Descargar para leer sin conexión





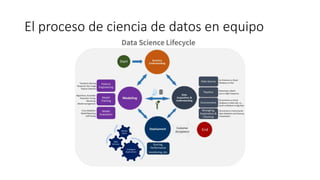












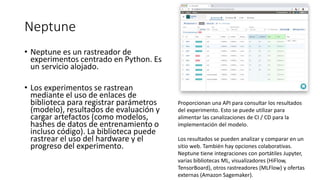





Este documento describe MLOps, que permite llevar modelos de machine learning a producción mediante la aplicación de prácticas de DevOps. Explica algunos problemas comunes en proyectos típicos de ML y cómo MLOps aborda esto a través de la automatización, reproducibilidad y validación. También presenta algunas herramientas populares como Neptune, MLFlow, Kubeflow y CML que pueden acelerar los procesos de MLOps.



































































