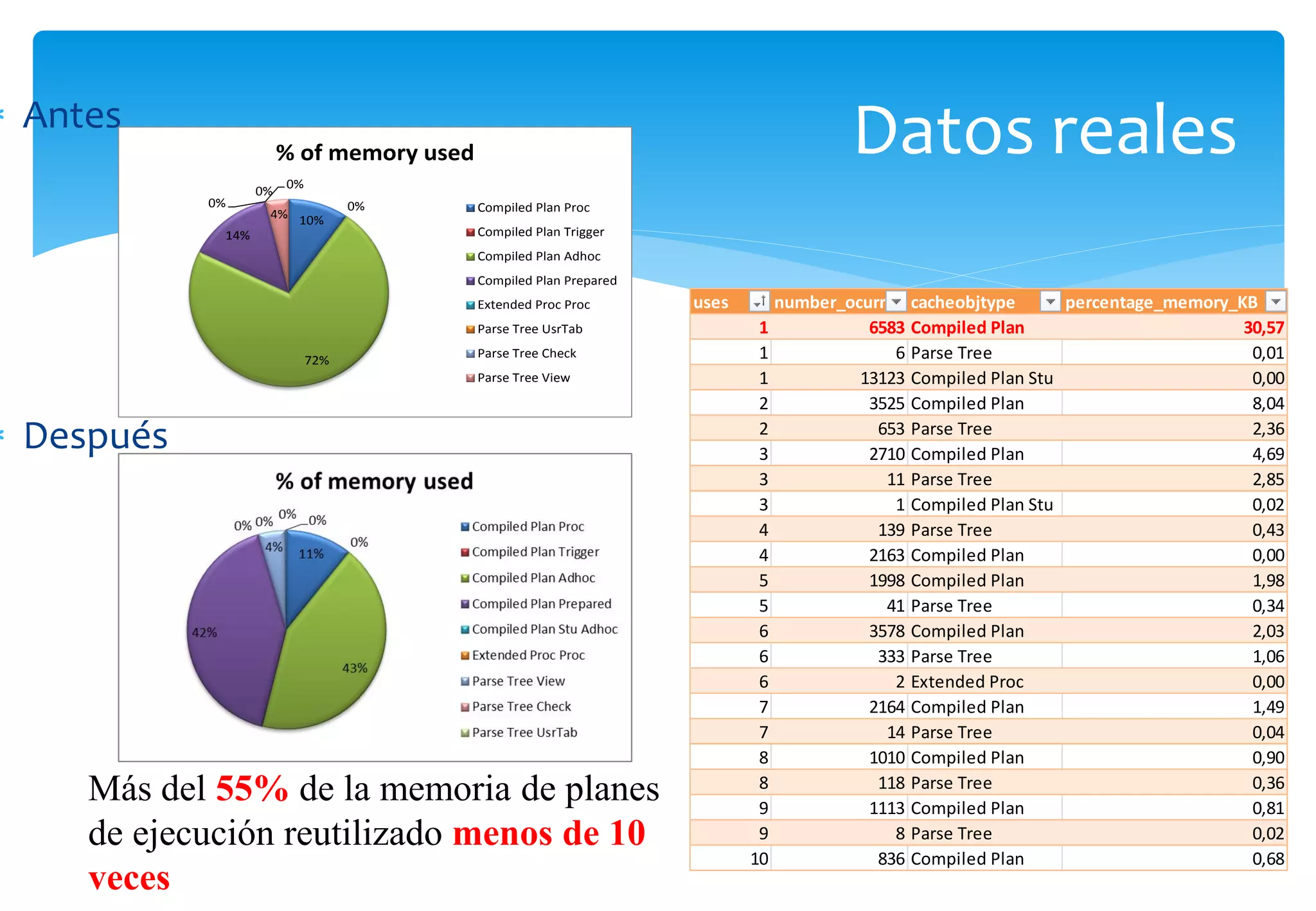
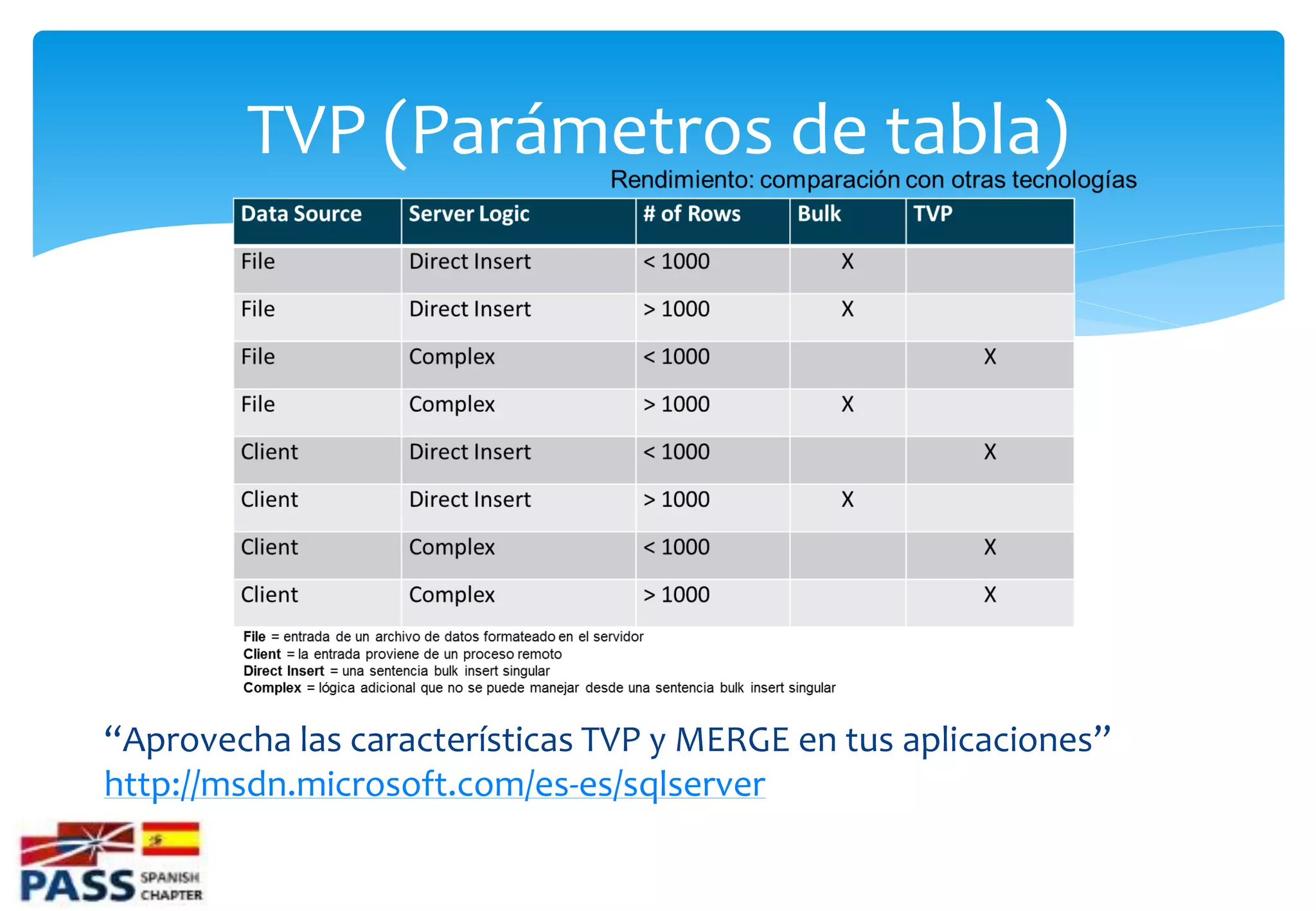
Uso de Parámetros de Tabla (TVP) y funciones en SQL Server, su desempeño y consideraciones para optimización.
Recapitulación de los temas tratados y espacio para preguntas y aclaraciones sobre SQL Server.































































































